







MapReduce 是一种用于大规模数据处理的编程模型和计算框架,最初由 Google 提出,后来由 Apache Hadoop 实现并广泛应用。它的核心思想是将数据处理任务分解为两个阶段:Map 和 Reduce,并通过分布式计算并行处理海量数据。
MapReduce 的核心思想
-
分而治之:
-
将大规模数据集分割成多个小块,分布到集群中的多个节点上并行处理。
-
-
Map 阶段:
-
将输入数据转换为键值对(Key-Value Pair),并生成中间结果。
-
-
Reduce 阶段:
-
对 Map 阶段的中间结果进行汇总和聚合,生成最终输出。
-
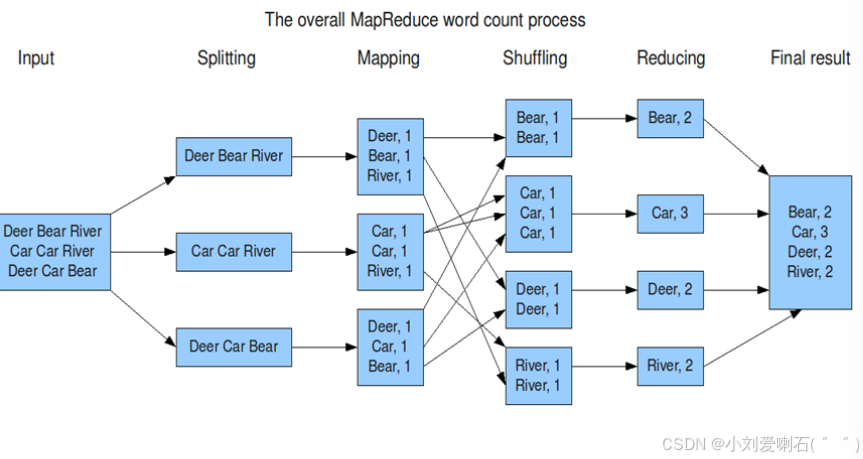
MapReduce 的工作流程
-
输入分片(Input Splits):
-
输入数据被分割成固定大小的分片(Split),每个分片由一个 Map 任务处理。
-
-
Map 阶段:
-
Map 任务读取输入分片,将其转换为键值对,并生成中间结果。
-
示例:统计单词频率时,Map 任务将每个单词映射为
<word, 1>。
-
-
Shuffle 和 Sort:
-
将 Map 任务的输出按键排序,并将相同键的数据发送到同一个 Reduce 任务。
-
-
Reduce 阶段:
-
Reduce 任务对中间结果进行汇总,生成最终输出。
-
示例:统计单词频率时,Reduce 任务将相同单词的计数相加,生成
<word, count>。
-
-
输出:
-
最终结果写入分布式文件系统(如 HDFS)。
-
MapReduce 的组件
-
JobTracker:
-
主节点,负责作业调度和任务监控。
-
分配 Map 和 Reduce 任务给 TaskTracker。
-
监控任务的执行状态,处理故障。
-
-
TaskTracker:
-
从节点,负责执行 Map 和 Reduce 任务。
-
向 JobTracker 汇报任务状态和进度。
-
-
Mapper:
-
实现 Map 阶段的逻辑,将输入数据转换为键值对。
-
-
Reducer:
-
实现 Reduce 阶段的逻辑,对中间结果进行汇总。
-
MapReduce 的优缺点
优点:
-
高扩展性:
-
支持大规模集群,能够处理 PB 级数据。
-
-
容错性:
-
自动处理节点故障,重新分配失败的任务。
-
-
简单易用:
-
提供高层抽象,用户只需实现 Map 和 Reduce 函数。
-
-
适合批处理:
-
适合处理离线大数据任务。
-
缺点:
-
高延迟:
-
不适合实时或低延迟的数据处理。
-
-
不适合迭代计算:
-
每次作业都需要读写磁盘,效率较低。
-
-
编程模型受限:
-
仅支持 Map 和 Reduce 两种操作,复杂任务需要多次作业。
-
MapReduce 的应用场景
-
日志分析:
-
分析大规模日志数据,如网站访问日志、服务器日志。
-
-
数据挖掘:
-
处理海量数据,提取有价值的信息。
-
-
搜索引擎:
-
构建倒排索引,支持全文检索。
-
-
机器学习:
-
分布式训练模型,如 PageRank、K-Means 聚类。
-
MapReduce 的示例
统计单词频率:
-
Map 阶段:
-
输入:文本文件。
-
输出:
<word, 1>键值对。
-
-
Reduce 阶段:
-
输入:
<word, [1, 1, ...]>。 -
输出:
<word, count>。
-


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









