









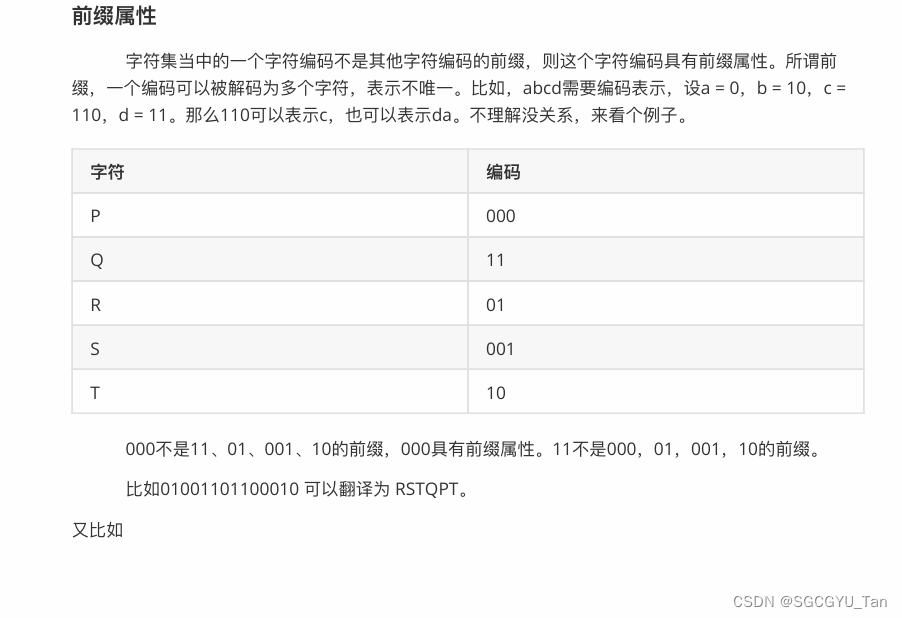
1.前导概念
1.定义:设有n个权值{w1,w2,…,wn},构造一棵有n个叶子 结点的二叉树,每个叶子的权值为wi,则wpl最小的二叉树叫哈夫曼树。
例子:
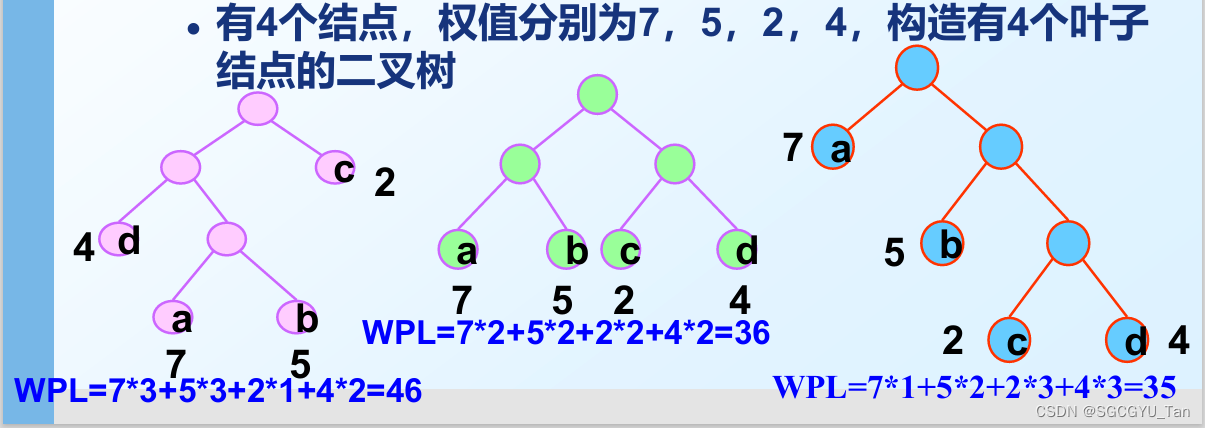
2.结点的路径长度:从根结点到该结点的路径上的连接数
3.树的路径长度:就是树的每个叶⼦结点的路径⻓度之和
4.结点的带权路径⻓度:结点的路径⻓度与结点权值的乘积。 ⽐如规定结点K的权重/权值为4,结点K的路径⻓度为3,那么带权路径⻓度就是3 * 4 = 12。
5.树的带权路径⻓度 WPL:就是树的所有叶⼦结点的带权路径⻓度之和。
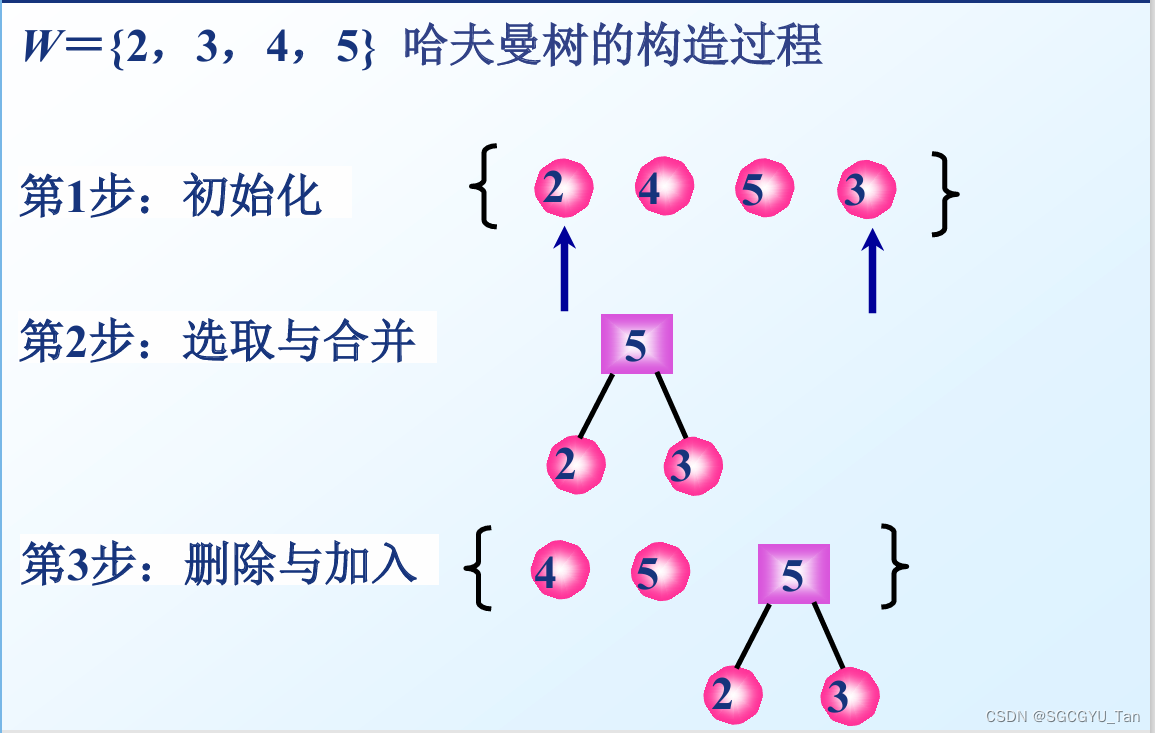
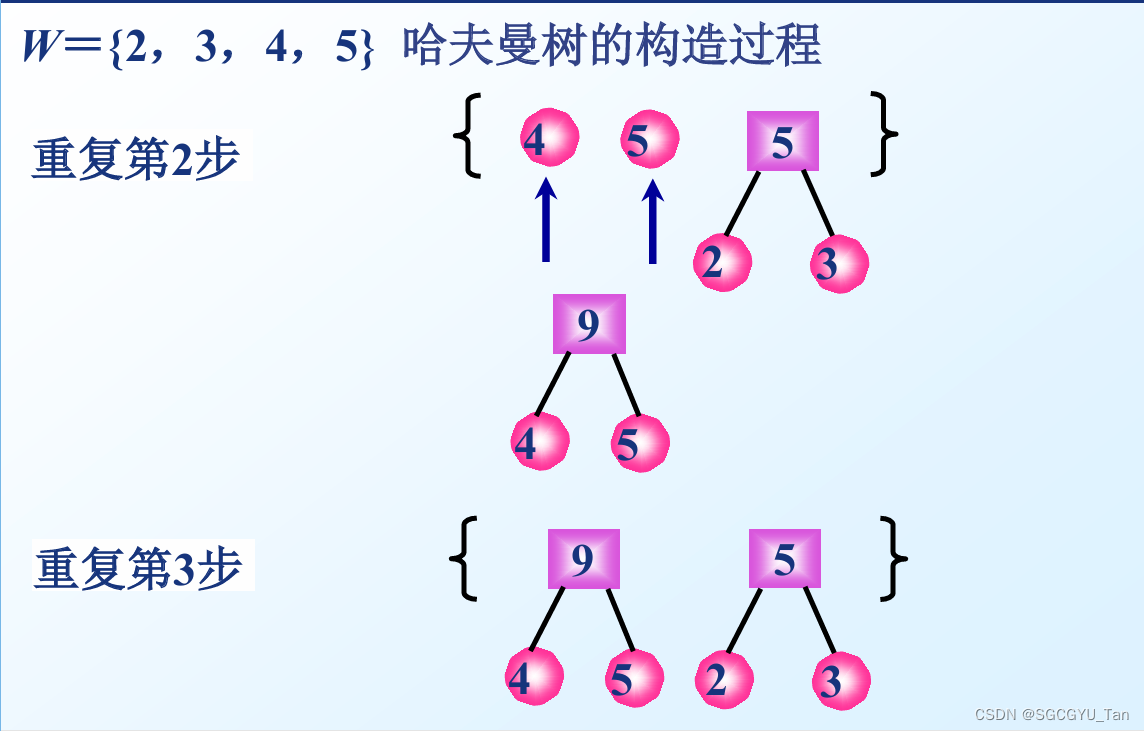
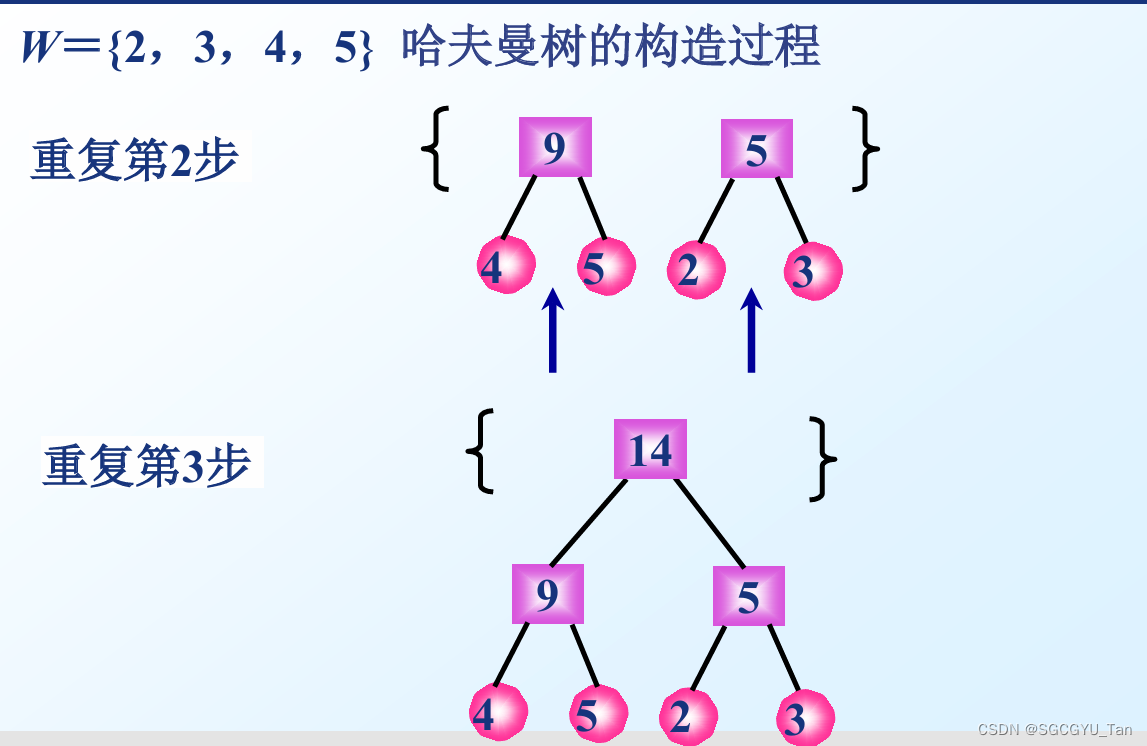
2.构造过程
(1) 初始化:根据给定的n个权值{w1,w2,…,wn},构成 n棵二叉树的集合F={T1,T2,…,Tn},其中每棵二叉树 Ti只有一个带权为wi的根结点,其左右子树均空。
(2) 选取与合并:在F中选取两棵根结点的权值最小的树作为左右子树,构造一棵新的二叉树,且置新的 二叉树的根结点的权值为其左、右子树上根结点的权 值之和。
(3) 删除与加入:在F中删除这两棵树,同时将新得到的二叉树加入F中。
(4) 重复(2)和(3),直到 F 只含一棵树为止。这棵树便 是所求的哈夫曼树。
3.哈夫曼编码
1.定⻓编码
像ASCII编码、Unicode编码。ASCII编码每⼀个字符使⽤8个bit,能够编码256个字符;Unicode 编码每个字符占16个bit,能够编码65536个字符,包含所有ASCII编码的字符。 假设我们要使⽤定⻓编码对由符号A,B,C,D和E构造的消息进⾏编码,对每个字符编码需要多 少位呢? ⾄少需要3位,2个bit位不够表示五个字符,只能表示4个字符。 如果对DEAACAAAAABA进⾏编码呢?总共12个字符,每个字符需要3bit,总共需要36位。
2.定⻓编码的缺陷
浪费空间!对于仅包含ASCII字符的纯⽂本消息,Unicode使⽤的空间是ASCII的两倍,两种⽅式 都会造成空间浪费;字符“ a”和“ e”的出现频率⽐“ q”和“ z”的出现频率⾼,但是他们都占⽤了相同位数的 空间。要解决定⻓编码的缺陷,便有了下⾯的变⻓编码。
3.变⻓编码
单个编码的⻓度不⼀样,可以根据整体出现的频率来调节,出现的频率越⾼,编码⻓度越短。 变⻓编码优于定⻓编码的是,变⻓编码可以将短编码赋予平均出现频率较⾼的字符,同⼀消息的 编码⻓度⼩于定⻓编码。 这个时候⼜有⼀个问题,字符有⻓有短,我们怎么知道⼀个字符从哪⾥开始,⼜从哪⾥结束呢? 如果位数固定,就没这个问题了。
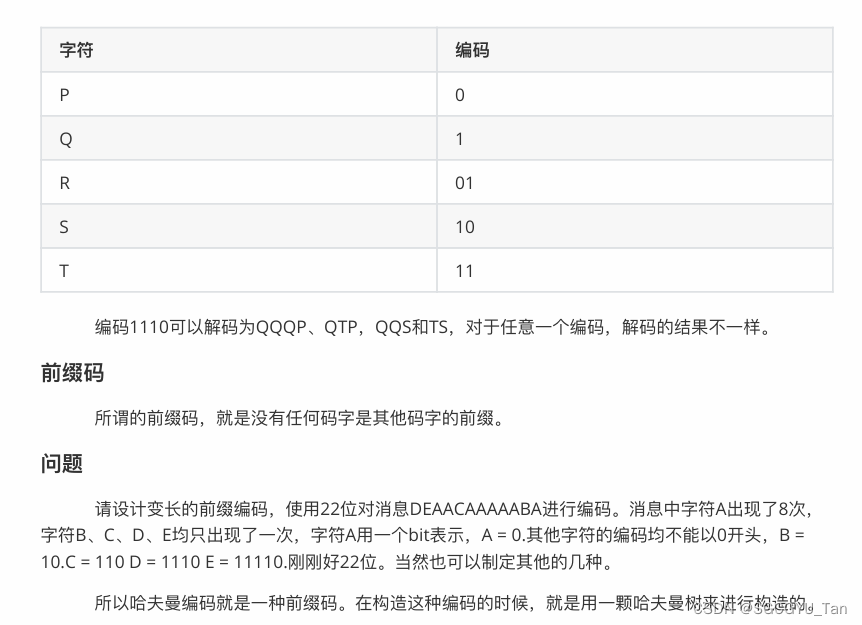
4.哈夫曼编码的代码实现
#include <iostream>
using namespace std;
#include <cstring>
#define MAX 100
/*
结点的路径长度是高度减一
树的路径长度:该树中所有结点的路径长度之和
其中分为 外部路径长度:该树中所有叶子结点的路径长度之和
内部路径长度:该树中所有叶子结点的内部结点路径长度之和
权值:每个结点自己带的数据
结点加上权值,结点的带权路径长度:该结点的路径长度*该结点的权值
树的带权路径长度(WPL):该树中所有叶子结点的带权路径长度之和
哈夫曼树:
给出n个带权值的结点,使用这n个结点做叶子结点构建二叉树,可以构建出很多种不同的树,其中带权路劲长度最小的树,成为哈夫曼树(最优二叉树)
最少需要添加n-1个结点 (度为2的结点个数),
WPL:(叶子结点的带权路径长度*权值)之和
n棵只有根结点的树
1.选出根结点权值最小的两棵树
2.给这两棵树的根结点加一个新的父亲结点(权值是其孩子结点的权值之和),组成新树,树的数目-1
3.循环以上过程,直到只有一棵树
应用:哈夫曼编码, 信息压缩
*/
//数组模拟存树
typedef struct HuffmanNode
{
int weight;//权值
int lchild, rchild;
int parent;
}HuffmanNode,*HuffmanTree;
//找权值最小的两个结点
void findNode(HuffmanTree tree, int n, int *s1, int *s2)
{
int minn = 0;
//先找一棵没有父亲的树
for (int i = 1; i <= n; i++)
{
if (tree[i].parent == i)
{
minn = i;
break;
}
}
for (int i = 1; i <= n; i++)
{
if (tree[i].parent == i && tree[i].weight < tree[minn].weight)
{
minn = i;
}
}//找到权值最小的结点
*s1 = minn;
for (int i = 1; i <= n; i++)
{
if (tree[i].parent == i && i != *s1)
{
minn = i;
break;
}
}
for (int i = 1; i <= n; i++)
{
if (tree[i].parent == i && tree[i].weight < tree[minn].weight && i != *s1)
{
minn = i;
}
}//找到权值第二小的结点
*s2 = minn;
return;
}
HuffmanTree creat_Huff(int w[], int n)
{
int m = 2 * n;
//应该开n+n-1 但是0下标我们不用 所以开2n
HuffmanTree tree = new HuffmanNode[m];//tree是数组
//初始化
for (int i = 1; i < m; i++)
{
tree[i].lchild = tree[i].rchild = 0;//我们没用0,可以设为0
tree[i].weight = 0;
}
for (int i = 1; i <= n; i++)
{
tree[i].weight = w[i-1];
tree[i].parent = i;
}
int s1, s2;//权值最小的两个根结点的下标
for (int i = n + 1; i < m; i++)
{
findNode(tree,i-1,&s1,&s2);//i-1代表原来手里面已存在的结点
tree[i].weight = tree[s1].weight + tree[s2].weight;//新结点的权值
tree[i].lchild = s1;
tree[i].rchild = s2;
tree[i].parent = i;
tree[s1].parent = tree[s2].parent = i;
}
return tree;
}
char ** creat_code(HuffmanTree tree, int n)//自下而上添加编码
{
char *temp = new char[n];//实际编码个数只需要n-1个位置
char ** codes = new char*[n];//指针模拟开二维数组
memset(codes, 0, sizeof(char*)*n);//将数组全部赋值为0
//编码
int start, p, fa;
for (int i = 1; i <= n; i++)
{
start = n - 1;//数组的最后一位下标是n-1
temp[start] = '\0';//字符串结尾要加这个
p = i;//循环代表最开始的几个树(最开始的几个结点拥有编码)
fa = tree[p].parent;
while (tree[p].parent != p)
{
start--;
if (p == tree[fa].lchild)
{
temp[start] = '0';
}
else
{
temp[start] = '1';
}
p = fa;
fa = tree[p].parent;
}
codes[i - 1] = new char[n - start];
memcpy(codes[i - 1], &temp[start], n - start);
}
delete[] temp;
temp = NULL;
return codes;
}
int main()
{
int w[8] = { 5,29,7,8,14,23,3,11 };
char show[8] = { 'A','B','C','D','E','F','G','H' };
HuffmanTree tree = creat_Huff(w, 8);//一个参数是权,另一个参数是结点个数
char ** code = creat_code(tree, 8);
for (int i = 0; i < 8; i++)
{
cout << show[i] << " " << code[i] << endl;
}
system("pause");
return 0;
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









