






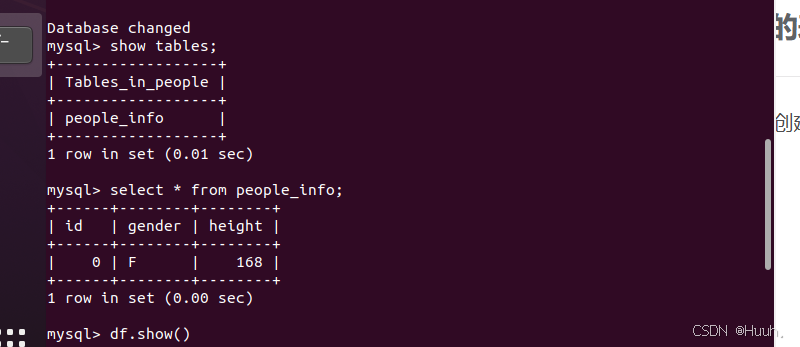
先在MySQL创建表格(随便创建一个)
pyspark中的文件创建和改动
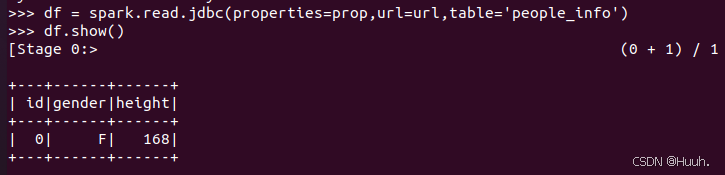
(1)连接MySQL
>>>prop = {'user':'root','password':'123456','driver':'com.mysql.cj.jdbc.Driver'}
>>> url = 'jdbc:mysql://localhost:3306/people'

(2)csv文件读取数据创建df
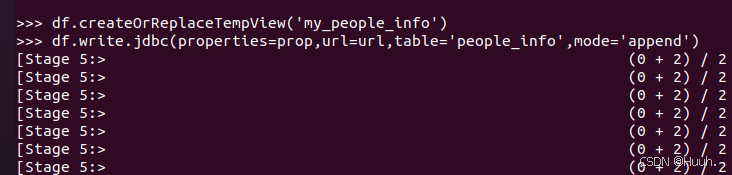
(3)csv写入数据(先备份)
>>>df.write.jdbc(properties=prop,url=url,table='people_info',mode='append')
>>>df = spark.read.csv('file:///home/spark/mydata/people_info.csv',schema='id long,gender string,height int')
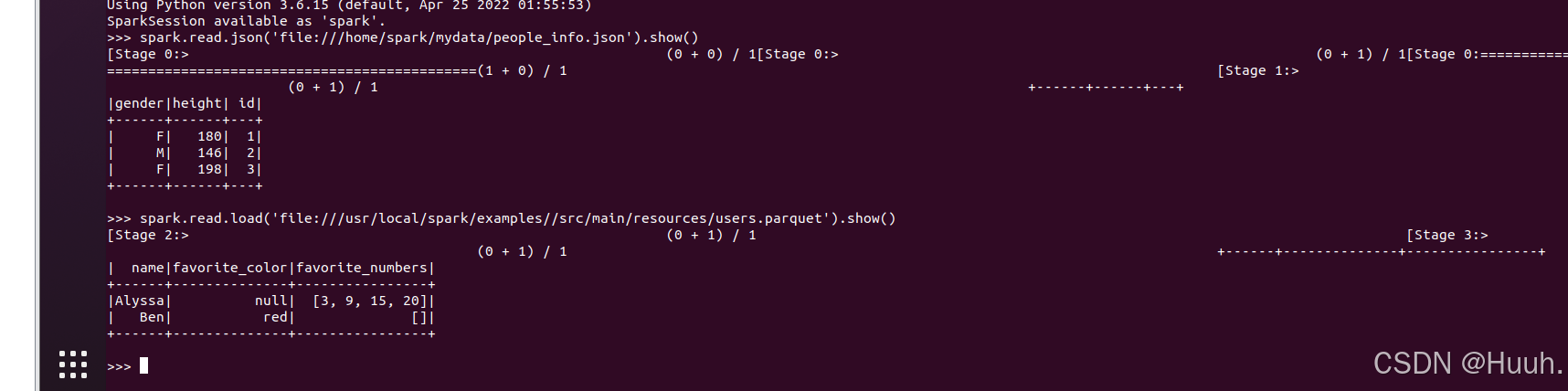
(4)json文件的创建
>>> spark.read.json('file:///home/spark/mydata/people_info.json').show()
>>>spark.read.load('file:///usr/local/spark/examples//src/main/resources/users.parquet').show()
数据查询
(1)筛选
>>> df.where('age>=10 and score>80').show()
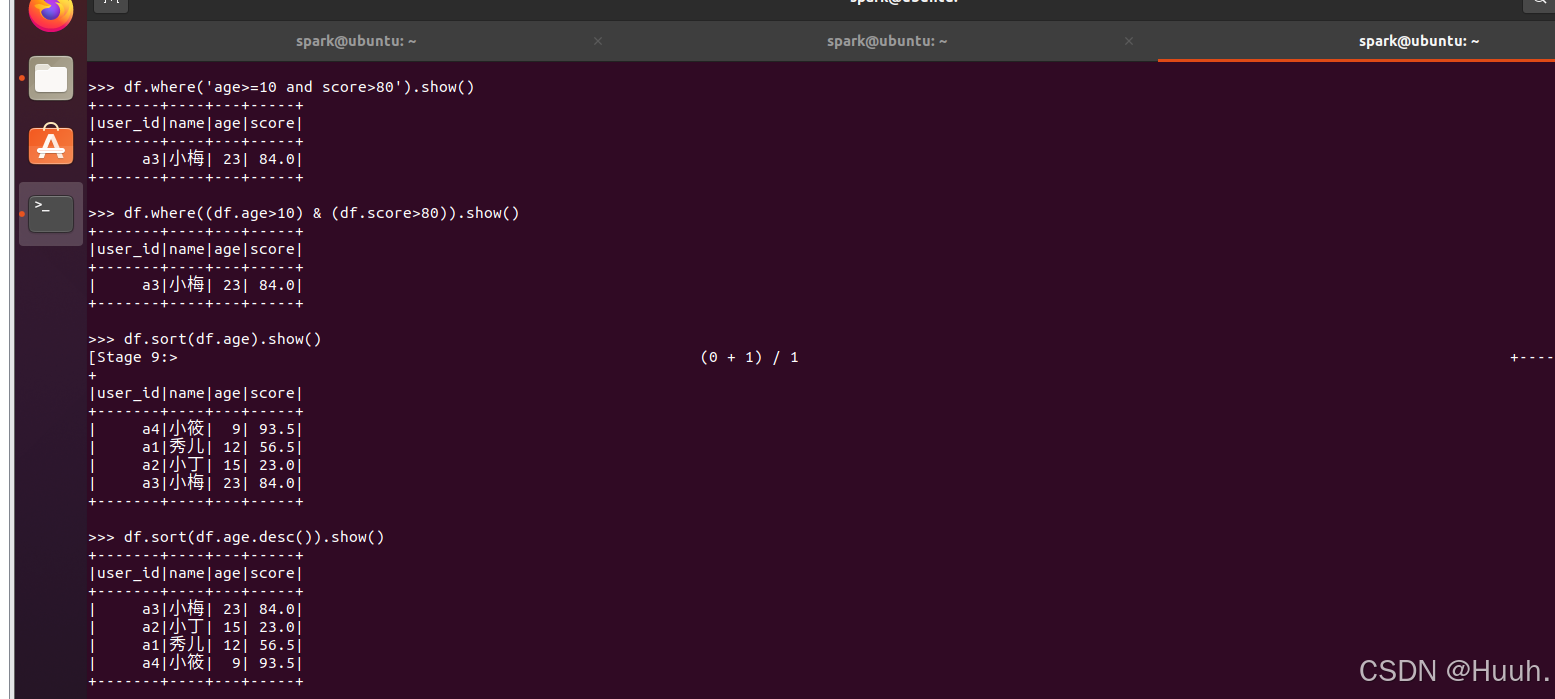
>>> df.where((df.age>10) & (df.score>80)).show()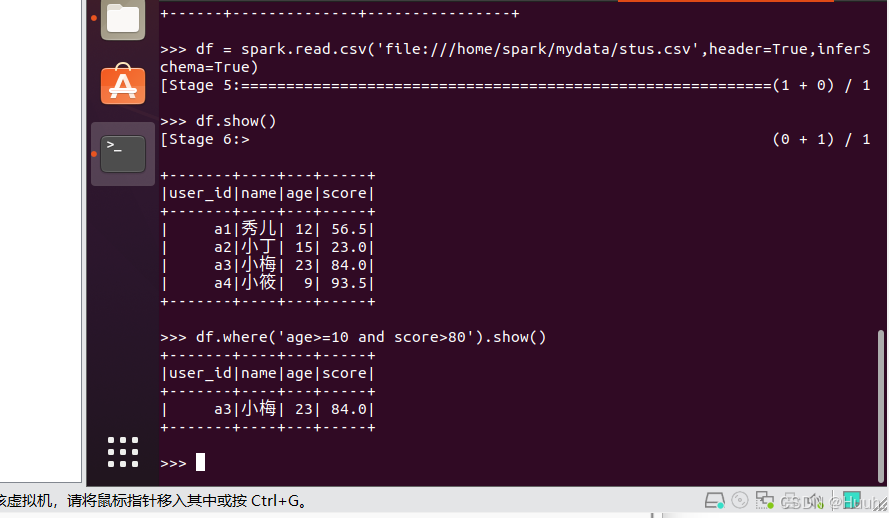
(2)排序
>>> df.sort(df.age).show()
>>> df.sort(df.age.desc()).show()
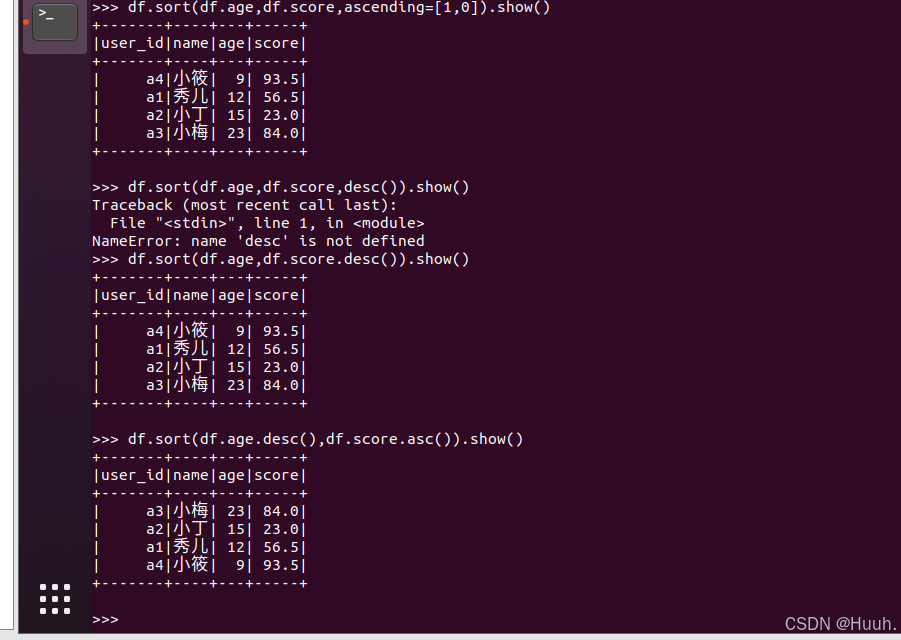
>>> df.sort(df.age,df.score,ascending=[1,0]).show()
>>> df.sort(df.age,df.score.desc()).show()
>>> df.sort(df.age.desc(),df.score.asc()).show()
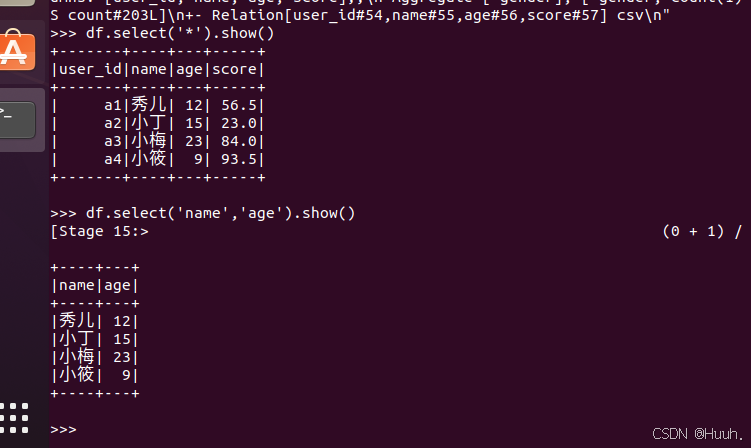
(3)查询

















 512
512

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









