






目录
1.Spark RDD常用操作(Common operations in Spark RDD)
2.从集合元素创建RDD(Create RDD from collections)
3.从文本文件创建RDD(Create RDD from text file)
4.map转换数据(Transform data with map)
1.Spark RDD常用操作(Common operations in Spark RDD)
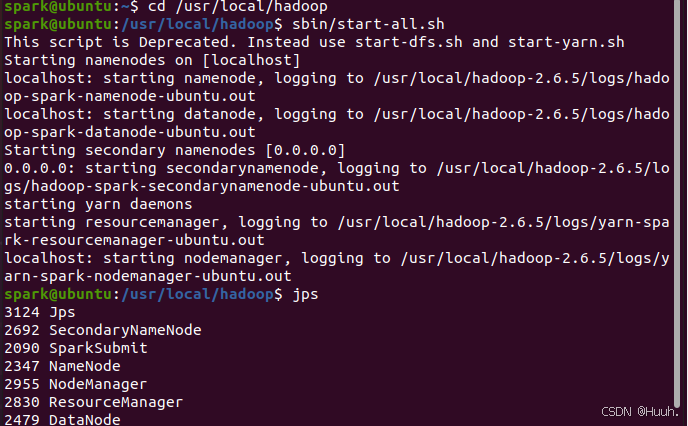
先开一下Hadoop集群
spark@ubuntu:~$ cd /usr/local/hadoop
spark@ubuntu:/usr/local/hadoop$ sbin/start-all.sh
jps
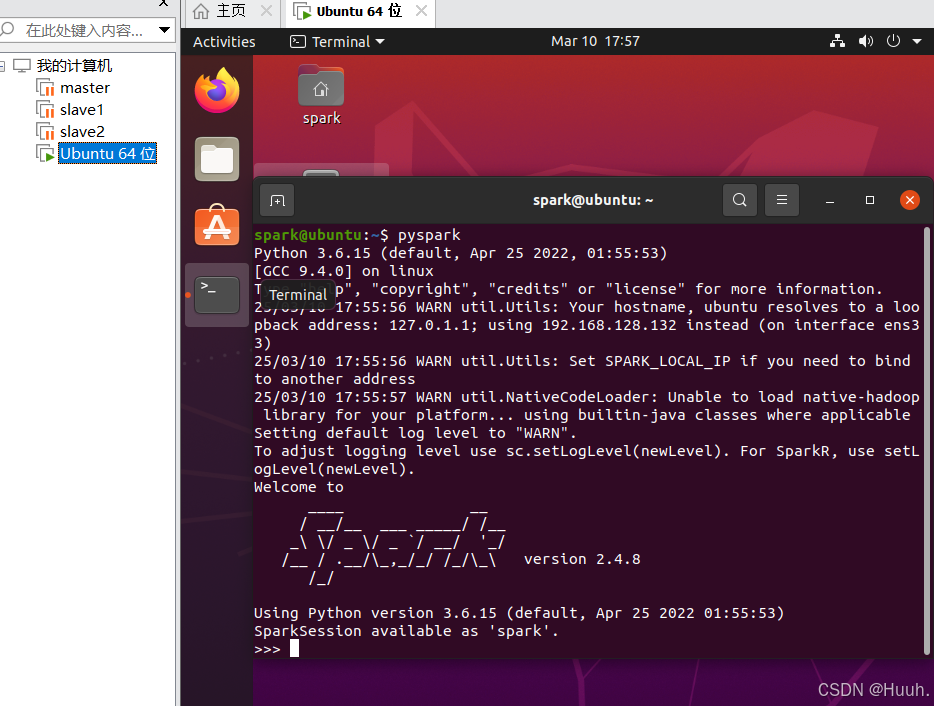
1)可以打开一个Linux终端窗体,在其中输入下面的命令启动PySparkShell交互式编程环境
pyspark
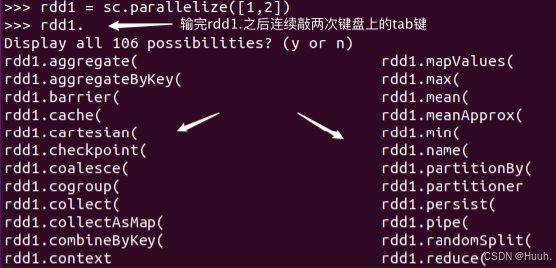
2)在其中输入下面的代码,可以查看RDD类包含的功能方法(在Spark中有一个专门的术语,称为 “算子”):
2.从集合元素创建RDD(Create RDD from collections)
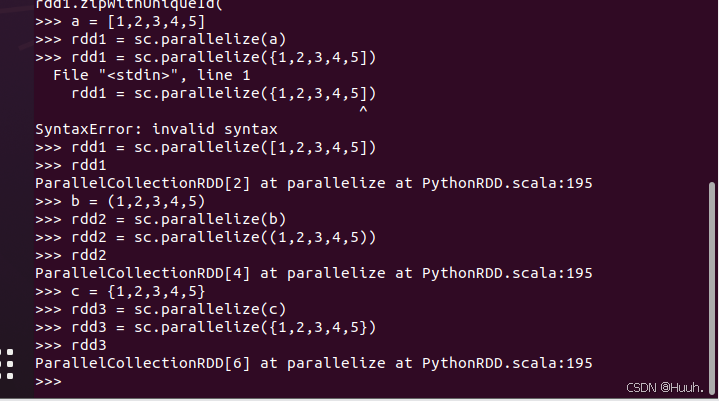
1)使用parallelize()方法从普通集合元素创建RDD。(向上的箭头可以输入上一步) >>> a = [1,2,3,4,5] >>> rdd1 = sc.parallelize(a) >>> rdd1 = sc.parallelize([1,2,3,4,5]) >>> rdd1 ParallelCollectionRDD[2] at parallelize at PythonRDD.scala:195
2)在parallelize()方法中设定一下分区参数
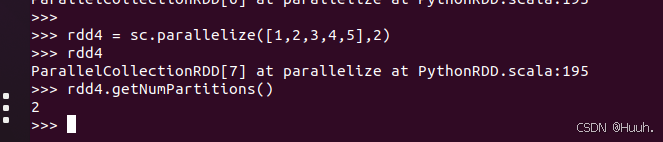
3.从文本文件创建RDD(Create RDD from text file)
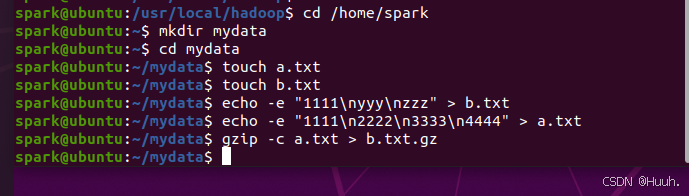
1)先准备两个文本文件,分别存放在本地磁盘目录和HDFS中(可以新开一个终端或者ctrl+D)
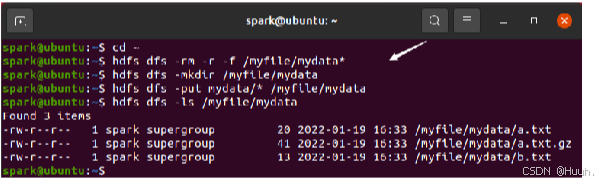
2)将数据文件上传至HDFS中
报错的话可以先创建/myfile再创建/myfile/mydata
hdfs dfs -mkdir /myfile
hdfs dfs -mkdir /myfile/mydata
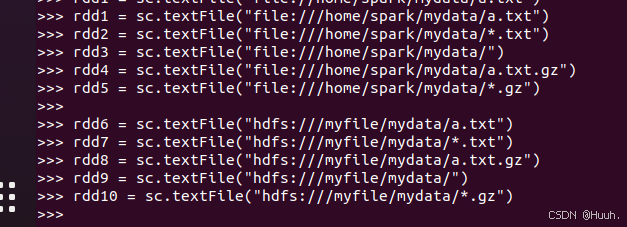
3)从数据文件创建对应的RDD数据集
rdd1 = sc.textFile("file:///home/spark/mydata/a.txt")
>>> rdd2 = sc.textFile("file:///home/spark/mydata/*.txt")
>>> rdd3 = sc.textFile("file:///home/spark/mydata/")
>>> rdd4 = sc.textFile("file:///home/spark/mydata/a.txt.gz")
>>> rdd5 = sc.textFile("file:///home/spark/mydata/*.gz")
>>>
>>> rdd6 = sc.textFile("hdfs:///myfile/mydata/a.txt")
>>> rdd7 = sc.textFile("hdfs:///myfile/mydata/*.txt")
>>> rdd8 = sc.textFile("hdfs:///myfile/mydata/a.txt.gz")
>>> rdd9 = sc.textFile("hdfs:///myfile/mydata/")
>>> rdd10 = sc.textFile("hdfs:///myfile/mydata/*.gz")
4)查看一下所创建的RDD数据集的具体内容(可以每个都看一下改一下标红数字就好了)
rdd1.collect()
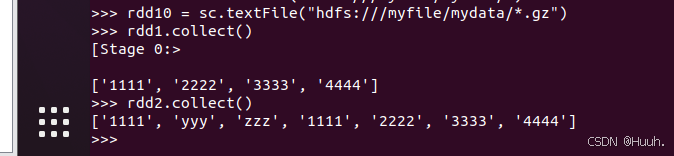
4.map转换数据(Transform data with map)
1)在PySpark编程环境中输入以下的代码
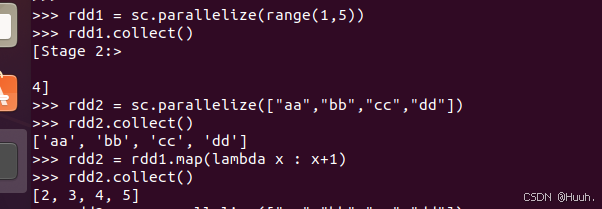
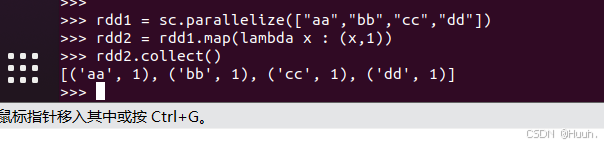
2)可以根据需要定义各种变换操作
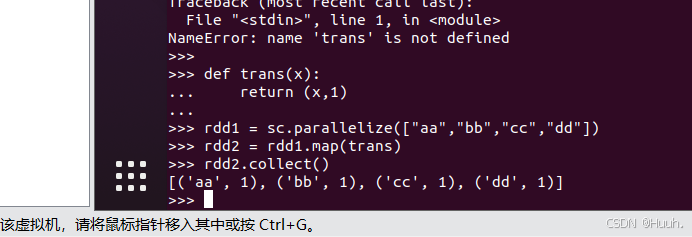
3)对原始RDD元素进行较复杂处理的话,应该定义一个显式的处理函数
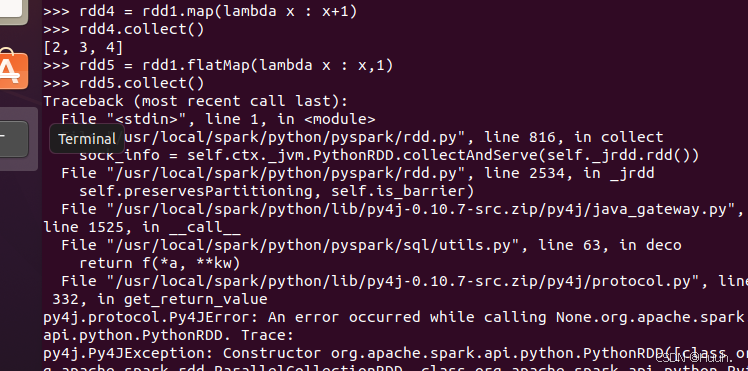
4)map()方法可以反复多次使用,从而得到一系列的新RDD数据集
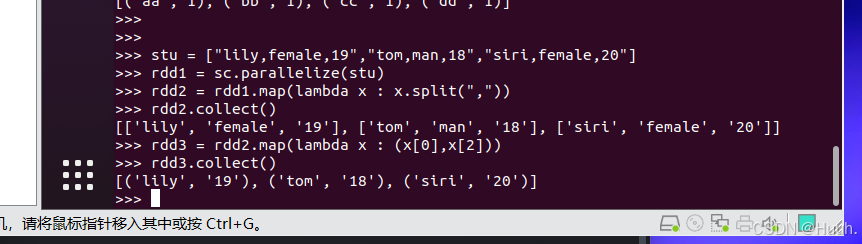
5.flatMap转换数据(Transform data with flatMap)
1)在PySpark编程环境中输入以下的代码
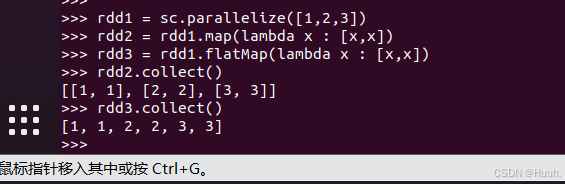
2)再接着输入下面的代码执行,分析一下出现的结果
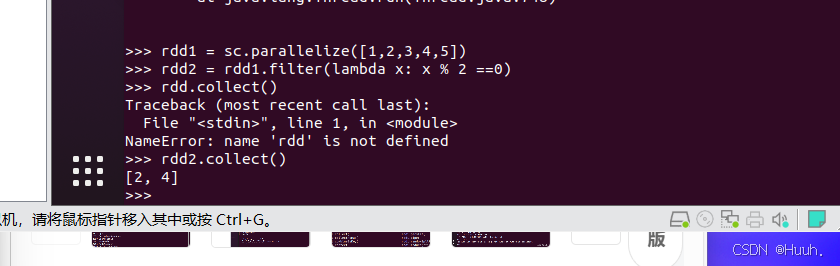
6.filter筛选数据(Filter data with filter)
1)在PySpark编程环境中输入以下的代码
7.sortBy排序数据(Sort data with sortBy)
1)下面是一个简单的sortBy()的例子
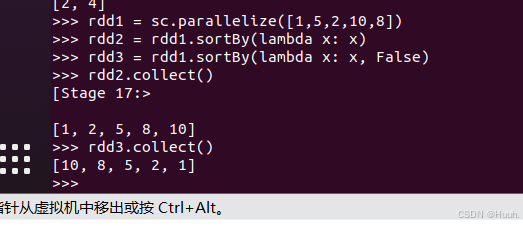
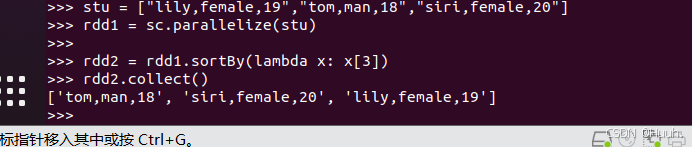
2)定义一个更为通用的sortBy()例子代码


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









