








🪐🪐🪐欢迎来到程序员餐厅💫💫💫
主厨的主页:Chef‘s blog
所属专栏:青果大战linux
六级、会赢吗,悲
进程间通信
进程间通信缩写为IPC(Inter - Process Communication)
目的
- 数据传输:一个进程需要将它的数据发送给另一个进程
- 资源共享:多个进程之间共享同样的资源。
- 通知事件:一个进程需要向另一个或一组进程发送消息,通知它(它们)发生了某种事件(如进程终止时要通知父进程)。
- 进程控制:有些进程希望完全控制另一个进程的执行(如Debug进程),此时控制进程希望能够拦截另一个进程的所有陷入和异常,并能够及时知道它的状态改变
实现方法
进程具有独立性,互相独立,想实现不同进程之间的信息传输需要设置一些方法。
这些方法的本质其实都是让不同的进程看到同一份资源,举个简单的例子,进程A向一个文件写了一个字符串,之后进程B是不是就可以从文件中读取字符串,那两个进程是不是就实现了信息交流。当然具体实现比这个复杂很多。
管道:通过文件系统通信。
- 匿名管道pipe
- 命名管道
System V IPC:聚焦在本地通信。
- System V 消息队列
- System V 共享内存
- System V 信号量
POSIX IPC:让通信可以跨主机。
- 消息队列
- 共享内存
- 信号量
- 互斥量
- 条件变量
- 读写锁
匿名管道
什么是匿名管道
管道是Unix中最古老的进程间通信的形式。我们把从一个进程连接到另一个进程的一个数据流称为一个“管道”。
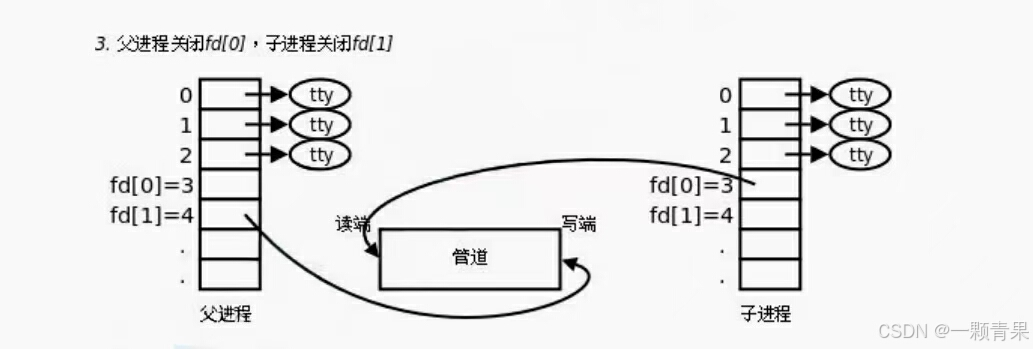
我们知道每个进程都有自己的task_struct结构体,该结构体中又有一个结构体指针——files_struct,files_struct里有一个数组fd_array,这个数组存放的就是该进程所打开的文件的指针(别迷糊了下面图写的很清楚)
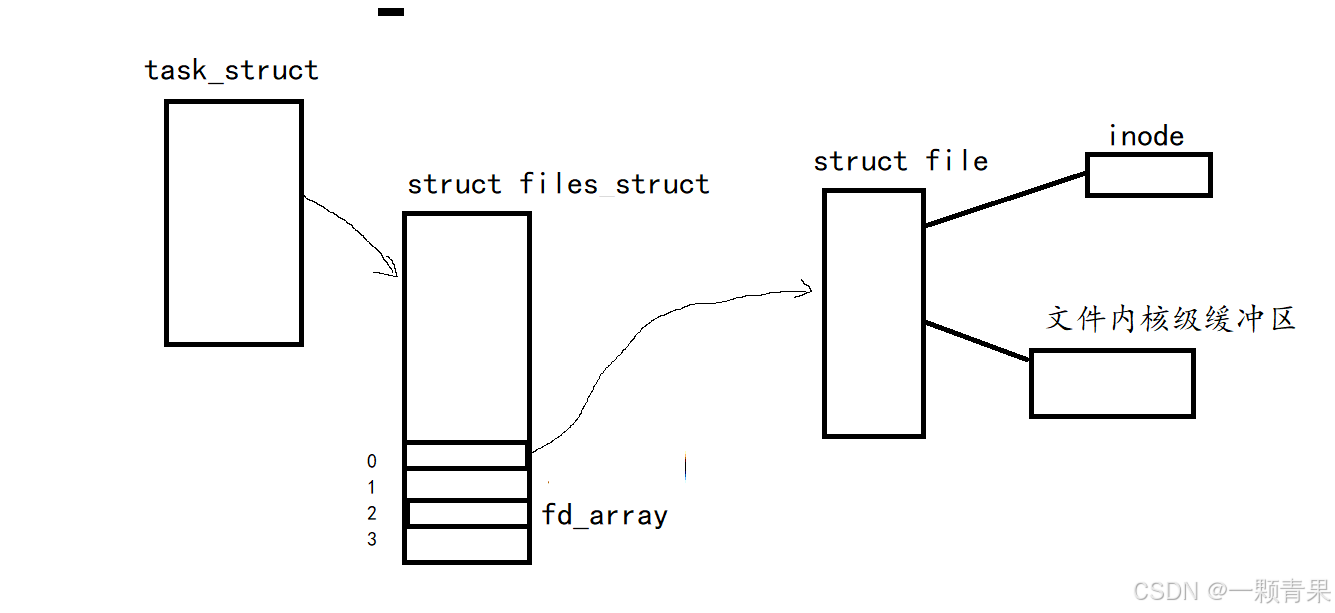
我们通过fork创建子进程后,子进程会有自己的task_struct,该结构体中的files_struct也会被新建一个,但是每个被打开的文件所对应的struct file呢?
事实上该结构体中有些数据不用被拷贝一份的,比如inode、文件内核级缓冲区;有些数据要被拷贝一份,比如该文件被该进程读写到哪个位置了,这个数据是被以一个整型形式保存的,父子进程可能读写不同位置,所以该数据要被拷贝一份的(具体发生在写写拷贝时)
那么现在,大家是不是意识到父子进程都能看到同一份文件了?
我们知道不管是读数据还是写数据都离不开文件内核缓冲区这一步,于是我们可以直接把文件内核级缓冲区当作管道!为什么不使用磁盘文件而只用内存中的缓冲区,因为内存IO速度远快于磁盘IO,且磁盘IO还是要经过缓冲区啊,我们管道也不需要掉电不丢失的特点,那自然就用不到磁盘了。
这些东西,Linux的佬们自然想到了,所以所谓的匿名管道就是一种特殊的文件,它可以被文件的接口调用,但是他不存在于磁盘,而仅仅存在于内存。
匿名管道的单向性
要注意匿名管道的特点是单向的,即要么父进程读取子进程写入,要么父进程写入子进程读取
为什么匿名管道是被设计为单向通信的呢,因为它被发明的那个时候,通信不发达,对于通信能力要求很低,单向通信足以满足,如果你设计为双向通信当然可以用,但是制作难度肯定会提高,但是却会性能溢出,不划算。
单向性要求匿名管道以如下方式使用
1.首先父进程分别以读写的方法打开一个文件,但是该文件是一个内存级的文件,不存在于磁盘中
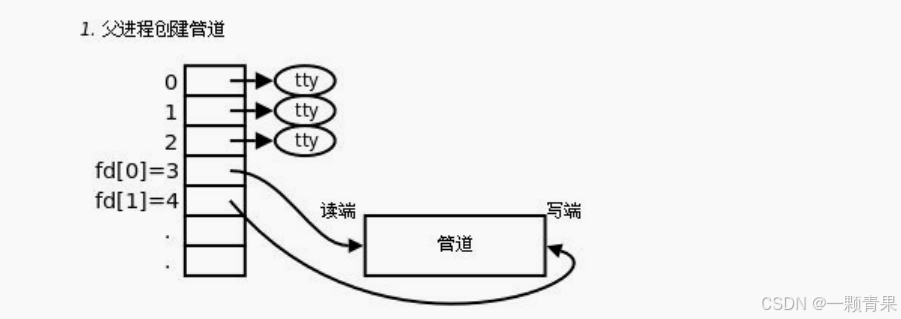
然后fork,于是子进程也看到了这个文件资源
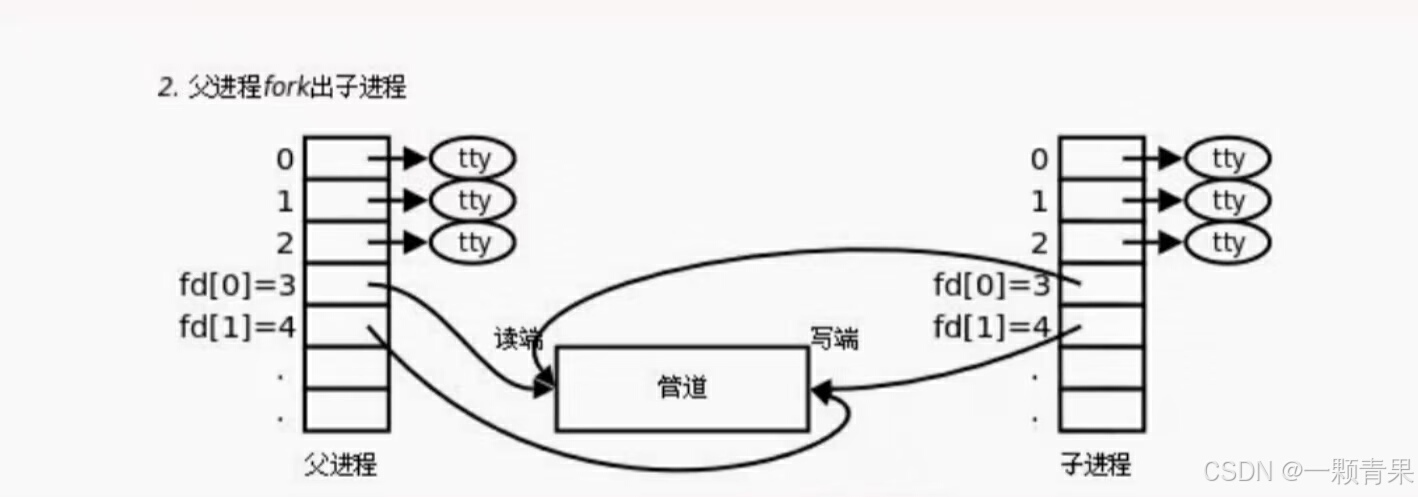 最后父进程关闭读端,子进程关闭写端或者父进程关闭写段,子进程关闭读端
最后父进程关闭读端,子进程关闭写端或者父进程关闭写段,子进程关闭读端
不关闭当然也可以通信,甚至可以直接双向通信,但是会有风险,
-
假如你留了给父进程读写端,但是只使用读端,那么写端对应的fd_array下标就相当于浪费了,这叫做文件描述符泄漏
-
你可能误操作,本来你想让父进程写的,结果不小心读了,那不就破坏了管道的数据吗
能不能先创建子进程,然后父进程以读写打开文件?
不可以,因为fork之后父子进程每次修改数据都会触发写时拷贝,即fork后父子进程已经相互独立了。
构建管道
#include <unistd.h>
int pipe(int pipefd[2]);
pipe函数用于创建一个匿名管道
- 函数返回值:如果成功创建管道,返回
0;如果出现错误,返回-1,并且会设置errno来指示错误的类型。 - 这个函数接收一个包含两个整数的数组
pipefd作为参数。当pipe函数成功调用时,它会将两个文件描述符填充到pipefd数组中。pipefd[0]为管道的读端文件描述符,用于从管道中读取数据;pipefd[1]为管道的写端文件描述符,用于向管道中写入数据。
你可以这么想,“0”看起来像是一个人在读书张嘴,所以他是读端,“1”像是我们写字用的笔,所以他是写端(甜菜!)
预测一下,下面代码输出结果应该是3和4,因为文件描述符0、1、2已经被占用了,所以pipe只能用3,4
#include<iostream>
using namespace std;
#include<unistd.h>
int main(){
int fd[2]={0};
int n=pipe(fd);
if(!n){
cout<<fd[0]<<endl<<fd[1];
}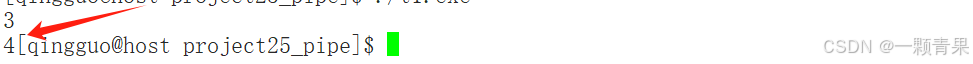
我们接下来以子进程写入,父进程读取的模式,来创造管道
#include <iostream>
#include <sys/wait.h>
#include <unistd.h>
#include <sys/types.h>
#include <cstdlib>
#include <string.h>
#include <string>
using namespace std;
int main()
{
int fd[2] = {0};
int n = pipe(fd);
if (!n)
{
pid_t pd = fork();
if (pd < 0)
{
cerr << "fork error" << endl;
return 2;
}
else if (!pd)
{
// 子进程
close(fd[0]); // 关闭读端
// 创建我们要传递的信息
int cnt = 0;
while (true)
{
string s("I am message");
s += std::to_string(getpid());
s += ",";
s += to_string(cnt);
write(fd[1], s.c_str(), s.size());
cnt++;
sleep(3);
}
exit(0);
}
else
{
// 父进程
close(fd[1]); // 关闭写段
char buffer[4096];
ssize_t num = 1;
while (num > 0)
{
num = read(fd[0], buffer, 4096);
buffer[num] = '\0';
cout << "reveive message :" << buffer << endl;
}
pid_t rid = waitpid(pd, nullptr, 0);
cout << "waitpid success" << endl;
}
}
else
{
cerr << "pipe error" << endl;
return 1;
}
}在该管道中我们,子进程每次循环都创建了不同的字符串然后把内容写进管道之后sleep3秒钟,父进程每次循环都从管道读取字符串。我们看一下结果。编译的时候记得 -std=c++11
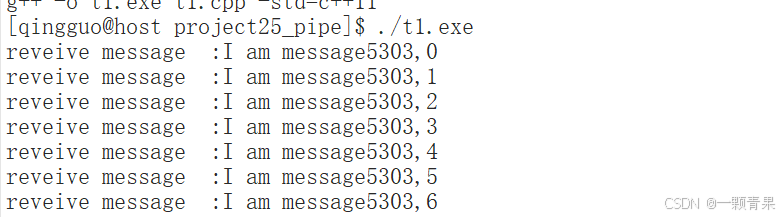
显然父进程成功接受了数据,而且是每隔三秒读取一次数据,和子进程很配合。
诶,等等,父进程为什么会每隔三秒读取一次?我们没有给父进程加sleep啊
这个问题就涉及到管道的特性了。
事实上,只要是想要进行进程间通信,其本质就是让进程看到同一份资源,我们称这种资源为共享资源,假如对该资源没有任何保护措施,那么就可能发生一个进程在写入资源的同时,另一个进程也在读取,本来想先写个hello world字符串,但刚写了一半你就来度去了,读走了个“hell”,这算什么事?于是管道设计者就给管道设计了一些保护措施。他的具体实现你先别管,我们先记住它所带来的管道四种读写情况即可。
-
当读写段都没被关闭,管道中没有数据时,读端会阻塞,所以刚才我们的父进程看上去也是sleep了3秒,其实是阻塞住了。
-
读端正常,写段关闭,读端会继续读取管道的数据,数据读完之后每次读取返回值为0,表示读取到了管道末尾(注意,写段没关闭时读取到末尾会直接阻塞,不会有返回值)
-
当读写段都没被关闭,管道已满,写端会阻塞,这说明管道是有大小的。
不同linux版本下,设计的管道大小可能会不同,但大多都是64kb
我们把父进程直接sleep1000s,然后子进程疯狂写数据
int sum=0;
while (true)
{
// string s("I am message");
// s += std::to_string(getpid());
// s += ",";
// s += to_string(cnt);
// int n=0;
string s="a";
n=write(fd[1], s.c_str(), s.size());
sum+=n;
cnt++;
cout<<"sum: "<<sum<<endl;
//sleep(3);
} 
可以看到结果恰好为64kb,也验证了管道满了的时候写段会阻塞
4.写段正常,读端关闭,显然此时无论怎么写入数据都不会有任何用,因此此时的管道仅仅是在对资源的浪费,OS会直接杀掉写端的进程。注意,不是关闭写端,而是直接把写端所在的进程结束了。依靠的是kill -13命令。我们可以靠代码获取进程退出信号来验证一下
pid_t rid = waitpid(pd, &st, 0);
cout << "waitpid success" << endl;
cout<<"退出信号"<<(st&0xFF)<<endl;
管道五大性质
- 一般而言,进程退出时,管道自动释放,所以管道的生命周期随进程
- 一般而言,内核会对管道操作进行同步与互斥
- 管道是单向通信的,数据只能向一个方向流动;需要双方通信时,需要建立起两个管道
- 只能用于具有亲缘关系的进程之间进行IPC(Inter - Process Communication),通常是父子进程,一个管道由一个进程创建,然后该进程调用fork,此后父、子进程之间就可应用该管道。
- 管道面向字节流
- 面向字节流是一种数据传输和处理的方式。在这种方式下,数据被看作是连续的字节序列,没有明显的界限来区分不同的数据单元,就像是一条源源不断的 “字节河流”。字节流主要关注的是字节的顺序传输,而不是数据的结构。
- 假如写端一次写了10个字节,写了十次轮到读端读取,读端读取的数据量只和read函数中所制定的大小有关,与写端写了什么类型的数据、写了几次数据无关,所以我们认为它面向字节流。
进程池
来手写一个简单的进程池吧,少年
即:一池子的进程(bushi
进程池是一种用于管理和复用进程的技术。它是一个进程的集合,在进程池中会预先创建一定数量的进程,这些进程处于等待状态,可以被分配任务来执行。当有新的任务到来时,进程池中的空闲进程就会被唤醒并执行任务,任务执行完毕后,进程不会被销毁,而是返回进程池继续等待下一个任务,从而避免了频繁地创建和销毁进程所带来的开销。
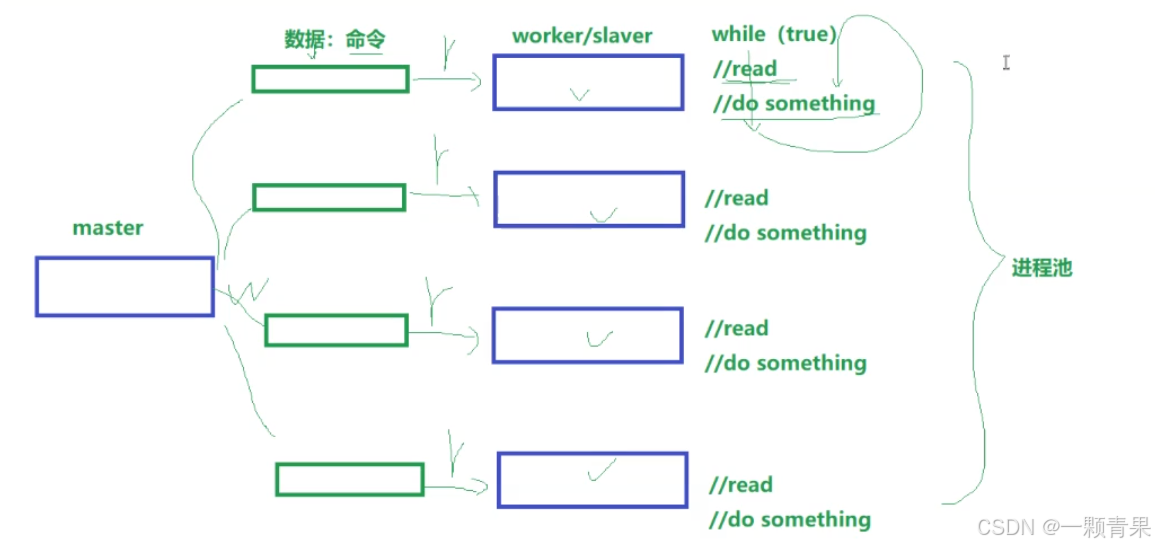
我们把负责分配任务的进程称为master进程,负责执行任务的进程成为work进程或者slaver进程
makefile
BIN=processpool//设置表示生成的可执行文件名的变量
CC=g++//表示使用的编译器名称的变量
FLAG=-c -Wall -std=c++11//表示编译选项的变量,-Wall它用于启用所有(或大部分)编译器能够提供的有用的警告信息,即warnings all
LDFLAGS=-o//
SRC=$(shell ls *.cc)//
OBJ=$(SRC:.cc=.o)//
$(BIN):$(OBJ)//
$(CC) $(LDFLAGS) $@ $^
%.o:%.cc
$(CC) $(FLAG) $<
.PHONY:clean
clean:
rm -rf $(BIN) $(OBJ)
test:
echo $(OBJ)
大佬自然知道这是什么,但小白看到上面的代码很可能一脸懵。
-
BIN=processpool:设置表示生成的可执行文件名的变量
-
CC=g++:设置表示使用的编译器名称的变量
-
FLAG=-c -Wall -std=c++11:设置表示编译选项的变量,其中-Wall它用于启用所有(或大部分)编译器能够提供的有用的警告信息,即warnings all
-
LDFLAGS=-o:设置表示链接选项的变量
-
SRC=$(shell ls *.cc)//表示该目录下所有后缀为.cc的文件名的集合
-
OBJ=$(SRC:.cc=.o)//将SRC中后缀为.cc的文件替换为.o然后存放于OBJ变量中
-
$(BIN):$(OBJ):$(变量名)==该变量的值
-
%.o:%.cc:
%是一种通配符,用于模式匹配。它可以代表任意长度(包括零长度)的字符串 -
$(CC) $(FLAG) $< :$<表示依赖列表的第一个文件
Channel
显然每个worker对应一个管道,但是master却需要管理很多管道,如何管理呢?

#pragma once
#include <string>
#include <sys/types.h>
#include <unistd.h>
using namespace std;
class Channel
{
public:
Channel(int wfd, pid_t who)
: _wfd(wfd), _who(who)
{
_name = "Channel-" + to_string(wfd) + "-" + to_string(who);
}
string Name()
{
return _name;
}
void Sent(int cmd) // 发送任务码
{
write(_wfd, &cmd, sizeof cmd);
}
void Close()
{
close(_wfd);
}
pid_t Pid()
{
return _who;
}
~Channel() {}
private:
int _wfd; // 管道编号
string _name; // 管道的名字
pid_t _who; // 管道pid
};Task
如何派发任务
-
我们可以传递任务码,每个任务码都是一个iint整型,父进程想管道写入,子进程读取,然案后根据任务表格(如数组)找到该任务吗对应的任务
-
首先我们要尽量均匀的派发任务,不可能说把所有任务都派给一个子进程,其他子进程都闲着,这样显然是浪费资源,即要保证负载均衡。我们可以使用随机数来实现,也可以用轮询的方法,还可以设置历史任务数,每次都把任务分给那些历史任务数较小的。这里我们用随机数选择派哪个任务,用轮询选择用哪个子进程执行任务
#pragma once
#include <iostream>
#include <unordered_map>
#include <functional>
using namespace std;
using task_t = std::function<void()>;
static int number = 0;
void p1()
{
printf("p1--%d\n", getpid());
}
void p2()
{
printf("p2--%d\n", getpid());
}
void p3()
{
printf("p3--%d\n", getpid());
}
void p4()
{
printf("p4--%d\n", getpid());
}
class Task
{
public:
Task()
{
InsertTask(p1);
InsertTask(p2);
InsertTask(p3);
InsertTask(p4);
}
void InsertTask(task_t t)
{
tasks[number++] = t;
}
int SelectTask()
{
return rand() % number; // 随机数选择
}
void Eexcute(int number)
{
if (tasks.find(number) == tasks.end())
return; // 没找到,直接返回
tasks[number](); // 找到了,执行该任务
}
~Task() {}
private:
std::unordered_map<int, task_t> tasks;
} task;
void Worker() // 子进程进行工作
{
while (true)
{
int cmd = 0;
int n = read(0, &cmd, 4);
if (n == 4)
{
task.Eexcute(cmd);
}
else if (n == 0)
{
cout << "pid:" << getpid() << "over" << endl;
break;
}
}
}ProcessPool
重要的解析我都以注释的方式写进去了
#include <iostream>
#include <vector>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <functional>
#include "Task.hpp" //允许实现和定义写在一起通常用于开源项目
#include "Channel.hpp"
using namespace std;
// 等价于using wort_t=function<void()>;
typedef function<void()> work_t;
enum
{
OK,//设置返回值
UseError,
PipeError,
ForkError
};
class ProcessPool
{
public:
ProcessPool(int n,work_t w)
:num(n)
,work(w)
{}
// 创建num个子进程,都执行work工作,且对应管道都放在channels中
void InitProcessPool()
{
// 先有管道,再去fork
for (int i = 0; i < num; i++)
{
int pipefd[2] = {0};
int flag = pipe(pipefd);
if (flag < 0)
exit(PipeError);
pid_t id = fork();
if (id < 0)
exit(ForkError);
if (id == 0)
{
// 子进程
//关闭历史fd
//for(auto i:channels)
//i.Close();
::close(pipefd[1]);
dup2(pipefd[0], 0);
work();
exit(OK);
}
else
{
::close(pipefd[0]);
channels.emplace_back(pipefd[1], id);
// 父进程
}
}
}
void DispatchTask() // 派发任务
{
int who_channel = 0;
int cnt = 10;
while (cnt--)
{
// 选择派发哪个任务"<<endl;
int n = task.SelectTask();
// 选择使用哪个子进程
Channel &curr = channels[who_channel++];
who_channel %= channels.size();
cout << "发送任务" << endl;
curr.Sent(n);
// sent over"<<endl;
sleep(1);
}
}
void DeleteProcessPool()
{
// for (auto i : channels)
// { i.Close();
// // for (auto i : channels)
// // {
// pid_t rid = waitpid(i.Pid(), NULL, 0);
// if (rid > 0)
// cout << "rid" << "recycle success" << endl;
// }
for (int i=channels.size()-1;i>=0;i--)
{ channels[i].Close();
pid_t rid = waitpid(channels[i].Pid(), NULL, 0);
if (rid > 0)
cout << "rid" << "recycle success" << endl;
}
}
private:
vector<Channel> channels;
int num;//要创建多少子进程
work_t work;
};Main.cc
#include "ProcessPool.hpp"
void HowUse(string s)//提醒用户该命令的正确使用格式
{
cout << "HowUse:" << s << " ProcessNum" << endl;
}
int main(int argc, char *argv[])
{
if (argc != 2)
{
HowUse(argv[0]);
return UseError;
}
vector<Channel> channels;
int num = stoi(argv[1]);
// 初始化进程池
ProcessPool *pp=new ProcessPool(num,Worker);
pp->InitProcessPool();
// 派发任务
pp->DispatchTask();
// 释放进程池
pp->DeleteProcessPool();
delete pp;
return OK;
}这就是一个进程池的全部代码了。 一切看似都是这么完美,但是我现在要提出一个问题了,
我们可以把写端的关闭和进程的回收写在同一个循环中吗?请看代码
void DeleteProcessPool()
{
for (auto i : channels)
{ i.Close();
pid_t rid = waitpid(i.Pid(), NULL, 0);
if (rid > 0)
cout << "rid" << "recycle success" << endl;
}
}直接看结果,显而易见,代码直接卡死了,why?

我们参考这张图解答
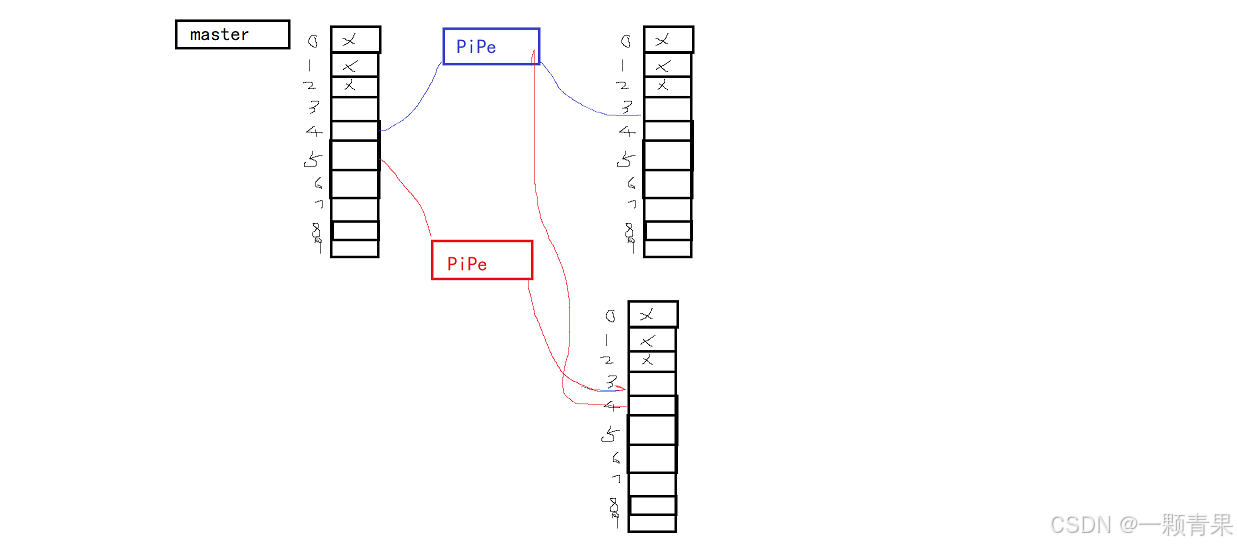
第一次创建管道,master使用了3和4当作文件标识符,1号子进程经过赋值也使用3和4当作文件标识符, ,然后父进程关闭了3(读端),子进程关闭了四号
第二次创建管道,master使用了3和5当作文件标识符,2号子进程经过赋值也使用3和5当作文件标识符, ,然后父进程关闭了3(读端),子进程关闭了5,但是别忘了,子进程还会把4也拷贝下来!!那么此时一号管道是不是就同时被master、1好进程、2号进程都指向了。
于是你第一次先关闭了1号管道的master的写端,此时还有很多子进程依旧保留了对他的写端,那么1好紫禁城就不会退出,于是就卡住了。
解决方法A,倒着循环即可。
void DeleteProcessPool()
{
for (int i=channels.size()-1;i>=0;i--)
{ channels[i].Close();
pid_t rid = waitpid(channels[i].Pid(), NULL, 0);
if (rid > 0)
cout << "rid" << "recycle success" << endl;
}
}
可我就是想从前往后怎么办,可以解决吗?
解决方案B,关闭历史fd
对于每个子进程,他所看到的那个channels,里面包含的就是除了本次fork的,历史上父进程所有的写端,这些写端同样被拷贝到了该子进程。
假如这是第三次fork,创建的就是第三个子进程,那么该子进程看到的channels里面就只有前两次fork后父进程所拥有的写端,所以在遍历完channels,还要再把本次的写端也关了,close(pipefd[1])
if (id == 0)
{
// 子进程
//关闭历史fd
//for(auto i:channels)
//i.Close();
::close(pipefd[1]);
dup2(pipefd[0], 0);
work();
exit(OK);
}好了,匿名管道讲完了,恭喜你,距离成为佬又进了一步。
看在你这么努力的份上,奖励你一个亚托莉的笑脸 (*´∀`)~♥


















 826
826

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









