







目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于深度学习的商品外包装检测系统
设计思路
一、课题背景与意义
药品的包装质量是药品卫生和药效的重要保障。目前三期信息打印的方式主要有喷墨、压印和激光打码等,以上方式均存在漏印或者错印等问题。因此研究机器视觉在药品包装质量检测方面的应用,并在经典图像处理算法的基础上引入基于深度学习的目标检测与光学字符识别算法,以解决目前对成品铝塑泡罩板缺粒与纸盒压印三期检识别果较差的问题,提高检测的准确率与速度
二、算法理论原理
2.1 目标检测
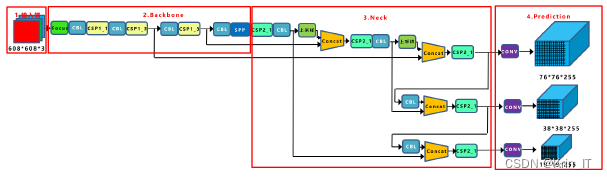
YOLOv5的网络结构分为输入端、Backbone、Neck和Prediction四个部分,构成了其高效的目标检测流程。输入端负责对输入图像进行预处理,包括缩放到指定尺寸和归一化操作,以确保数据符合模型的输入要求。Backbone部分是特征提取网络,利用卷积神经网络(CNN)提取图像中的重要特征,如边缘、纹理和形状等,这些特征是后续检测任务的基础。Neck网络则在Backbone提取的特征基础上进行特征融合和增强,使用如FPN(特征金字塔网络)或PAN(路径聚合网络)等结构,以提高不同尺度下目标的检测性能,增强模型的鲁棒性和准确性。最后,Prediction部分负责将
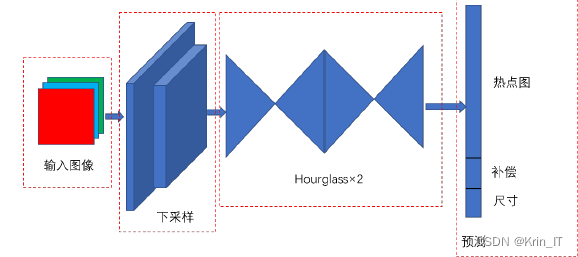
CenterNet是一种Anchor-free目标检测算法,它创新性地将目标检测任务转化为关键点检测任务,通过直接回归目标的中心点,简化了模型框架,避免了预定义锚框的复杂性。CenterNet具备更精确的定位能力和更快的推理速度,特别适用于小目标和复杂形状目标的检测,适合实时应用场景。
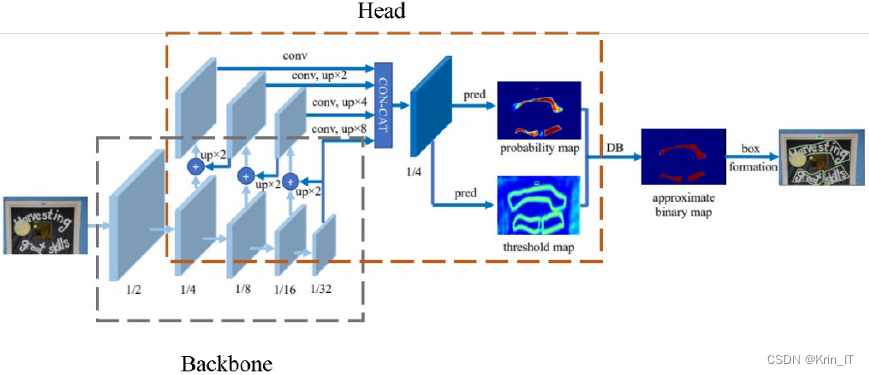
2.2 文本检测
文本检测的目的是在图像中准确寻找和定位包含文本的区域,核心任务是有效区分文本区域与背景。基于分割的文本检测算法通常通过对图像像素值进行阈值处理,以实现文本与背景的分离。DBNet作为一种创新的文本检测网络,提出了一种新颖的方法,其核心思想是通过网络输出每个像素的阈值,从而精准地将文本区域从背景中分离。DBNet在后期的运算量较小,具备快速的处理速度,且对于各种形状和方向的文本内容表现出优异的检测效果,适应性强,能够处理复杂的文本场景。
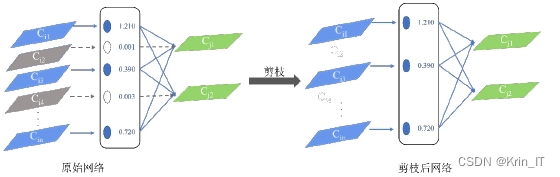
2.2 模型压缩
模型压缩方法中,剪枝法因其显著的效果和便于部署的特性而被选用。针对YOLOv5s这一轻量级网络模型,剪枝法能够有效减少模型的参数量和计算量,而无需进行复杂的迁移学习或张量分解。当前主流的稀疏化方法主要包括层稀疏化、权重稀疏化和通道稀疏化。
- 权重稀疏化是一种灵活的剪枝方法,旨在通过将某些权重设为零来减少模型的复杂性。这种方法在实现高剪枝率的同时,能够保持模型的性能,因而具有较强的泛化能力。然而,需要注意的是,权重稀疏化的加速效果往往依赖于特定的硬件平台支持,如使用稀疏矩阵运算的专用硬件,这限制了其广泛应用。
- 通道稀疏化则是另一种有效的剪枝策略,它的灵活性和剪枝率较为均衡,并且可以广泛应用于卷积层和全连接层。通道稀疏化通过选择性地删除整个通道,而不仅仅是单个权重,从而减少计算量并加速推理。这种方法能够在保证模型精度的前提下,显著降低模型的参数数量,同时提高运行效率。
- 层稀疏化相对较少被单独提及,它主要通过对特定层进行整体剪枝,减少某些层的深度或宽度,从而达到压缩模型的目的。这种方法在某些情况下也能有效降低计算量,但可能会影响模型的结构稳定性。
三、药品外包装检测的实现
3.1 数据集
图像采集开始,选择了自主拍摄和互联网采集相结合的方式。在自主拍摄中,尽量选择多样化的场景和光照条件,以确保数据集的丰富性和代表性;而互联网采集则通过获取公开的图像资源,快速增加数据样本量,进一步提升数据集的多样性。
在数据标注阶段,采用了Labelme这一开源工具进行标注。Labelme提供了用户友好的界面,便于对图像中的目标进行精确标注,支持多种标注形式,如矩形框、多边形等。标注完成后,生成的标注文件包括了目标类别和位置信息,为后续模型训练提供了必要的标签数据。

将数据集按照一定比例划分为训练集、验证集和测试集,以确保模型训练和评估的公正性。为了进一步增强数据集的泛化能力,采用了一系列的数据扩展技术,如随机旋转、缩放、翻转和颜色调整等。这些技术不仅增加了数据集的样本量,还帮助模型更好地适应不同的输入情况,从而提高了模型的鲁棒性和准确性。
3.2 实验环境搭建
网络模型训练的服务器配置为I9-9900K CPU、32GB内存和GTX 2080 Ti GPU,具有强大的计算能力,能够有效处理大规模数据集和复杂的深度学习任务。选择PyTorch作为目标检测的深度学习框架,得益于其灵活的动态计算图特性和丰富的社区支持,使得模型构建和调试更加高效。
3.2 实验及结果分析
选择了YOLOv5和CenterNet这两种算法。YOLOv5因其高效的实时检测能力和轻量级特性,适合于快速处理药品外包装图像,能够在较短时间内完成检测任务。CenterNet则是基于中心点的检测方法,能够在不同尺度的目标检测上表现出色,尤其在复杂的包装设计中,能够准确定位目标。通过结合这两种算法,我们可以综合利用它们的优点,提高药品外包装的检测精度和速度。
# 示例代码:加载YOLOv5模型
import torch
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', pretrained=True)在训练过程中,我们将关注损失函数的变化曲线,以评估模型的训练效果。损失函数是衡量模型预测与实际标签之间差距的重要指标。通过观察损失曲线,我们可以判断模型是否收敛,以及是否存在过拟合或欠拟合的问题。为了优化训练过程,我们采用了余弦退火学习率策略,该策略通过使用余弦函数逐渐降低学习率,使得在训练后期能够通过较小的学习率对模型进行精细调整,从而更好地降低损失函数值,提高模型性能。
# 示例代码:余弦退火学习率调度
from torch.optim.lr_scheduler import CosineAnnealingLR
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
scheduler = CosineAnnealingLR(optimizer, T_max=10)为了确保药品外包装上的压印字符能够被快速且准确地检测和识别,我们引入了OCR(光学字符识别)算法。OCR算法能够对图像中的文本进行定位和识别,尤其是在复杂背景下的字符提取。通过将OCR与目标检测模型相结合,我们可以实现对药品外包装上关键信息的快速提取,如药品名称、生产日期和有效期等。
# 示例代码:使用OCR识别文本
import pytesseract
from PIL import Image
image = Image.open('packaging_image.jpg')
text = pytesseract.image_to_string(image)
print(text)实现效果图样例
创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!

















 550
550

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









