






文章目录
链表的文字介绍
什么是单链表?
你可以把单链表想象成一串珍珠项链,每一颗珍珠都代表一个数据元素,而连接这些珍珠的线就相当于指针,指向下一个珍珠(元素)。在单链表中,每个元素都保存着下一个元素的地址,这样就能够按顺序访问链表中的每一个元素。
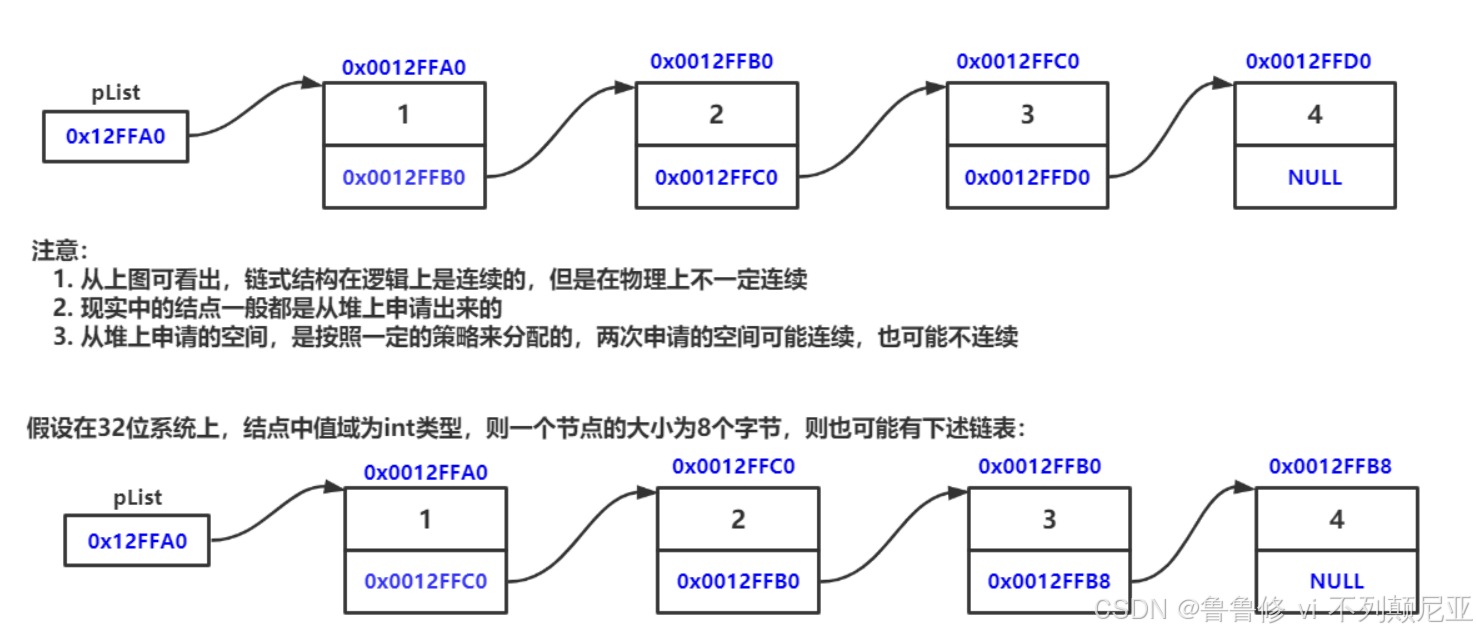
单链表的基本组成
数据域:存储实际的数据值,比如一个整数、一个字符串等。
指针域:存储下一个元素的内存地址。
每个链表元素(通常称为“节点”)都由这两部分组成。
单链表的特点
动态大小:链表的大小可以在运行时动态改变,不需要预先分配固定大小的空间。
插入和删除方便:在链表的任意位置插入或删除元素相对容易,不需要移动其他元素。
顺序访问:只能从链表的头部开始,按顺序访问每个元素,不能直接访问特定位置的元素(除非有额外的数据结构支持,如双向链表或带有索引的链表)。
示例
假设我们有一个简单的整数单链表:1 -> 2 -> 3 -> 4。这意味着第一个节点的数据是1,它指向第二个节点(数据为2),第二个节点指向第三个节点(数据为3),以此类推,直到最后一个节点(数据为4),它没有指向任何其他节点(指针为null)。这篇文章节点和结点的意思是一样的。
代码实现
单链表的定义
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
typedef int SLTDataType;//这里把int类型重命名为SLTDataType,是为了方便以后单链表储存别的类型数据,
//因为数据域指的可能是整型也可能是字符串等等,如果以后想要储存别的类型的数据只需要在这里把int改为别的类型即可,不需要在后面的代码去逐个改变
typedef struct SListNode {
SLTDataType data;//数据域
struct SListNode* next;//指针域
}SLTNode;//这里是把struct SListNode重命名为SLTNode,名字更短一点用起来更方便
单链表申请新的节点
SLTBuyNode(SLTDataType x): 这个函数用于创建一个新的节点,并返回指向它的指针,同样不需要二级指针。
//定义一个函数SLTBuyNode,用于申请(即动态分配)一个新的单链表节点,并初始化它 。
//函数参数x是要存储在新节点数据域中的值,其类型为SLTDataType 。
//函数返回一个指向新创建的节点的指针。
SLTNode* SLTBuyNode(SLTDataType x) {
// 使用malloc函数为新节点动态分配内存空间,大小为SLTNode结构体的大小
// 然后将返回的void*指针强制转换为SLTNode*类型,即指向SLTNode结构体的指针
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
// 检查malloc函数是否成功分配了内存,如果newnode为NULL,则表示分配失败
if (newnode == NULL) {
// 如果内存分配失败,则打印错误信息"malloc fail"以及具体的错误描述(由perror函数提供)
perror("malloc fail");
// 由于内存分配失败,函数返回NULL指针,表示没有新节点被创建
return NULL;
}
// 如果内存分配成功,则将新节点的数据域设置为函数参数x的值
newnode->data = x;
// 将新节点的next指针设置为NULL,表示这是链表的末尾节点(或当前未连接到其他节点)
newnode->next = NULL;
// 返回新创建的节点的指针
return newnode;
}
用二级指针的原因
下面的函数有些用了二级指针,是因为需要在函数里面修改头节点本身,要通过函数改变某个变量的值,就要往函数传入变量的地址(同时用指针来接收);
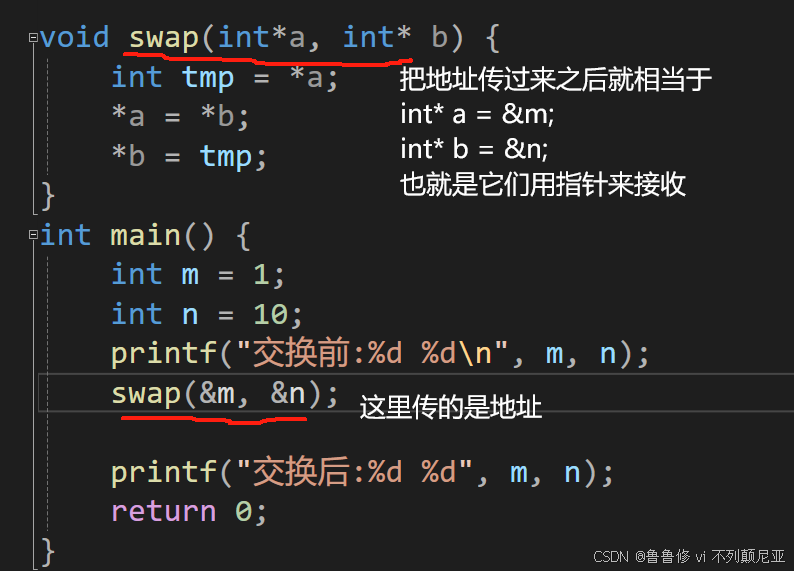
要通过函数改变某个指针的值,要往函数传入指针的地址,然后用指向该指针的指针接收,也就是二级指针 ;
同样的,改变二级指针的值要传入二级指针的地址,同时用三级指针来接收。
对于以下代码来说,是否需要使用二级指针主要取决于函数是否需要修改链表的头指针。如果需要修改头指针,那么就需要使用二级指针;如果不需要修改头指针,通常只需要一级指针就足够了。然而,在实际编程中,为了保持接口的一致性或者处理特殊情况,有时候即使不需要修改头指针,也可能会选择使用二级指针作为函数参数。
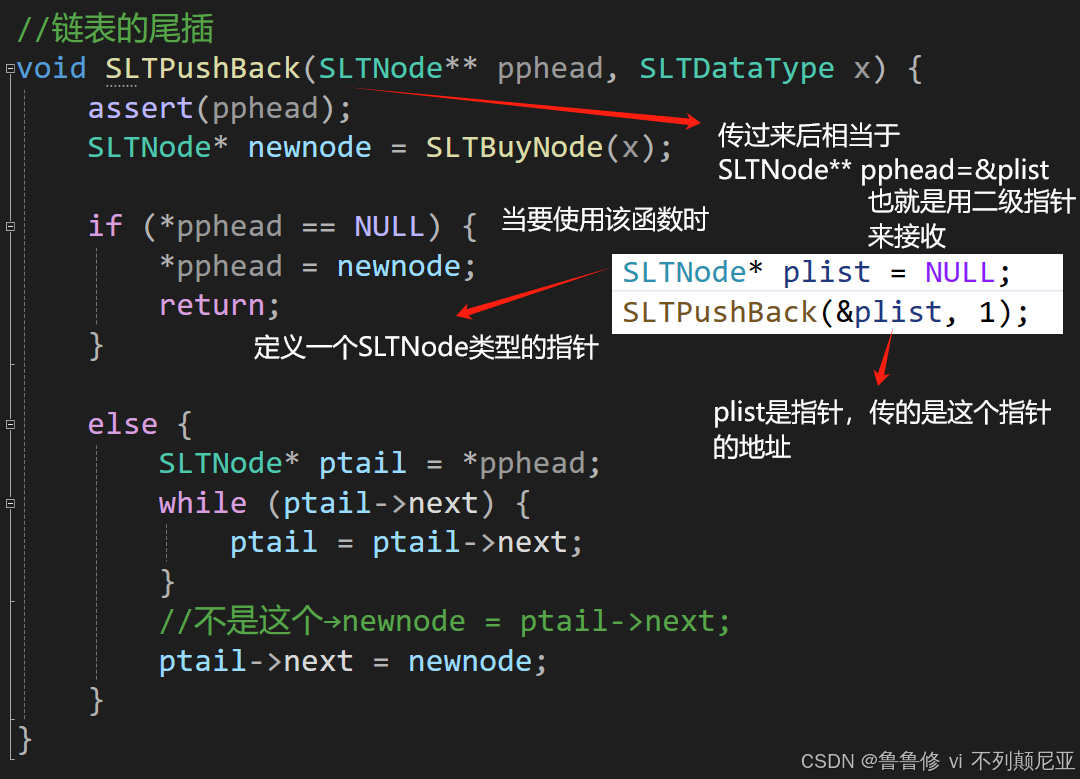
单链表尾插
SLTPushBack(SLTNode** pphead, SLTDataType x): 当链表为空时,需要修改头指针,因此需要二级指针。
// 定义链表尾插函数SLTPushBack
// 参数pphead是指向链表头节点指针的指针,用于可能修改头节点指针本身
// 参数x是要插入链表的新数据值
void SLTPushBack(SLTNode** pphead, SLTDataType x) {
// 使用assert宏确保传入的pphead不是NULL,如果是NULL则程序会在这里终止,这是一种简单的参数有效性检查,记得养成这个好习惯
assert(pphead);
// 调用SLTBuyNode函数创建一个新的节点,并将数据值x初始化到新节点的数据域中
SLTNode* newnode = SLTBuyNode(x);
// 检查链表是否为空,即头节点指针是否为NULL
if (*pphead == NULL) {
// 如果链表为空,则将新节点设置为链表的头节点,并更新外部的头节点指针
*pphead = newnode;
// 插入完成后直接返回
return;
}
// 如果链表不为空,则定义一个指针ptail指向当前的头节点,开始寻找链表的尾节点
SLTNode* ptail = *pphead;
// 遍历链表,直到找到最后一个节点(即其next指针为NULL的节点)
while (ptail->next) {
ptail = ptail->next;
}
// 将新节点的指针赋值给尾节点的next,从而将新节点插入到链表的尾部
ptail->next = newnode;
}
单链表头插
SLTPushFront(SLTNode** pphead, SLTDataType x): 这个函数总是在链表头部插入新节点,因此需要修改头指针,必须使用二级指针。
// 定义链表头插函数SLTPushFront
// 参数pphead是指向链表头节点指针的指针,这样可以修改头节点指针本身
// 参数x是要插入到链表头部的新数据值
void SLTPushFront(SLTNode** pphead, SLTDataType x) {
// 使用assert宏来确保传入的pphead不是NULL
// 如果pphead是NULL,程序将在这里终止,这是一种对函数参数的简单有效性检查
assert(pphead);
// 调用SLTBuyNode函数来创建一个新的节点,并将数据值x初始化到新节点的数据域中
SLTNode* newnode = SLTBuyNode(x);
// 将新节点的next指针指向当前的头节点,即把新节点插入到链表头部之前
newnode->next = *pphead;
// 更新头节点指针,使其指向新插入的节点
// 这样,*pphead就永远指向链表的头节点
*pphead = newnode;
}
单链表尾删
SLTPopBack(SLTNode** pphead): 当删除的是最后一个节点时,需要修改头指针,因此需要二级指针。
// 定义链表尾删函数SLTPopBack
// 参数pphead是指向链表头节点指针的指针,以便能够修改头节点指针本身
void SLTPopBack(SLTNode** pphead) {
// 使用assert宏确保传入的pphead不是NULL,同时确保链表不为空(*pphead不为NULL)
// 如果这些条件不满足,程序将在这里终止
assert(pphead);
assert(*pphead);
// 检查链表是否只有一个节点
if ((*pphead)->next == NULL) {
// 如果只有一个节点,则直接释放该节点的内存
free(*pphead);
// 并将头节点指针设置为NULL,表示链表现在是空的
*pphead = NULL;
// 处理完成后直接返回
return;
}
// 如果链表有多个节点,初始化两个指针,ptail指向链表尾部,prve用于跟踪ptail的前一个节点
SLTNode* ptail = *pphead;
SLTNode* prve = NULL;
// 遍历链表,找到尾节点及其前一个节点
while (ptail->next) {
prve = ptail; // 保存前一个节点
ptail = ptail->next; // 移动到下一个节点
}
// 将尾节点的前一个节点的next指针设置为NULL,从而删除尾节点
// 此时尾节点的内存并没有被显式释放,但因为没有其他指针指向它,所以它将在下次垃圾回收时被释放(在C语言中需要手动释放)
prve->next = NULL;
// 注意:原代码没有释放尾节点的内存,这在实际应用中可能会导致内存泄漏
// 正确的做法应该是在切断尾节点连接之前先释放其内存
free(ptail);
}
链表头删
SLTPopFront(SLTNode** pphead): 这个函数总是删除头部节点,需要修改头指针,因此必须使用二级指针。
// 定义链表头删函数SLTPopFront
// 参数pphead是指向链表头节点指针的指针,这样可以直接修改头节点指针本身
void SLTPopFront(SLTNode** pphead) {
// 使用assert宏确保传入的pphead不是NULL,同时确保链表不为空(*pphead不为NULL)
// 如果这些条件不满足,程序将在这里触发断言并终止
assert(pphead);
assert(*pphead);
// 将头节点指针的值(即当前头节点的地址)赋值给newnod指针
SLTNode* newnod = *pphead;
// 更新头节点指针,使其指向原头节点的下一个节点
// 这样,原头节点就从链表中脱离了
*pphead = newnod->next;
// 释放原头节点占用的内存
free(newnod);
// 将newnod指针设置为NULL,防止野指针的产生
// 这一步虽然对于当前的函数执行不是必需的,但它是一个好的编程习惯
newnod = NULL;
}
打印单链表
STLPrint(SLTNode* phead): 这个函数只是用来打印链表,不涉及链表的修改,因此只需要一级指针。
// 定义打印链表函数STLPrint
// 参数phead是指向链表头节点的指针
void STLPrint(SLTNode* phead) {
// 定义一个指针pcur,并将其初始化为指向链表的头节点
SLTNode* pcur = phead;
// 使用while循环遍历链表,直到pcur指针为NULL,即到达链表尾部
while (pcur) {
// 打印当前节点的数据,并在数据后面添加"->"表示指向下一个节点
printf("%d->", pcur->data);
// 将pcur指针移动到下一个节点,继续遍历
pcur = pcur->next;
}
// 在链表遍历完成后,打印"NULL"表示链表结束,并换行
printf("NULL\n");
}
单链表的查找
SLTFind(SLTNode** pphead, SLTDataType x): 尽管这个函数接收了一个二级指针,但实际上它并没有修改pphead所指向的内容,只是用来遍历链表。因此,这个函数其实只需要一级指针就足够了。这里的二级指针是为了保持函数接口的一致性。
// 定义链表查找函数SLTFind
// 参数pphead是指向链表头节点指针的指针,虽然查找时不需要修改头指针,但这样设计可以保持函数接口的一致性
// 参数x是要查找的数据值
// 函数返回找到的节点指针,如果没找到则返回NULL
SLTNode* SLTFind(SLTNode** pphead, SLTDataType x) {
// 使用assert宏确保传入的pphead不是NULL
assert(pphead);
// 定义一个指针pcur,并将其初始化为指向链表的头节点
SLTNode* pcur = *pphead;
// 使用while循环遍历链表,直到pcur指针为NULL,即到达链表尾部
while (pcur) {
// 如果当前节点的数据等于要查找的数据x
if (pcur->data == x) {
// 返回当前节点的指针
return pcur;
}
// 如果当前节点的数据不等于x,则将pcur指针移动到下一个节点,继续查找
pcur = pcur->next;
}
// 如果遍历完整个链表都没有找到数据值为x的节点,则返回NULL
return NULL;
}
在单链表的指定位置之前插入数据
SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x): 当pos是头节点时,需要修改头指针,因此需要使用二级指针。
// 定义在链表指定位置插入数据的函数SLTInsert
// 参数pphead是指向链表头节点指针的指针,以便在需要时修改头节点
// 参数pos是指示插入位置的节点,新节点将插入到这个节点之前
// 参数x是要插入的新节点的数据值
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x) {
// 使用assert宏确保传入的头节点指针的指针不为NULL,且头节点本身也不为NULL
assert(pphead);
assert(*pphead);
assert(pos);
// 创建一个新节点,并使用SLTBuyNode函数初始化它(该函数未在代码段中给出,但假设它负责分配内存和设置节点数据)
SLTNode* newnode = SLTBuyNode(x);
// 如果插入位置pos刚好是头节点
if (*pphead == pos) {
// 则调用SLTPushFront函数将新节点插入到链表头部(该函数未在代码段中给出,但功能明确)
SLTPushFront(*pphead, x);
// 插入完成后直接返回
return;
}
// 如果插入位置pos不是头节点
// 定义一个指针prve,初始化为头节点,用于找到pos节点的前一个节点
SLTNode* prve = *pphead;
// 使用while循环遍历链表,直到找到pos节点的前一个节点
while (prve->next != pos) {
prve = prve->next;
}
// 将新节点插入到prve和pos之间
// 首先将prve的next指针指向新节点
prve->next = newnode;
// 然后将新节点的next指针指向pos,完成插入操作
newnode->next = pos;
}
在单链表的指定位置之后插入数据
SLTInsertAfter(SLTNode** pphead, SLTNode* pos, SLTDataType x): 这个函数在指定节点后插入新节点,它并不修改头指针,所以理论上也只需要一级指针来指向pos。但是,为了保持接口的一致性或者处理特殊情况(例如pos为NULL时可能需要在链表头部插入),函数仍然接收了二级指针。在实际使用中,如果pos永远不为NULL,则不需要二级指针。
//在链表的指定位置之后插入数据
void SLTInsertAfter(SLTNode** pphead, SLTNode* pos, SLTDataType x) {
assert(pphead);
assert(*pphead);
SLTNode* newnode = SLTBuyNode(x);
SLTNode* ptail = *pphead;
while (pos->next != ptail) {
ptail = ptail->next;
}
newnode->next = ptail;
pos->next = newnode;
}
删除指定位置的节点
SLErase(SLTNode** pphead, SLTNode* pos): 当删除的是头节点时,需要修改头指针,因此需要使用二级指针。
//删除指定位置的节点
void SLErase(SLTNode** pphead, SLTNode* pos) {
assert(pphead);
assert(*pphead);
assert(pos);
//刚好是头节点,没有前驱节点,执行头删
if (pos->next == NULL) {
SLTPopFront(pphead);
return;
}
//不是头节点
SLTNode* prve = *pphead;
while (prve->next != pos) {
prve = prve->next;
}
prve->next = pos->next;
free(pos);
pos = NULL;
}
删除指定位置之后的节点
SLEraseAfter(SLTNode* pos): 这个函数删除指定节点后的节点,同样不需要修改头指针,因此只需要一级指针。
// 定义删除链表中指定位置之后节点的函数SLEraseAfter
// 参数pos是指向要删除节点前一个位置的节点的指针
void SLEraseAfter(SLTNode* pos) {
// 确保传入的节点指针不为NULL
assert(pos);
// 确保传入的节点之后还有节点(即pos->next不为NULL),因为要删除的是pos之后的节点
assert(pos->next);
// 创建一个临时指针del,指向要删除的节点(即pos的下一个节点)
SLTNode* del = pos->next;
// 将pos的next指针指向要删除节点的下一个节点,从而跳过要删除的节点
pos->next = del->next;
// 释放要删除节点占用的内存空间
free(del);
// 将del指针置为NULL,防止野指针的产生(虽然在这个函数执行完毕后del指针会被销毁,但这样做是一个好的编程习惯)
del = NULL;
}
单链表的销毁
SListDesTroy(SLTNode** pphead): 这个函数用于销毁整个链表,包括释放所有节点的内存和将头指针设为NULL,因此必须使用二级指针。
// 定义销毁链表的函数SListDesTroy
// 参数pphead是指向链表头节点指针的指针
void SListDesTroy(SLTNode** pphead) {
// 确保传入的头节点指针的指针和头节点本身不为NULL
assert(pphead);
assert(*pphead);
// 创建一个指针pcur,指向链表的头节点,用于遍历链表
SLTNode* pcur = *pphead;
// 使用while循环遍历链表,直到pcur为NULL,即链表末尾
while (pcur) {
// 创建一个临时指针next,保存当前节点的下一个节点
SLTNode* next = pcur->next;
// 释放当前节点占用的内存空间
free(pcur);
// 将pcur指向下一个节点,继续遍历
pcur = next;
}
// 将头节点指针置为NULL,表示链表已经被销毁
*pphead = NULL;
}
完整代码
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
typedef int SLTDataType;
//链表的定义
typedef struct SListNode {
SLTDataType data;
struct SListNode* next;
}SLTNode;
//打印链表
void SLTPrint(SLTNode* phead) {
SLTNode* pcur = phead;
while (pcur) {
printf("%d->", pcur->data);
pcur = pcur->next;
}
printf("NULL\n");
}
//申请新的节点
SLTNode* SLTBuyNode(SLTDataType x) {
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
if (newnode == NULL) {
perror("malloc fail");
return;
}
newnode->data = x;
newnode->next = NULL;
return newnode;
}
//链表尾插
void SLTPushBack(SLTNode** pphead, SLTDataType x) {
assert(pphead);
SLTNode* newnode = SLTBuyNode(x);
//链表为空,新节点作为phead
if (*pphead == NULL) {
*pphead = newnode;
return;
}
//链表不为空
SLTNode* ptail = *pphead;
while (ptail->next) {
ptail = ptail->next;
}
ptail->next = newnode;
}
//链表头插
void SLTPushFront(SLTNode** pphead, SLTDataType x) {
assert(pphead);
SLTNode* newnode = SLTBuyNode(x);
newnode->next = *pphead;
//*pphead永远是头节点
*pphead = newnode;
}
//链表尾删
void SLTPopBack(SLTNode** pphead) {
assert(pphead);
//链表不能为空
assert(*pphead);
//链表只有一个节点
if ((*pphead)->next == NULL) {
free(*pphead);
*pphead = NULL;
return;
}
//链表有多个节点
SLTNode* ptail = *pphead;
SLTNode* prve = NULL;
while (ptail->next) {
prve = ptail;
ptail = ptail->next;
}
prve->next = NULL;
free(ptail);
}
//链表头删
void SLTPopFront(SLTNode** pphead) {
assert(pphead);
assert(*pphead);
SLTNode* newnod = *pphead;
*pphead = newnod->next;
free(newnod);
newnod = NULL;
}
//链表的查找
SLTNode* SLTFind(SLTNode** pphead, SLTDataType x) {
assert(pphead);
SLTNode* pcur = *pphead;
while (pcur) {
if (pcur->data == x) {
return pcur;
}
pcur = pcur->next;
}
return NULL;
}
//链表的在指定位置之前插入数据
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x) {
assert(pphead);
assert(pos);
assert(*pphead);
SLTNode* newnode = SLTBuyNode(x);
//pos刚好是头节点
if (*pphead == pos) {
SLTPushFront(*pphead, x);
return;
}
//pos不是头节点
SLTNode* prve = *pphead;
while (prve->next!=pos) {
prve = prve->next;
}
prve->next = newnode;
newnode->next = pos;
}
//链表的在指定位置之后插入数据
void SLTInsertAfter(SLTNode** pphead, SLTNode* pos, SLTDataType x) {
assert(pphead);
assert(*pphead);
SLTNode* newnode = SLTBuyNode(x);
newnode->next = pos->next;
pos->next = newnode;
}
//删除pos节点
void SLErase(SLTNode** pphead, SLTNode* pos) {
assert(pphead);
assert(*pphead);
assert(pos);
//刚好是头节点,没有前驱节点,执行头删
if (pos->next == NULL) {
SLTPopFront(pphead);
return;
}
//不是头节点
SLTNode* prve = *pphead;
while (prve->next != pos) {
prve = prve->next;
}
prve->next = pos->next;
free(pos);
pos = NULL;
}
//删除pos之后的节点
void SLEraseAfter(SLTNode* pos) {
assert(pos);
//pos->next不能为空
assert(pos->next);
SLTNode* del = pos->next;
pos->next = del->next;
free(del);
del = NULL;
}
//链表的销毁
void SListDesTroy(SLTNode** pphead) {
assert(pphead);
SLTNode* pcur = *pphead;
while (pcur) {
SLTNode* next = pcur->next;
free(pcur);
pcur = next;
}
*pphead = NULL;
}
//测试
void test() {
SLTNode* plist = NULL;
SLTPushBack(&plist, 1);
SLTPushBack(&plist, 2);
SLTPushBack(&plist, 3);
SLTPushBack(&plist, 4);
SLTPushBack(&plist, 5);
SLTPrint(plist);
SLTPushFront(&plist, 10);
SLTPushFront(&plist, 20);
SLTPrint(plist);
SLTPopBack(&plist);
SLTPopBack(&plist);
SLTPrint(plist);
SLTPopFront(&plist);
SLTPopFront(&plist);
SLTPrint(plist);
/*SLTNode* FindR = SLTFind(&plist, 1);
SLTEraseAfter(&plist, FindR);
SLTPrint(plist);*/
SLTNode* FindR = SLTFind(&plist, 1);
SLTInsert(&plist, FindR,50);
SLTPrint(plist);
/*SLTNode* Find = SLTFind(&plist, 2);
SLTInsertAfter(&plist, FindR, 60);
SLTPrint(plist);*/
}
int main() {
test();
return 0;
}
若有错误或问题,欢迎在评论区提出。

















 7628
7628

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









