






问题描述
将一个节点数为 size 链表 m 位置到 n 位置之间的区间反转,要求时间复杂度 O(n)O(n),空间复杂度 O(1)O(1)。
例如:
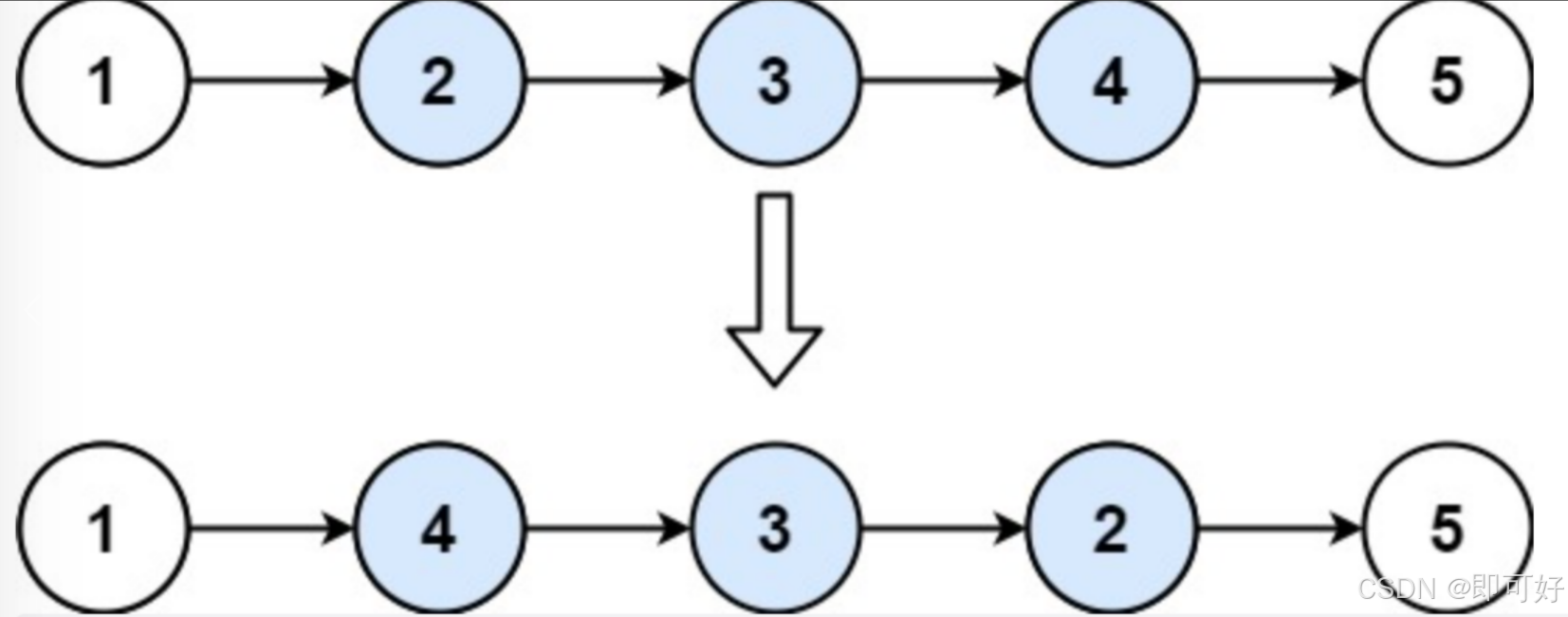
给出的链表为 1→2→3→4→5→NULL1→2→3→4→5→NULL, m=2,n=4m=2,n=4,
返回 1→4→3→2→5→NULL1→4→3→2→5→NULL.
数据范围: 链表长度 0<size≤10000<size≤1000,0<m≤n≤size0<m≤n≤size,链表中每个节点的值满足 ∣val∣≤1000∣val∣≤1000
要求:时间复杂度 O(n)O(n) ,空间复杂度 O(n)O(n)
进阶:时间复杂度 O(n)O(n),空间复杂度 O(1)O(1)
示例1
输入:
{1,2,3,4,5},2,4
返回值:
{1,4,3,2,5}
示例2
输入:
{5},1,1
返回值:
{5}
代码实现
ListNode* reverseBetween(ListNode* head, int m, int n) {
// write code here
if (!head || m == n) return head;
ListNode* hd = new ListNode(0);
hd -> next = head;
ListNode* pre = hd;
for(int i = 1; i < m; i++)
{
pre = pre -> next;
}
ListNode* curr = pre -> next;
ListNode* next = nullptr;
for(int i = m; i < n; i++)
{
next = curr->next;
curr->next = next->next;
next->next = pre->next;
pre->next = next;
}
return hd -> next;
}代码解析
1. 边界条件处理
if (!head || m == n) return head;如果链表为空或者 m == n(即不需要进行任何反转),直接返回原链表。
2. 虚拟头节点
ListNode* hd = new ListNode(0);
hd->next = head;由于链表可能从头节点开始反转,我们创建一个虚拟头节点 hd,将其 next 指向原链表的头节点 head。这可以简化头节点可能被修改时的处理。
3. 定位到第 m-1 个节点
ListNode* pre = hd;
for (int i = 1; i < m; i++)
{
pre = pre->next;
}通过 pre 指针将其指向第 m-1 个节点,这样在反转过程中,pre 的 next 就是需要反转部分的第一个节点。
4. 准备反转
ListNode* curr = pre->next;
ListNode* next = nullptr;curr 指向需要反转部分的第一个节点(即第 m 个节点),next 用来暂存 curr 的下一个节点。
5. 进行链表反转
for (int i = m; i < n; i++) {
next = curr->next; // 保存当前节点的下一个节点
curr->next = next->next; // 将 curr 的 next 指向 next 的下一个节点
next->next = pre->next; // 将 next 的 next 指向 pre 的 next(即 m 节点之前的部分)
pre->next = next; // 将 pre 的 next 指向 next(使得 next 成为当前反转部分的头节点)
}
-
这里的关键是通过三步操作实现了反转:
每次操作后,
next都会被移动到当前反转部分的最前面。- 将
curr的next指向next的下一个节点,断开当前节点和next的连接。 - 将
next的next指向反转区间之前的部分(即pre->next)。 - 将
pre->next指向next,更新反转区间的头部。6. 返回新的头节点
- 将
6. 返回新的头结点
return hd->next;
最后,返回虚拟头节点 hd 的 next 指针,指向新的链表头。
总结
reverseBetween 函数通过虚拟头节点、精确控制指针移动及反转的步骤,成功地反转了链表中的一段区间。通过简单的指针操作,避免了额外的空间开销,并且使代码结构清晰易懂。这种方法是链表操作中的经典技巧,能够有效地处理各种反转问题。

















 1398
1398

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









