







这篇文章主要是讲的Python语言的算法,本人还在不断记笔记中,文章也会持续更新,内容比较浅薄,请大家指教![]() 另外推荐一个比较好用的记笔记的软件Typora,自己已经使用很久了,感觉不错。。。虽然但是还是有欠缺。
另外推荐一个比较好用的记笔记的软件Typora,自己已经使用很久了,感觉不错。。。虽然但是还是有欠缺。
目录
2.2.1链表的基本操作(忽略查找过程插入删除操作时间复杂度都是O(1))
2.队列通常是对历史的回忆,正序(多线程和争夺公平锁,网络爬取url)
第一章 算法概述
1.1 什么是数据结构?
01 数据结构都有哪些组成方式
-
线性结构 最简单的数据结构(数组 链表 栈 队列 哈希表)
-
树 (二叉树 二叉堆)
-
图(多对多的关联关系)
-
跳表 哈希链表 位图.....
02 时间复杂度
设T(n)为程序基本执行次数的函数(程序的相对执行时间函数),n为输入规模,以下是程序中常见的四种执行方式:

例01 渐进时间复杂度
若存在函数f(n),使得当n趋近于无穷大时,T(n)/f(n)的极限值为不等于零的常数,则称f(in)是T(n)的同数量级函数。记作T(n)= O(f(n)),称为O(f(n)),0为算法的渐进时间复杂度,简称为时间复杂度。
如何推导出时间复杂度呢?有如下几个原则:
-
如果运行时间是常数量级,则用常数1表示
-
只保留时间函数中的最高阶项。
-
如果最高阶项存在,则省去最高阶项前面的系数。
03 空间复杂度:S(n) = O(f(n))
1.常量空间 O(1)
2.线性空间 O(n)
3.三维空间:当算法分配的空间是一个二维列表集合,并且集合的长度和宽度都与输入规模n成正比时,空间复杂度记作O(n^2)
4.递归空间:函数调用栈(进栈和出栈)其算法的空间复杂度和递归深度成正比
第二章 数据结构基础
2.1 数组的基本操作 (读取 更新 插入 删除)
$$
数组多适合的是读操作多,写操作少的场景 数组是顺序存储
$$
数组多适合的是读操作多,写操作少的场景 数组是顺序存储
数组读取元素和更新元素的时间复杂度都是O(1)
在初始化列表时已经确定了数组的长度,所以要想实现超范围插入则涉及到数组的扩容
在Python中,`[None] * len(self.array)` 表达式创建了一个新的列表,这个列表的长度与 `self.array` 相同,但每个元素都是 `None`。 这里是这个表达式的详细解释: 1. `None` 是Python中的一个特殊常量,表示没有值或空值。它经常用于初始化变量或作为占位符。 2. `[None]` 是一个包含一个 `None` 元素的列表。 3. `len(self.array)` 计算 `self.array` 列表的长度。 4. `[None] * len(self.array)` 通过将 `[None]` 列表复制 `len(self.array)` 次来创建一个新的列表,其中的每个元素都是 `None`。 这个表达式常用于创建一个与另一个列表长度相同但所有元素都是 `None` 的新列表。例如,假设你有一个包含数字的列表,并且你想创建一 个与之相同长度的列表来存储计算结果,但在计算之前你想初始化所有元素为 `None`,那么你就可以使用这种方法。
例01 插入:
'''
# 初始化列表
my_list = [6,1,5,4,2,7,8,9,3]
# 读取列表
print(my_list[2])
'''
# 插入算法
class MyArray:
def __init__(self,capacity):
self.array = [None] * capacity
self.size = 0
def insert(self,index,element):
# 判断访问下标是否超出范围
if index < 0 or index > self.size:
raise Exception("超出数组实际元素范围!")
# 从右向左循环,逐个向右挪动一位
for i in range(self.size - 1,-1,-1):#从大到小遍历一个序列
self.array[i+1] = self.array[i]
# 腾出的位置放置新元素
self.array[index] = element
self.size += 1
def output(self):
for i in range(self.size):
print(self.array[i])
array = MyArray(4)
array.insert(0,10)
array.insert(0,11)
array.insert(0,15)
array.output()# 改写 扩容
class MyArray:
def __init__(self,capacity):
self.array = [None] * capacity
self.size = 0
def insert(self, index, element):
# 判断访问下标是否超出范围
if index < 0 or index > self.size:
raise Exception("超出数组实际元素范围!")
# 如果实际元素达到数组容量上线,数组扩容
if self.size >= len(self.array):
self.resize()
# 从右向左循环,逐个元素向左挪一位
for i in range(self.size-1,-1,-1):
self.array[i+1] = self.array[i]
# 腾出位置放入新元素
self.array[index] = element
self.size += 1
def resize(self):
array_new = [None] * len(self.array) * 2
# 从旧数组复制到新数组
for i in range(self.size):
array_new[i] = self.array[i]
self.array = array_new
def output(self):
for i in range(self.size):
print(self.array[i])
array = MyArray(4)
array.insert(0,10)
array.insert(0,11)
array.insert(0,15)
array.output()例02 删除(时间复杂度)
数组扩容的时间复杂度是0(n),
插入并移动元素的时间复杂度也是0(n),
综合起来插入操作的时间复杂度是0(n)。
至于删除操作,只涉及元素的移动,时间复杂度也是0(n)。
2.2 链表
链表简介
(linked list 是一种在物理上非连续、非顺序的数据结构,有若干节点(node)所组成)
单向链表:date+next—>date+next... ...—>Null
date:存放数据,next指向下一个节点的指针 尾节点 头结点
双向链表:外加一个前置节点prev指针
存取方式:随机存储
2.2.1链表的基本操作(忽略查找过程插入删除操作时间复杂度都是O(1))
1.查找节点,最坏的时间复杂度是O(n)
2.更新节点(直接copy)
3.插入节点
尾部插入:最后一个next指向新插入的节点
头部插入:把新节点next指向头结点,然后将其转换为链表头结点
中间插入:要插入的新节点next指向要插入位置的节点,插入位置前置节点的next指向新节点
4.删除元素
尾部删除:前置节点指向空
头部删除:链表头结点设为原先头结点的next指针所指向的节点
中间删除:要删除元素的前置节点指向该节点的next节点
# 声明一个节点
class Node:
def __init__(self,data):
self.data = data
self.next = None
# 连接节点
class LinkedList:
def __init__(self):
self.size = 0
self.head = None
self.last = None
# 获取节点
def get(self,index):
if index<0 or index >= self.size:
#self.size<0这句有什么影响
#因为这不是一个由用户输入错误索引导致的问题,而是链表内部状态不正确的问题。
raise Exception('超出链表范围!')
p = self.head
for i in range(index):
p = p.next
return p
# 插入:
def insert(self,data,index):
if index<0 or index > self.size:
raise Exception('超出链表范围!')
node = Node(data) #假设 Node 类已经定义,并且有一个接受单个数据参数的构造函数
if self.size == 0:
#空链表
self.head = node
self.last = node
elif index == 0:
#头部
node.next = self.head
self.head = node
elif self.size == index:
#尾部
self.last.next = node
self.last = node
else:
#中部
prev_node = self.get(index-1)
node.next = prev_node.next
prev_node.next = node
self.size += 1
#删除
def remove(self,index):
if index<0 or index > self.size:
raise Exception('超出链表范围!')
#暂存被删除的节点,用于返回
if index == 0:
# 删除头结点
remove_node = self.head
self.head = self.head.next
# del remove_node
elif index == self.size-1:
#删除尾节点
prev_node = self.get(index-1)
remove_node = prev_node.next
prev_node.next = None
self.last = prev_node
else:
#删除中间节点
prev_node = self.get(index-1)
next_node = prev_node.next.next
remove_node = prev_node.next
prev_node.next = next_node
self.size -= 1
return remove_node
#输出
def output(self):
p = self.head
while p is not None:
print(p.data)
p = p.next
linkedList = LinkedList()
linkedList.insert(3,0)
linkedList.insert(4,0)
linkedList.insert(9,2)
linkedList.insert(5,3)
linkedList.insert(6,1)
linkedList.remove(0)
linkedList.output()2.2.2数组VS链表

2.3栈(stack)和队列(queue)
2.3.1物理结构和逻辑结构

2.3.2栈的基本操作
1.入栈(push)相当于数组中的append方法
2.出栈(pop)相当于数组中的pop方法
时间复杂度都是O(1)
栈是一种线性数据结构,先进后出(FILO)。栈底(bottom)栈顶(top)
2.3.3队列的基本操作
队列是一种线性数据结构,先入先出(FIFO)。队头(front)队尾(rear)
1.入队(enqueue)注:队尾位置规定为最后入队元素的下一位置,只允许在队尾的位置放入元素,新元素的下一位置将会成为新的队尾。
2.出栈(dequeue)只允许在队头一侧移出元素,出队元素的最后一个元素将成为新的队头。
大小空间位置固定,删除时,元素删除但位置还是存在的,所以会存在浪费队列的容量,所以有了接下来 循环队列.....
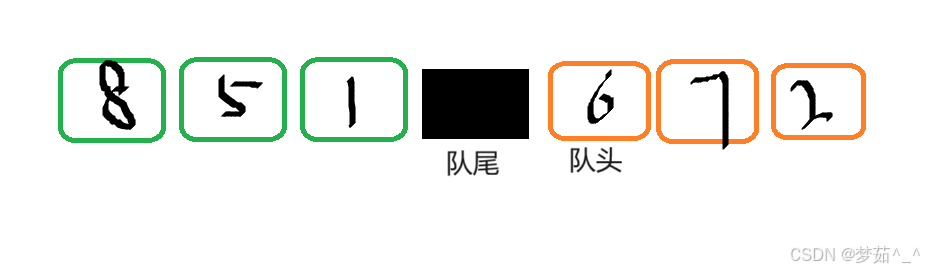
队列满的条件:(队尾下标+1)%数组长度 = 队头下标
Python 中提供了几种方式来实现队列的功能,最常用的是
collections模块中的deque(双端队列)和queue模块中的Queue、LifoQueue(后进先出队列)、PriorityQueue(优先队列)等。这些工具已经足够满足大多数队列操作的需求,因此通常不需要另外创造队列。点击链接 文心一言
2.2.5栈和队列的应用
1.栈通常用于回溯历史,倒序,因为栈通常是先进后出
2.队列通常是对历史的回忆,正序(多线程和争夺公平锁,网络爬取url)
3.双端队列
4.优先队列,基于二叉堆来实现
2.3哈希表
散列表,这种数据结构提供了键和值的映射关系,时间复杂度接近于O(1)
Python中,哈希表对映的集合叫做字典(dict)。
哈希函数:每一个对象都有一个hash值,是一个整型变量,转换方式为
index = hash(key)% size
2.3.1哈希表的读写操作
1.写操作(put)插入新的键值对(Entry)
此时会遇到哈希冲突,解决方法:开放寻址法(如果该下标被占用就顺移到下一位...)链表法()
2.读操作(get)
例:dict["002936"]。利用哈希函数找到下标,然后比对所查找的值是否和下标的值相同,如果不相同继续向下查找。返回键值对的Value即可。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









