一、聚合请求构建
1. 核心工具类
SearchRequest:构建搜索请求对象AggregationBuilders:提供各类聚合的静态方法
2. 聚合三要素
| 要素 | 描述 | 代码示例 |
|---|
| 聚合名称 | 自定义标识符 | "brand_agg" |
| 聚合类型 | 如terms/stats等 | AggregationBuilders.terms() |
| 聚合字段 | 需为keyword/数值/日期类型 | "brand.keyword" |
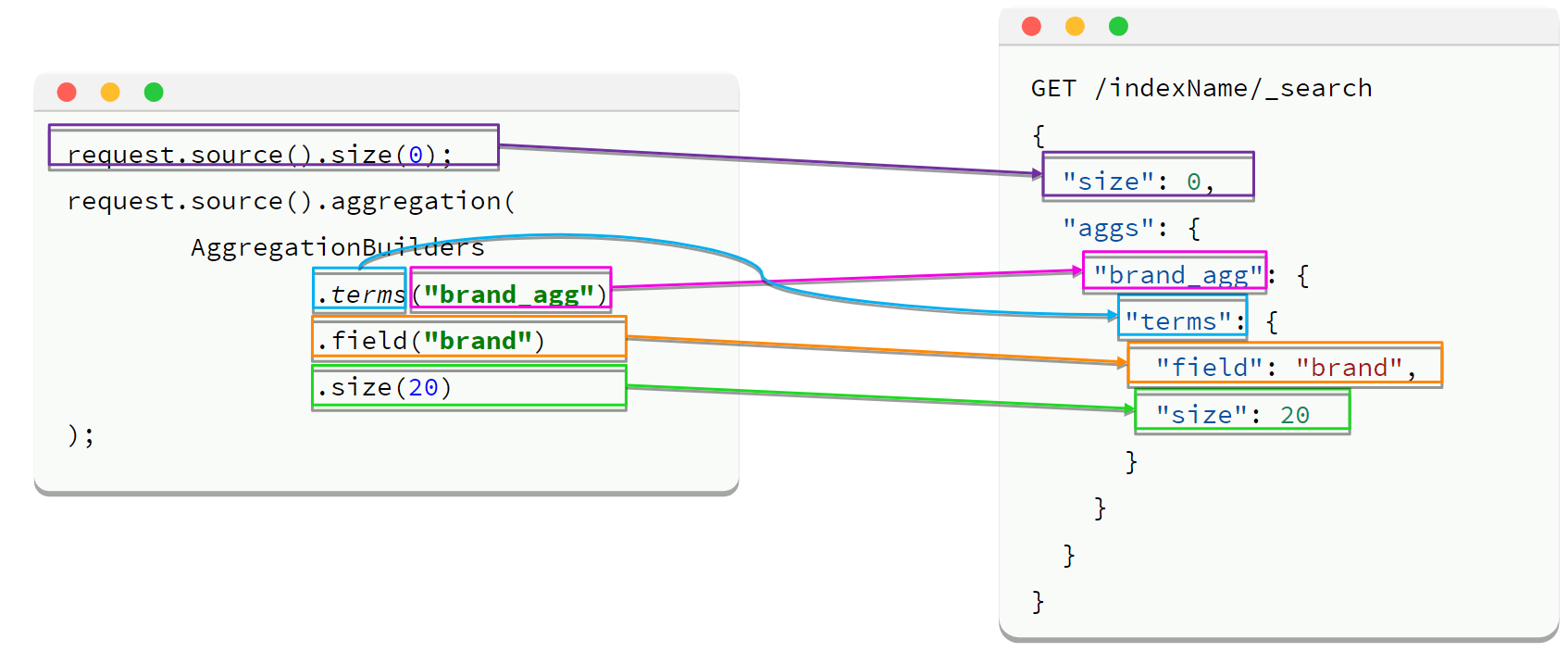
3. 基础桶聚合示例
SearchRequest request = new SearchRequest("items");
request.source()
.size(0)
.aggregation(
AggregationBuilders.terms("brand_agg")
.field("brand")
.size(20)
);
二、聚合结果解析
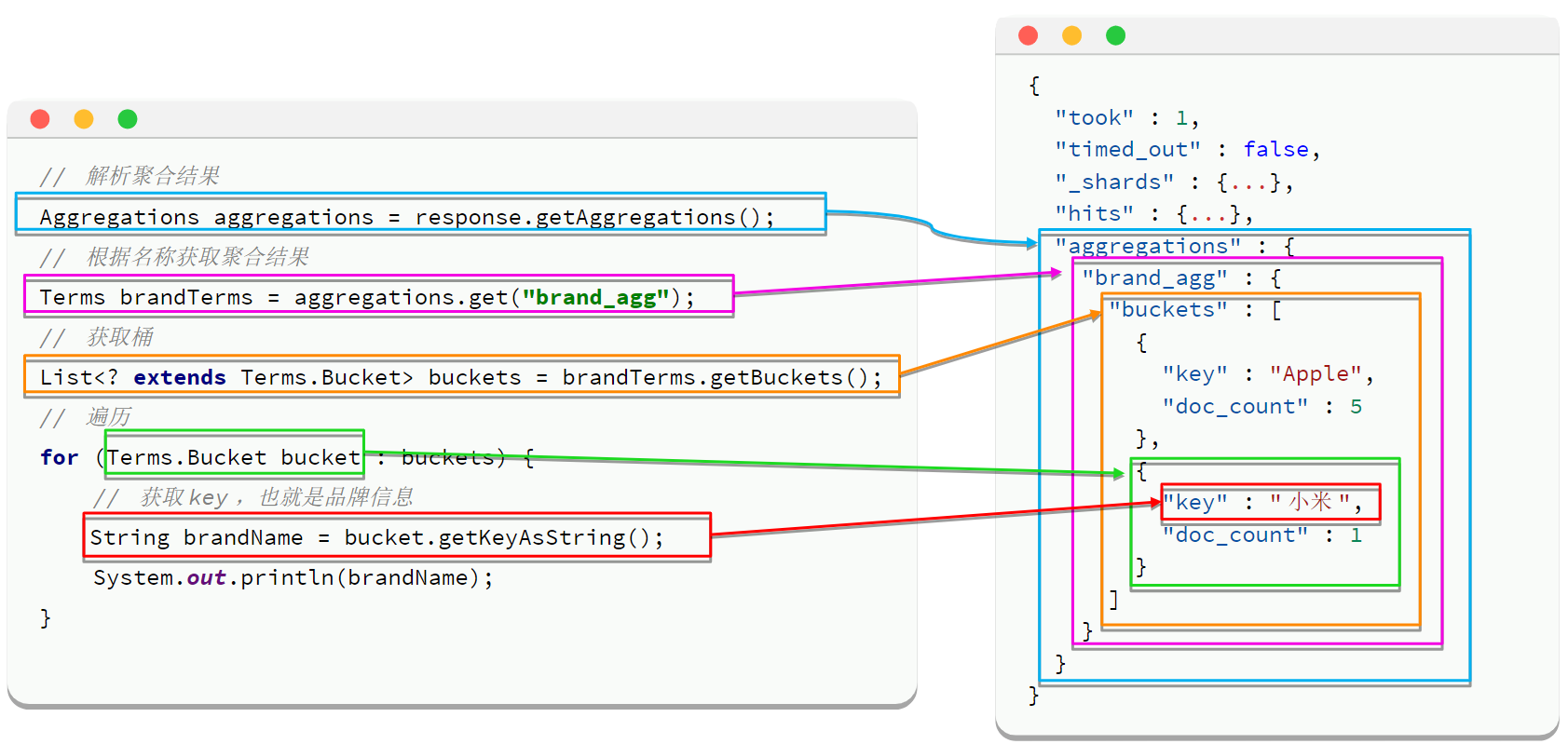
1. 解析流程
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
Aggregations aggregations = response.getAggregations();
Terms brandTerms = aggregations.get("brand_agg");
List<? extends Terms.Bucket> buckets = brandTerms.getBuckets();
for (Terms.Bucket bucket : buckets) {
String brand = bucket.getKeyAsString();
long docCount = bucket.getDocCount();
System.out.println(brand + ": " + docCount);
}
2. 关键API说明
response.getAggregations():获取所有聚合结果aggregations.get("聚合名称"):按名称获取具体聚合Terms.Bucket:代表单个分组结果,包含:
getKeyAsString():分组字段值getDocCount():组内文档数量
三、嵌套聚合示例(桶聚合+度量聚合)
1. 统计各品牌价格指标
SearchRequest request = new SearchRequest("items");
request.source()
.size(0)
.aggregation(
AggregationBuilders.terms("brand_agg")
.field("brand")
.subAggregation(
AggregationBuilders.stats("price_stats")
.field("price")
)
);
2. 解析嵌套结果
Terms brandTerms = aggregations.get("brand_agg");
for (Terms.Bucket bucket : brandTerms.getBuckets()) {
String brand = bucket.getKeyAsString();
Stats priceStats = bucket.getAggregations().get("price_stats");
System.out.println("品牌: " + brand);
System.out.println("平均价格: " + priceStats.getAvg());
System.out.println("最高价格: " + priceStats.getMax());
}
四、完整代码模板
@Test
void testAggregation() throws IOException {
SearchRequest request = new SearchRequest("index_name");
request.source()
.size(0)
.aggregation(
AggregationBuilders.terms("聚合名称")
.field("字段名.keyword")
.size(返回数量)
.subAggregation(
AggregationBuilders.avg("avg_price")
.field("price")
)
);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
Aggregations aggs = response.getAggregations();
Terms terms = aggs.get("聚合名称");
terms.getBuckets().forEach(bucket -> {
String key = bucket.getKeyAsString();
long count = bucket.getDocCount();
});
}
五、常见问题排查
1. 获取不到聚合结果
- 检查字段是否为keyword类型(需
.keyword后缀) - 确认聚合名称拼写一致
- 验证聚合字段是否存在映射
2. 类型转换异常
Stats stats = (Stats) aggregation;
Stats stats = aggregations.get("price_stats");
3. 性能优化
- 对高频聚合字段设置
fielddata: true - 限制返回桶数量(
.size(100)) - 避免在大文本字段上聚合
六、最佳实践建议
- 封装工具方法:将聚合解析逻辑封装成可复用方法
- 异常处理:添加空指针检查
if (aggregations != null) {
Terms terms = aggregations.get("brand_agg");
if (terms != null) {
}
}
- 结果格式化:将聚合结果转为DTO对象方便前端展示
List<BrandStatDTO> results = terms.getBuckets().stream()
.map(bucket -> new BrandStatDTO(
bucket.getKeyAsString(),
bucket.getDocCount()
))
.collect(Collectors.toList());
























 5632
5632

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









