






1.内存对齐规则:
在介绍结构体的内存存储方式前,我们先引入一段代码:
typedef struct
{
int n;
char c;
int m;
}s;
int main()
{
int ret = sizeof(s);
printf("%d ", ret);
return 0;
}在代码中我们定义了一个结构体类型s,并用sizeof(s)计算它所占的字节空间,按照常理来推断,我们应该会认为这段代码的结果是sizeof(int)+sizeof(char)+sizeof(int)=9。但结果真的如此吗?
如果我在vs2022中运行这段代码:
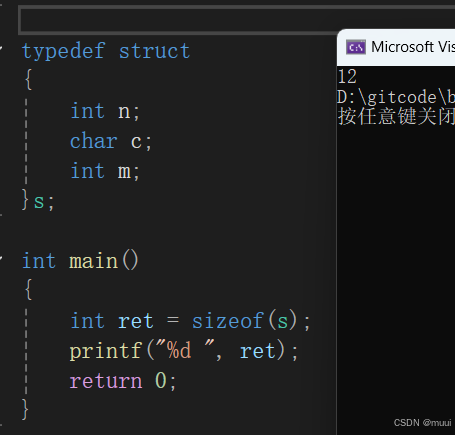
由此我们可以发现,结构体中的变量似乎并不像数组一样是在内存中连续存储的,那么,结构体的存储必然有独属于自己的规则:
1.结构体的第⼀个成员对⻬到和结构体变量起始位置偏移量为0的地址处
第一条规则很好理解,即结构体中定义的第一个变量在内存初始位置处开始存储。也就是说,变量的存储顺序依旧是遵循定义的顺序的,只是不连续了而已。
2.其他成员变量要对⻬到某个数字(对⻬数)的整数倍的地址处。 对⻬数=编译器默认的⼀个对⻬数与该成员变量⼤⼩的较⼩值。
在存储每一个新变量之前,要先找到它对齐数的整数倍处才开始存储,前面不符合要求的字节被跳过。
对齐数==编译环境提供的默认对齐数与该变量类型的字节大小进行比较后所取的较小值。
举个例子,如果我此时想要存储的变量类型为int,我的编译环境vs2022所提供的默认对齐数为8,而int的字节数为4,那么这时该变量的对齐数就是4。
而它的存储起始位置应该是4的倍数,例如4,8,12...
这时我们可以回头去看开头的那段代码中的结构体
typedef struct
{//为了方便理解,我们假设地址编号从0开始
int n; //从0号地址开始放置4个字节,(0~3)
char c;//char型对齐数为1,所有整数都是1的倍数,不跳过直接放1个字节,(4)
int m;//int型对齐数为4,只能从4的倍数的地址开始放,因此(5~7)被跳过,由8号地址开始向后放置4个字节(8~11)
}s;
//0~11,范围为12个字节提示:
-VS 中默认的值为 8
-Linux中gcc没有默认对⻬数,对⻬数就是成员⾃⾝的⼤⼩
3.结构体总⼤⼩为最⼤对⻬数(结构体中每个成员变量都有⼀个对⻬数,所有对⻬数中最⼤的)的 整数倍。
struct s
{
int a;
int b;
char c;
}学习了上面的规则,那么再来看这段代码,猜猜它的大小是否是9?
a(0~3)
b(4~7)
c(8)
实际上这样判断依然是错误的,原因就在于结构体内存存储的第三条规则。结构体总大小一定是所有变量的对齐数中最大一个的整数倍,也就是这段代码中最大对齐数持有者int的4个字节的倍数。
也就是说,实际存储应该这样理解:
a(0~3)
b(4~7)
c(8)
结尾空置:(9~11)
这样,就是12个字节没错了
4.如果嵌套了结构体的情况,嵌套的结构体成员对⻬到⾃⼰的成员中最⼤对⻬数的整数倍处,结构 体的整体⼤⼩就是所有最⼤对⻬数(含嵌套结构体中成员的对⻬数)的整数倍。
struct S2
{
double d;
char c;
int i;
};
printf("%d\n", sizeof(struct S2));// (0~7) -> (8) -> (12~15) 即答案为16个字节
struct S1
{
char c1;
struct S2 s;//此处嵌套了结构体s2
int d;
};
printf("%d\n", sizeof(struct S1));
既然我们已知,S2的内存大小为16,那么在S1中是否应该用它的内存大小16与默认对齐数8比较,最后取得较小值8为s的对齐数?又是一个易错点!因为规则四规定:嵌套的结构体成员对⻬到⾃⼰的成员中最⼤对⻬数的整数倍处,也就是说,依旧要回到S2中寻找所有成员中最大的对齐数。
那么,在S2中最大对齐数是double提供的8,也就是说,s的对齐数是8(此处恰巧与vs提供的默认对齐数相等),应该放在以8为倍数的起始地址上。
而根据规则的后半规则可知,我们不需要详细计算,也可以知道S1结构体的整体大小必然为8的倍数。
struct S2
{
double d;
char c;
int i;
};
struct S1
{
char c1; // (0)
struct S2 s;// (8~15)->(16)->(20~23)
int d; //(24~27)
//结尾空置:(28~31)
};输出结果:

2.为什么会有如此复杂的对齐规则?
1. 平台原因: 不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定 类型的数据,否则抛出硬件异常。
2. 性能原因:为了访问未对⻬的内存,处理器需要做两次内存访问;⽽对⻬的内存访问仅需要⼀次访问。假设⼀个处理器总是从内存中取8个字节,则地址必须是8的倍数。
如果我们能保证将所有的double类型的数据的地址都对⻬成8的倍数,那么就可以 ⽤⼀个内存操作来读或者写值了。否则,我们可能需要执⾏两次内存访问,因为对象可能被分放在两 个8字节内存块中。
可以总结为:结构体的内存对⻬是拿空间来换取时间的做法。
3.修改默认对齐数
#pragma pack(n)
该预处理指令可以协助我们将当前环境下的默认对齐数改为n
#pragma pack()
该预处理指令可为我们撤销之前自定义的默认对齐数,还原为系统自带
注:因为linux系统下不存在默认对齐数,因此无法用到这条指令

















 136
136

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









