






一、神经网络
1.1 神经网络模型分类
1.1.1 按层次型结构
该类型神经网络将神经元按照功能和顺序的不同分为输入层、中间层(隐层)、输出层
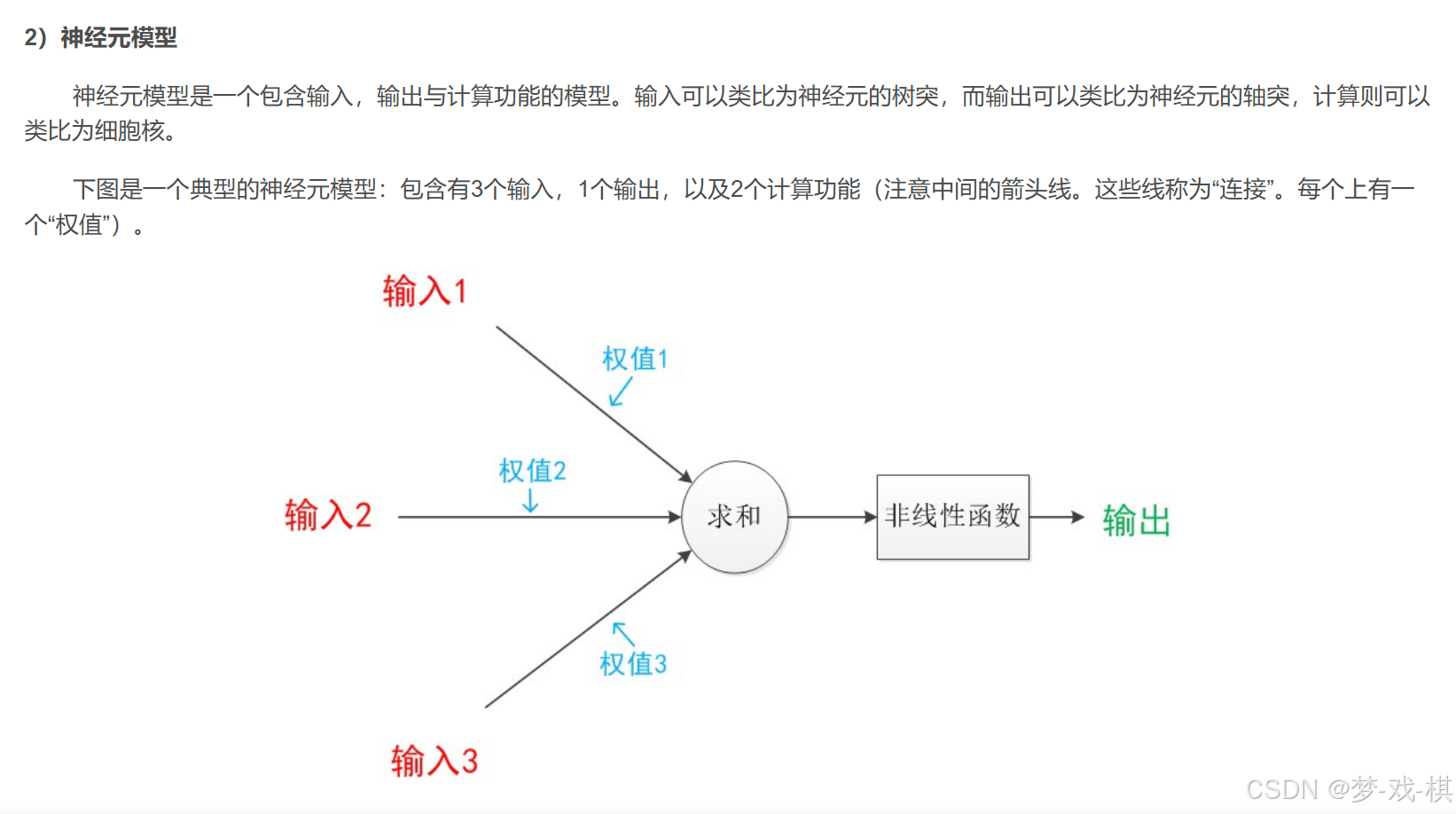
【解释1】:对于求和型神经元,基本模型的重点是突触权值和激活函数。
【解释2】:上图中的【非线性函数】其实属于【激活函数】、【激励函数】,由神经网络所要解决的问题决定选择某类激活函数,我们可以给出三类最典型的激励函数:
- 线性函数
- 硬限幅函数,只有0和1,用于分类
- S形函数,或sigmoid函数,0~1连续变化曲线
【注意】:一般可以由简单拟合方式处理的,没必要用神经网络去做,无法体现出优越性。
“神经网络的中心思想就是参数的可调整使得网络展示需要和令人感兴趣的行为。”
——这样, 我们就可以通过调整权重和偏置参量训练神经网络做一定的工作。 或者让神经网络自己
调整参数以得到想要的结果。
1.1.2 按照网络信息流向分类
前馈型:信息处理的方向是从输入到隐再到输出层
反馈型:优化,改变参数,
1.1.3 按照训练规则分类
监管式:需要准备学习数据,例如BP神经网络(back-propagation, 译为反向传播)
非监管式:不需要学习数据,需要学习方法判断
1.2神经网络的基本功能
1.数据处理:分类与识别
2.优化计算:博弈,下棋怎么走最好
3.非线性映射:对于大量数据进行拟合
【过拟合情况】:训练时候拟合的好,测试起来不好
二、BP误差反向传播神经网络
2.1 BP网络介绍
1985年又Rumelhart,McClelland提出。该成果成功地解决了求解非线性连续函数的多层前馈神经网络权重调整问题。是一种多层网络的逆推学习算法。
2.2 BP网络结构
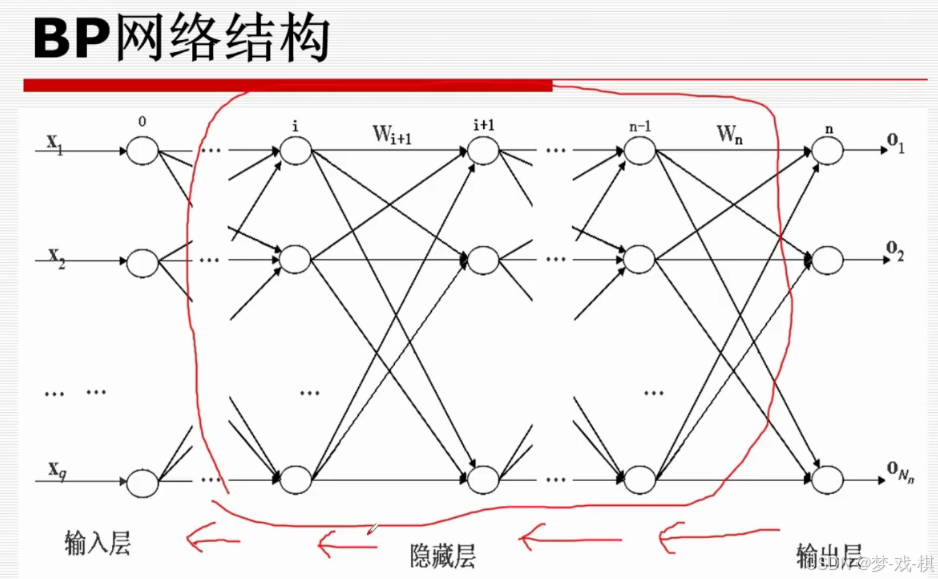
【注意】:
- 信息正向传播,误差反向传播
- 激活函数是固定的?只调整参数?(39:55)
2.3 BP网络的标准学习算法
2.3.1 算法思想
核心思想:将输出误差以某种形式通过隐层向输入层逐层反传,将误差分摊给各层的所有单元,分摊可以修正各单元权值
学习的过程:神经网络在外界输入样本的刺激下不断改变网络的权值、阈值,以使网络的·1输出不断地接近期望的输出。其中阈值可以设为已知的或者未知的,已知时变量少,未知时效果好。
学习的本质:对连接权值的一个动态调整,和最小二乘问题,无约束优化问题有关
——以下是学习过程

2.3.2网络的标准学习算法
网络结构:输入层n个神经元,隐含层p个神经元,输出层q个神经元
变量定义:
| 向量名 | 符号 |
|---|---|
| 输入向量 | x x x = ( x 1 , x 2 , ⋅ ⋅ ⋅ , x n x_1,x_2,\cdot\cdot\cdot,x_n x1,x2,⋅⋅⋅,xn) |
| 隐含层输入向量 | h i hi hi = ( h i 1 , h i 2 , ⋅ ⋅ ⋅ , h i n hi_1,hi_2,\cdot\cdot\cdot,hi_n hi1,hi2,⋅⋅⋅,hin) |
| 隐含层输出向量 | h o ho ho = ( h o 1 , h o 2 , ⋅ ⋅ ⋅ , h o n ho_1,ho_2,\cdot\cdot\cdot,ho_n ho1,ho2,⋅⋅⋅,hon) |
| 输出层输入向量 | y i yi yi = ( y i 1 , y i 2 , ⋅ ⋅ ⋅ , y i q yi_1,yi_2,\cdot\cdot\cdot,yi_q yi1,yi2,⋅⋅⋅,yiq) |
| 输出层输出向量 | y o y_o yo = ( y o 1 , y o 2 , ⋅ ⋅ ⋅ , y o q yo_{1},yo_{2},\cdot\cdot\cdot,yo_{q} yo1,yo2,⋅⋅⋅,yoq) |
| 期望输出向量 | d o d_o do = ( d 1 , d 2 , ⋅ ⋅ ⋅ , d q d_1,d_2,\cdot\cdot\cdot,d_q d1,d2,⋅⋅⋅,dq) |
【注意】:对于教师数据、输入向量和期望输出向量是已知的
| 向量名 | 向量符号 |
|---|---|
| 输入层与中间层的连接权值 | ω i h \omega_{ih} ωih |
| 隐含层与输出层的连接权值 | ω h o \omega_{ho} ωho |
| 隐含层各神经元的阈值 | b h b_{h} bh |
| 输出层各神经元的阈值 | b o b_{o} bo |
| 样本数据个数 | k = 1 , 2 , ⋅ ⋅ ⋅ m k = 1,2,\cdot\cdot\cdot m k=1,2,⋅⋅⋅m |
| 激活函数 | f ( ⋅ ) f(·) f(⋅) |
| 误差函数 | e = 1 2 ∑ o = 1 q ( d o ( k ) − y o o ( k ) ) 2 e=\frac{1}{2}\sum_{o=1}^q{(d_o(k)-yo_o(k))}^2 e=21o=1∑q(do(k)−yoo(k))2 |
【注意】误差函数和最小二乘、优化有关,向量二范数。光滑连续函数,可以求导
即令e为最小值,求权值。本质是迭代
2.3.3 流程
第一步,网络初始化:给各个连接权值赋一个(-1,1)内的随机数,设定误差函数e,给定计算精度值
ε
\varepsilon
ε,最大学习次数M。
第二步,将数据集分类:划分数据集,分为训练和预测数据
第三步,计算隐含层各神经元的输入输出
下图
b
h
是阈值
下图b_h是阈值
下图bh是阈值

第四步,利用网络预期输出
搜索“BP网络算法补充”
标准BP算法
修正权值
Δ
w
i
k
j
=
−
η
i
∂
E
∂
w
i
k
j
\Delta w_{ikj} = -\eta_i\frac{\partial E}{\partial w_{ikj}}
Δwikj=−ηi∂wikj∂E
【注意】:
η
i
\eta_i
ηi为第
i
i
i 层相关的学习率,也称为步长。
优化总览
- 增加动量项
- 可变学习速率
- 引入陡度因子
共轭梯度法


LM算法

其中
J
J
J 为雅可比矩阵(1:22:30)
RPROP算法

如果梯度是小于零,说明方向是对的,要加大这个方向的权值
B&B算法

【重点】:想要理解透彻需要学习优化模型
引用
【1】神经网络:从神经元到深度学习, ingy,https://blog.youkuaiyun.com/simonyucsdy/article/details/100138966?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522172096361516800225525255%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=172096361516800225525255&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduend~default-1-100138966-null-null.142v100pc_search_result_base1&utm_term=%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C%E4%B8%AD%E7%9A%84%E7%A5%9E%E7%BB%8F%E5%85%83&spm=1018.2226.3001.4187
【2】【西电数模】【2024数模国赛双创周培训】7.2 上午1-2节:BP神经网络算法-穆学文

















 135
135

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









