







这次面试感觉自己很蠢,有一些很基础的知识点没有回答上来。
1. 下面这份代码缺少哪些函数??
class Base
{
virtual void print();
};
class BaseSub : public Base
{
void print();
};这道题目,我感觉缺少了析构函数。因为基类中含有虚函数,派生类继承基类。当基类指针指向派生类对象时,如果析构函数不是虚函数,会造成内存泄露。
2. 为什么析构函数需要设置为虚函数?
虚析构函数:是将基类的析构函数声明为virtual,举例如下:
class TimeKeeper
{
public:
TimeKeeper() {}
virtual ~TimeKeeper() {}
};虚析构函数的主要作用是防止内存泄露。
定义一个基类的指针p,在delete p时,如果基类的析构函数是虚函数,这时只会看p所复制的对象,如果p赋值的对象是派生类的对象,就会调用派生类的析构函数(毫无疑问,在这之前也会先调用基类的构造函数,在调用派生类的构造函数,然后调用派生类的析构函数,基类的析构函数,所谓先构造后释放);如果p赋值的对象是基类的对象,就会调用基类的析构函数,这样就不会造成内存泄露。
如果基类的析构函数不是虚函数,在delete p时,调用析构函数时,只会看指针的数据类型,而不会去看赋值的对象,这样就会造成内存泄露。
3. grpc如何生成c++代码(有疑问)
编写proto文件,使用以下的命令生成:
# 使用 protoc 生成 .h 和 .cc 文件
protoc --cpp_out=. --grpc_out=. --plugin=protoc-gen-grpc=`which grpc_cpp_plugin` helloworld.proto
4. 多态是怎么实现的,多态有哪些
多态分为静态多态和动态多态。
静态多态(重载):
我们在平时写代码中会用到几个函数但是他们的实现功能相同,但是有些细节却不同。C++中可以用一个函数名定义多个函数,也就是所谓的函数重载。函数重载是指同一个可访问区内被声明的几个具有不同参数列(参数的类型,个数,顺序不同)的同名函数,根据参数列表确定调用哪一个函数,重载不关心函数返回类型。
#include<bits/stdc++.h>
using namespace std;
class A
{
void fun() {};
void fun(int i) {};
void fun(int i, int j) {};
void fun1(int i,int j){};
};动态多态(重写):
重写是指在派生类中存在重新定义的函数。其函数名,参数列表,返回值类型,所有都必须同基类中被重写的函数一致。只有函数体不同(花括号),派生类对象调用时会调用派生类的重写函数,不会调用被重写函数。重写的基类中被重写的函数必须有virtual修饰。
#include<bits/stdc++.h>
using namespace std;
class A
{
public:
virtual void fun()
{
cout << "A";
}
};
class B :public A
{
public:
virtual void fun()
{
cout << "B";
}
};
int main(void)
{
A* a = new B();
a->fun();//输出B,A类中的fun在B类中重写
}5. 模版多态是属于静态多态还是动态多态
模版多态属于静态多态。
解释:
- 静态多态:是指在编译时就可以决定调用哪一个函数的多态性。模版多态正是通过模版机制,在编译时根据类型参数生成不同的代码,从而实现多态。
- 动态多态:是指在运行时通过虚函数来决定调用哪一个函数。这通常与继承和虚函数配合使用,决定的是实际对象的类型。
静态多态的实现原理:
在C++中,模版多态通过模版函数或者模版类来实现。当模版实例化时,编译器根据传入的具体类型生成不同的代码,这种多态性发生在编译时,因此被称为静态多态。
#include <iostream>
template <typename T>
void print(const T& value) {
std::cout << "Printing value: " << value << std::endl;
}
int main() {
print(42); // T = int
print(3.14); // T = double
print("Hello"); // T = const char*
return 0;
}
在这个例子中,print函数是模版函数,根据传入的类型(比如int,double或者const char*),编译器会在编译时生成不同的函数实例。这种类型的多态属于静态多态。
动态多态与模版多态的区别:
- 动态多态依赖于虚函数和继承,通常是在运行时通过对象的实际类型来决定调用哪一个函数。
6. 构造函数有哪些
构造函数是类中的一种特殊成员函数,用于在创建对象时初始化对象的状态。在C++中,构造函数有几种类型,每一种构造函数的用途不同。下面是几种常见的构造函数类型:
默认构造函数
默认构造函数是没有参数的构造函数,或者即使有参数,也会提供默认值。他用于在创建对象时将对象初始化为默认状态。
class MyClass {
public:
MyClass() {
// 默认构造函数
std::cout << "Default Constructor Called" << std::endl;
}
};
int main() {
MyClass obj; // 调用默认构造函数
return 0;
}
参数化构造函数
参数化构造函数是接受一个或者多个参数的构造函数,他用于根据传入的值初始化对象的状态。参数化构造函数允许你在创建对象时为其提供特定的初始值。
class MyClass {
public:
MyClass(int x, int y) {
// 参数化构造函数
std::cout << "Constructor Called with values: " << x << ", " << y << std::endl;
}
};
int main() {
MyClass obj(10, 20); // 调用参数化构造函数
return 0;
}
拷贝构造函数
拷贝构造函数用于创建一个对象作为另一个同类型对象的副本,他通常在以下几种情况下被调用:
- 当通过值传递对象时
- 当通过值返回对象时
- 当使用同类型对象初始化新对象时
拷贝构造函数是根据已有对象创建新的对象时调用的,他的默认行为是逐成员复制对象,但你也可以定义拷贝构造函数来做深拷贝等操作。
class MyClass {
public:
MyClass(int val) : value(val) {}
MyClass(const MyClass& other) { // 拷贝构造函数
value = other.value;
std::cout << "Copy Constructor Called" << std::endl;
}
private:
int value;
};
int main() {
MyClass obj1(10); // 调用参数化构造函数
MyClass obj2 = obj1; // 调用拷贝构造函数
return 0;
}
移动构造函数
移动构造函数用于将资源从一个对象移动到另一个对象,而不是进行拷贝。移动构造函数的目的是提高性能,避免不必要的资源复制,尤其是当对象拥有动态分配的资源时(比如内存、文件句柄等)。
- 移动构造函数通常会将资源从一个对象转移到另一个对象,而不是做深拷贝。
- 使用std::move来启用移动语义。
7. const修饰的成员函数可以被谁调用(当时脑抽了答错了)
const修饰的成员函数是指在函数声明的末尾加上const关键字,表示该成员函数不会修改对象的状态,也就是他不能修改类的成员变量。const成员函数的作用主要是保障对象在函数调用过程中不被修改。
那么,const修饰的成员函数可以被以下几类调用:
常量对象(const类型的对象)
如果你有一个const类型的对象或者指针,只有const成员函数才能被调用。因为对于常量对象,我们不能通过他来修改任何成员数据。
class MyClass {
public:
void display() const {
// 这里不能修改类的成员变量
std::cout << "Display" << std::endl;
}
};
const MyClass obj;
obj.display(); // 这是合法的,因为 display() 是 const 函数
非常量对象
即使是非常量对象,也可以调用const成员函数。因为const成员函数并不会修改对象的状态,他对普通对象同样是合法的。
MyClass obj;
obj.display(); // 这是合法的
常量指针或者引用指向的对象
如果你通过常量指针或者引用调用成员函数,那么该成员函数也必须是const,否则编译器会报错。
const MyClass* ptr = &obj;
ptr->display(); // 这是合法的,因为 display() 是 const 函数
8. 树怎么用C++代码进行表示
在C++中,树通常可以通过以下几种方式表示。最常见的表示方式是使用节点类和指针来构建树的结构。具体实现方式取决于树的类型和需求。以下是几种常见的树类型的C++实现方式。
二叉树
二叉树是每一个节点最多有两个子节点的树。在C++中,可以通过以下方式表示二叉树:
// 二叉树的节点结构
class TreeNode
{
public:
int value;
TreeNode* left;
TreeNode* right;
TreeNode(int val)
: value(val)
, left(nullptr)
, right(nullptr)
{}
}
// 前序遍历函数
void preorderTraversal(TreeNode* root)
{
if(root == nullptr) return;
cout << root->value << " ";
preorderTraversal(root->left);
preorderTraversal(root->right);
}二叉搜索树
二叉搜索树是一种特定类型的二叉树,其中每一个节点的值大于其左子树的所有节点值,小于右子树的所有节点值。
// 二叉树节点结构
class TreeNode {
public:
int value;
TreeNode* left;
TreeNode* right;
TreeNode(int val) : value(val), left(nullptr), right(nullptr) {}
};
// 插入节点函数
TreeNode* insert(TreeNode* root, int value)
{
if(root == nullptr)
{
return new TreeNode(value);
}
if(value > root->value)
{
root->left = insert(root->left, value);
}
else
{
root->right = insert(root->right, value);
}
return root;
}
// 中序遍历函数(验证树的排序)
void inorderTraversal(TreeNode* root)
{
if(root == nullptr) return;
inorderTraversal(root->left);
cout << root->value << " ";
inorderTraversal(root->right);
}N叉树
N叉树的每一个节点可以有任意数量的子节点。实现时,通常会使用一个存储子节点的容器(比如vector)
// N叉树节点结构
class TreeNode {
public:
int value;
vector<TreeNode*> children;
TreeNode(int val) : value(val) {}
// 添加子节点
void addChild(TreeNode* child) {
children.push_back(child);
}
};
// 遍历N叉树
void preorderTrasal(TreeNode* root)
{
if(root == nullptr) return;
cout << root->value << " ";
for(TreeNode* child : root->children)
{
preorderTrasal(child);
}
}9. 树的遍历有哪些
深度优先遍历
深度优先遍历是通过递归或者栈的方式,从树的跟节点开始,访问每一条路径直到叶子节点,然后回溯到上一个节点继续访问其他路径。
前序遍历
顺序:根 -> 左子树 -> 右子树
树结构:
1
/ \
2 3
/ \
4 5
前序遍历结果: 1 2 4 5 3
中序遍历
顺序:左子树 -> 根 -> 右子树
树结构:
1
/ \
2 3
/ \
4 5
中序遍历结果: 4 2 5 1 3
后序遍历
顺序:左子树 -> 右子树 -> 根
树结构:
1
/ \
2 3
/ \
4 5
后序遍历结果: 4 5 2 3 1
广度优先遍历
广度优先遍历是按照层次进行遍历的,从树的根节点开始,依次访问每一层的所有节点,通常使用队列实现。
顺序:从上到下逐层访问每一个节点
树结构:
1
/ \
2 3
/ \
4 5
层次遍历结果: 1 2 3 4 5
10. 介绍一下入度和出度(图论忘完了)
入度和出度是图论中的两个基本概念,用来描述途中节点和其他节点的关系,特别是在有向图中,入度和出度用来表示节点的连接情况。
入度:
入度是指一个节点被其他节点指向的边的数量。也就是说,入度表示有多少条边指向该节点。
出度:
出度是指一个节点直系那个其他节点的边的数量。出度表示该节点与多少个其他节点有连接。
- 入度:一个节点有多少条边指向它。
- 出度:一个节点指向多少个其他节点。
11. 介绍一下bfs和dfs
这是两种常用的图和树的遍历方法,他们的主要区别在与访问节点的顺序,下面是这两种算法的详细介绍:
广度优先搜索
广度优先遍历是一种层次遍历的方法,他从起始节点开始,首先访问该节点的所有邻居节点,然后再访问这些邻居节点的邻居,以此类推,直到所有节点都被访问过。
在树的情况下,BFS会逐层访问节点,从根节点开始,首先访问根节点的所有子节点,然后访问这些子节点的子节点,依次类推。
过程:
- 使用队列来实现广度优先搜索
- 从起始节点开始,首先将起始节点加入队列,然后开始循环:
- 从队列中取出一个节点并访问它
- 将该节点的未访问的邻居节点加入队列
- 重复直到队列为空
深度优先搜索
DFS是一种深度优先的遍历方法,他从起始节点开始,沿着一条路径一直访问下去,直到访问到没有未访问邻居的节点为止,然后回溯到上一个节点,继续访问其他未访问的邻居,直到所有节点都被访问过了。
DFS可以通过递归进行实现,也可以使用栈来模拟递归过程。
过程:
- 使用栈来实现深度优先搜索
- 从起始节点开始,先访问该节点,再访问他的邻居节点,然后再访问邻居的邻居,依次类推,直到所有节点都被访问。
12. 邻接表和邻接矩阵怎么实现
在图论中,邻接表和邻接矩阵是表示图的两种常见方式。
邻接矩阵
邻接矩阵是一种二维数组,用来表示图中节点之间的连接关系。对于有v个节点的图,邻接矩阵是一个V x V的矩阵,其中martix[i][j]表示从节点i到节点j是否有边。其中有边则为1,否则为0。
class Graph
{
public:
int v; // 节点数量
vector<vector<int>> adjmatric; // 邻接矩阵
// 构造函数
Graph(int v)
{
this->v = v;
adjmatric.resize(v, vector<int>(v, 0)); // 初始化矩阵为0
}
// 添加边
void addEdge(int u, int v)
{
adjmatric[i][j] = 1;
adjmatric[j][i] = 1;
}
// 打印邻接矩阵
void print()
{
for(int i = 0; i < v; i++)
{
for(int j = 0; j < v; j++)
{
cout << adjmatric[i][j] << ' ';
}
cout << endl;
}
}
}邻接表
邻接表使用一个数组或者向量,其中每一个元素是一个链表(或vector)每一个节点的邻接表包含他的所有邻居节点。邻接表更节省空间,特别是在稀疏图中。
class Graph
{
public:
int v; // 节点数量
vector<list<int>> adjList; // 邻接表
// 构造函数
Graph()
{
this->v = v;
adjList.resize(v); // 初始化邻接表
}
// 添加边
void addEdge(int u, int v)
{
adjList[u].push_back(v);
adjList[v].push_back(u);
}
// 打印邻接表
void printGraph() {
for (int i = 0; i < V; i++) {
cout << "Node " << i << ": ";
for (int neighbor : adjList[i]) {
cout << neighbor << " ";
}
cout << endl;
}
}
}- 邻接矩阵:使用一个 V x V 的二维vector<int>来存储每一对节点之间的连接情况。addEdge函数设置相应的矩阵位置为1,表示有边。
- 邻接表:使用一个大小为V的vector<list<int>> 来存储每一个节点的邻居。addEdge函数通过将节点添加到相应的链表中表示边。
选择使用哪一种表示方法??
- 邻接矩阵:适用于图是密集的情况下,即边的数量接近节点数量的平方。他的时间复杂度较高,特别是在查询边是否存在,复杂度是O(1),但是在存储稀疏图时浪费空间。
- 邻接表:适用于图是稀疏的情况。对于大规模稀疏图,邻接表是更高效的选择,他能节省大量空间。查询一个边的存在性需要遍历邻接表,时间复杂度是O(k),其中k是该节点的邻居数量。
13. lambda表达式怎么写,传值的方式有哪些
在C++中,lambda表达式是一种简洁的方式来定义匿名函数。C++11引入了lambda表达式,他可以让你在一个表达式内定义一个函数并立即使用。下面是C++中lambda表达式的基本语法和不同的传值方式。
基本语法
C++中lambda表达式的基本语法如下:
[捕获列表](参数列表) -> 返回类型 {函数体}
- 捕获列表:用于指定外部变量的捕获方式,可以是值捕获或引用捕获
- 参数列表:指定传入lambda函数的参数
- 返回类型:执行lambda表达式的返回类型。通常可以通过auto来推导类型
- 函数体:定义lambda函数的实现
捕获列表
捕获列表指定了lambda表达式如何从外部作用域捕获变量。捕获的方式有几种:
按值捕获 [ = ]
按值捕获会将外部变量的当前值拷贝到lambda表达式内部。
int x = 10;
auto f = [=]() { return x + 1; };
std::cout << f() << std::endl; // 输出 11
按引用捕获 [ & ]
按引用捕获会将外部变量的引用传递给lambda表达式,允许lambda修改外部变量。
int x = 10;
auto f = [&]() { x = x + 1; };
f();
std::cout << x << std::endl; // 输出 11
单独捕获某一个变量
可以只捕获特定的变量,其他变量不被捕获
int x = 10, y = 20;
auto f = [x]() { return x + 1; }; // 只捕获 x
std::cout << f() << std::endl; // 输出 11
按值和按引用混合捕获
可以指定部分变量按值捕获,部分按引用捕获
int x = 10, y = 20;
auto f = [x, &y]() { return x + y; }; // x 按值捕获,y 按引用捕获
y = 30;
std::cout << f() << std::endl; // 输出 40 (x 保持 10, y 修改为 30)
参数列表和返回类型
参数列表
与普通函数一样,lambda表达式也可以接受参数
auto add = [](int a, int b) { return a + b; };
std::cout << add(5, 3) << std::endl; // 输出 8
返回类型
如果lambda表达式有返回值,且返回类型无法推导时,可以显式指定返回类型
auto multiply = [](int a, int b) -> int { return a * b; };
std::cout << multiply(4, 3) << std::endl; // 输出 12
传值的方式
在C++中,lambda表达式传值有两种方式:按值传递和按引用传递
按值传递
如果你希望传入的参数在lambda中不可变,或者你希望捕获外部变量的值,可以按值传递。
auto add = [](int a, int b) { return a + b; }; // 按值传递
std::cout << add(2, 3) << std::endl; // 输出 5
按引用传递
如果你希望传入的参数在lambda中可以修改,或者希望减少不必要的拷贝,可以按引用传递。
auto increment = [](int &a) { a += 1; }; // 按引用传递
int x = 5;
increment(x);
std::cout << x << std::endl; // 输出 6
14. 单例模式的代码编写
单例模式是一种设计模式,目的是确保一个类只有一个实例,并提供全局访问点来获取这个实例。单例模式常用于需要共享资源的场景,比如数据库连接、线程池等。
单例模式的代码实现:
懒汉式单例(线程不安全)
懒汉式单例模式是指在第一次使用单例时才进行创建。为了线程安全,通常需要加锁。
class Singleton
{
private:
static Singleton* instance;
static std::mutex mtx; // 用于加锁的mutex
Singleton() {} // 构造函数私有化,避免外部创建
public:
// 禁止拷贝构造和赋值操作
Singleton(const Singleton&) = delete;
Singleton& operator=(const Singleton&) = delete;
static Singleton* getInstance()
{
// 双重检测锁定,确保线程安全且性能较高
if(instance == nullptr)
{
std::lock_guard<std::mutex> lock(mtx); // 加锁
if(instance == nullptr)
{
instance = new Singleton();
}
}
return instance;
}
}
Singleton* Singlenton::instance = nullptr;饿汉式单例(线程安全)
饿汉式单例模式是在程序启动时就创建单例实例,避免了线程安全问题,但也会导致即使没有使用到单例对象,程序仍然会创建他。
class Singleton
{
private:
static Singleton instance; // 静态成员实例
Singleton() {} // 构造函数私有化,避免外部创建
public:
// 禁止拷贝构造和赋值操作
Singleton(const Singleton&) = delete;
Singleton& operator=(const Singleton&) = delete;
static Singleton& getInstance()
{
return instance;
}
}
Singleton Singleton::instance;15. 工厂模式的代码编写
工厂模式是创建型设计模式的一种,主要用于定义一个创建对象的接口,但是让子类决定实例化哪一个类,工厂模式通常分为三种:简单工厂模式、工厂方法模式和抽象工厂模式。
简单工厂模式
简单工厂模式通过一个工厂类来创建不同类型的对象,客户端无需知道具体的对象创建细节,只需要调用工厂方法即可。
// 产品接口
class Product
{
public:
virtual void doSomething() = 0;
}
// 具体产品A
class ProductA : public Product
{
public:
void doSomething() override {
std::cout << "ProductA doing something!" << std::endl;
}
}
// 具体产品B
class ProductB : public Product
{
public:
void doSomething() override {
std::cout << "ProductB doing something!" << std::endl;
}
}
// 工厂类
class Factory
{
public:
static Product* createProduct(const std::string& type) {
if (type == "A") {
return new ProductA();
} else if (type == "B") {
return new ProductB();
}
return nullptr;
}
}工厂方法模式
工厂方法模式允许子类约定实例化哪一个类。工厂方法由具体的工厂类来实现,父类或者接口只定义了工厂方法的接口,具体的实现由子类来完成。
// 产品接口
class Product {
public:
virtual void doSomething() = 0;
};
// 具体产品类A
class ProductA : public Product {
public:
void doSomething() override {
std::cout << "ProductA doing something!" << std::endl;
}
};
// 具体产品类B
class ProductB : public Product {
public:
void doSomething() override {
std::cout << "ProductB doing something!" << std::endl;
}
};
// 工厂接口
class Creator
{
public:
virtual Product* createProduct() = 0; // 工厂方法
}
// 具体工厂类A
class ConcreteCreatorA : public Creator {
public:
Product* createProduct() override {
return new ProductA();
}
};
// 具体工厂类B
class ConcreteCreatorB : public Creator {
public:
Product* createProduct() override {
return new ProductB();
}
};抽象工厂模式
抽象工厂模式提供了一个接口,用于创建一组相关或者依赖的对象。抽象工厂模式可以让客户不需要指定具体的类,而是通过工厂接口来创建一组相关的产品。
// 抽象产品A
class ProductA {
public:
virtual void doSomethingA() = 0;
};
// 抽象产品B
class ProductB {
public:
virtual void doSomethingB() = 0;
};
// 具体产品A1
class ProductA1 : public ProductA {
public:
void doSomethingA() override {
std::cout << "ProductA1 doing something!" << std::endl;
}
};
// 具体产品A2
class ProductA2 : public ProductA {
public:
void doSomethingA() override {
std::cout << "ProductA2 doing something!" << std::endl;
}
};
// 具体产品B1
class ProductB1 : public ProductB {
public:
void doSomethingB() override {
std::cout << "ProductB1 doing something!" << std::endl;
}
};
// 具体产品B2
class ProductB2 : public ProductB {
public:
void doSomethingB() override {
std::cout << "ProductB2 doing something!" << std::endl;
}
};
// 抽象工厂接口
class AbstractFactory {
public:
virtual ProductA* createProductA() = 0;
virtual ProductB* createProductB() = 0;
};
// 具体工厂1
class ConcreteFactory1 : public AbstractFactory {
public:
ProductA* createProductA() override {
return new ProductA1();
}
ProductB* createProductB() override {
return new ProductB1();
}
};
// 具体工厂2
class ConcreteFactory2 : public AbstractFactory {
public:
ProductA* createProductA() override {
return new ProductA2();
}
ProductB* createProductB() override {
return new ProductB2();
}
};总结:
- 简单工厂模式:通过一个工厂类来创建产品实例,客户端只需要提供产品类型,工厂根据类型返回响应的产品对象。
- 工厂方法模式:将实例化产品的任务交给具体的子工厂类,每一个具体工厂负责创建一种产品。
- 抽象工厂模式: 创建一组相关的产品,每一个具体工厂可以创建一组相关的产品对象。
16. vim 关于文件的一些命令
在vim编辑器中,关于文件的操作非常常见,下面是一些常用的文件相关的命令:
打开文件:
使用vim命令打开文件:
vim 文件路径- 如果文件在当前目录下,可以直接使用文件名:
-
vim myfile.txt - 如果文件在其他目录下,你需要提供完整的路径:
-
vim /path/to/your/file.txt
常见的vim命令:
进入插入模式:按下 i 键进行插入模式,这样可以编辑文件内容
退出插入模式:按下 Esc 键退出插入模式
保存文件:在命令模式下,输入 :w 后按回车保存文件
退出vim:输入 :q 后按回车退出,如果修改了文件但没有保存,可以输入 :wq 来保存并退出,或者 :q! 强制退出不保存。
17. 有向图和无向图怎么表示(看12)
18. 怎么用bfs遍历节点的出度和入度
在C++中,你可以使用广度优先搜索(BFS)来遍历图,并计算每一个节点的入度和出度。以下是如何使用BFS遍历有向图并计算节点的入度和出度:
- 出度:从当前节点出发的边数
- 入度:指向当前节点的边数
19. 智能指针有哪些(比较简单)
20. 进程和线程的区别
在C++中,进程和线程是两种基本的执行单位,他们在程序的执行和资源管理上有明显的区别。以下是进程和线程的主要区别:
定义
进程:进程是操作系统分配资源的基本单位,他是正在运行的程序实。每一个进程有自己的独立内存空间、数据、堆栈等资源。
线程:线程是进程中的执行单元,也叫做轻量级进程。线程共享进程的资源(比如内存空间),但是每一个线程有自己的堆栈和寄存器。
资源隔离
进程:进程之间是相互独立的,每一个进程有独立的地址空间、文件描述符、堆栈等。当一个进程崩溃时,通常不会影响其他进程。
线程:线程之间共享进程的地址空间,意味着同一个进程内的线程可以访问同一块内存。这使得线程之间的通信更加高效,但是也增加了线程间的同步问题。
创建和销毁开销
进程:创建和销毁进程的开销较大,每一个进程都需要操作系统为其分配资源,比如内存、文件描述符等,进程间的切换也相对昂贵。
线程:线程的创建和销毁开销较小,因为线程共享进程的资源。线程切换的开销也比较小。
通信
进程:进程间通信(IPC)需要借助操作系统提供的机制,比如管道、消息队列、共享内存、套接字等。进程间通信比线程间通信要复杂和缓慢。
线程:线程间的通信更为直接,因为他们共享同一个进程的内存。可以通过共享变量、同步机制(比如互斥锁、条件变量等)来进行通信。
调度
进程:操作系统负责调度和管理进程。每一个进程在操作系统的内核中被分配一个时间片来执行。
线程:线程的调度由操作系统的线程调度器负责,线程调度通常比进程调用更高效,因为线程之间的切换开销较小。
崩溃影响
进程:一个进程崩溃不会影响其他进程,其他进程依然可以继续执行。
线程:一个线程崩溃可能会影响同一进程中的其他进程,甚至整个进程的崩溃,因为他们共享相同的内存空间。
并发性
进程:进程之间可以并发执行,操作系统会为每一个进程分配独立的CPU时间。
线程:线程是进程的执行单元,他们可以在同一进程中并发执行,甚至可以利用多核CPU进行并行处理。
使用场景
进程:适合需要完全隔离的任务,例如运行不同的程序或者需要强隔离的应用场景。
线程:适合需要共享数据并且任务比较轻量的并发处理,例如在同一个程序中进行多任务处理。
21. 创建线程的函数(linux和C++)
在C++中创建线程,通常使用POSIX线程(pthreads)或者C++11标准中的std::thread。如果在Linux系统中工作,POSIX线程是更常见的选择,但是C++11引入了std::thread提供了更现代、更简洁的接口。
使用POSIX线程(pthread)创建线程
POSIX线程是一个跨平台的线程库,Linux和其他Unix系统都支持他,你可以通过pthread_create()来说创建线程。
// 线程函数
void* thread_function(void* arg)
{
std::cout << "hello from hread" << std::endl;
return nullptr;
}
int main()
{
pthread_t pthread; // 线程标识符
// 创建线程
if(pthread_create(&thread, nullptr, thread_function, nullptr) != 0)
{
std::cerr << "Error create thread" << std::endl;
return 1;
}
// 等待线程结束
if(pthread_join(thread, nullptr) != 0)
{
std::cerr << "Error joining thread" << std::endl;
return 1;
}
std::cout << "Thread has finished" << std::endl;
return 0;
}pthread_create() 函数用于创建线程,他的参数是:
- thread:线程标识符
- nullptr:线程属性,通常设为nullptr
- thread_function:线程函数的入口
- nullptr:传递给线程函数的入口
pthread_join() 函数用于等待线程结束
使用C++11中std::thread创建线程
C++11引入了std::thread类,简化了多线程编程,推荐在现代C++中使用
// 线程函数
void thread_function() {
std::cout << "Hello from thread!" << std::endl;
}
int main()
{
// 创建线程
std::thread t(thread_function);
// 等待线程结束
t.join();
std::cout << "thread has finished" << std::endl;
return 0;
}std::thread 是C++标准库中提供的线程类,使用时创建std::thread对象并传递要执行的函数
join() 函数用于等待线程结束
22. tcp和udp的区别,在项目中有哪里体现
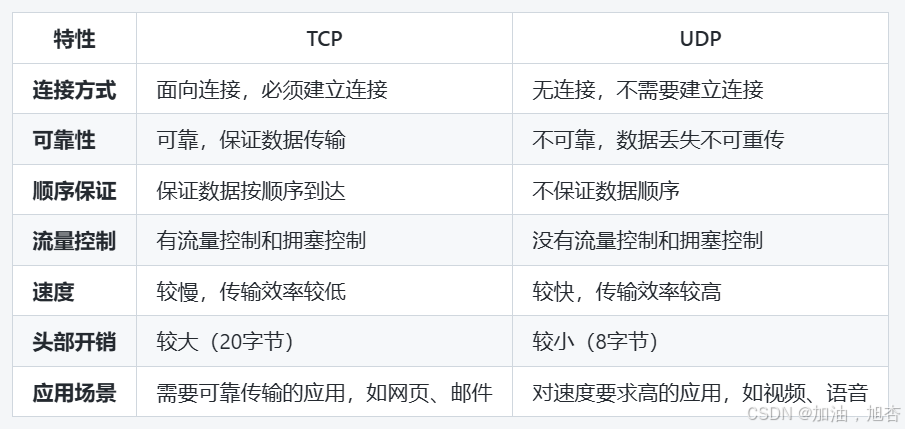
- 基于TCP的协议:常用于需要可靠传输的应用,如Web浏览、文件传输、邮件发送等。
- 基于UDP的协议:常用于需要快速传输但对可靠性要求不高的应用,如视频流、语音通信、在线游戏等。
23. qt的常见控件,怎么实现一个自定义控件
Qt的常见控件
- QPushButton:按钮控件,通常用于触发事件。
- QLabel:标签控件,通常用于显示文本或图像。
- QLineEdit:单行文本框,允许用户输入一行文本。
- QTextEdit:多行文本框,允许用户输入多行文本。
- QComboBox:下拉框,提供多选项的选择。
- QCheckBox:复选框,允许用户选择或取消选择。
- QRadioButton:单选按钮,允许用户在一组选项中选择一个。
- QSlider:滑块控件,允许用户选择一个范围内的值。
如何实现自定义控件
为了实现自定义控件,我们通常需要执行以下步骤:
- 继承自
QWidget或其他控件:我们可以从QWidget或其他现有控件(如QPushButton,QLabel)继承。 - 重写必要的函数:如
paintEvent()用来绘制控件、mousePressEvent()用来处理鼠标事件等。 - 提供自定义功能:比如添加自定义属性、方法,或者通过信号和槽与外部交互。
在项目中用到的控件:
-
按钮 (QPushButton)
用于触发一个事件的按钮。当用户点击按钮时,可以连接到一个槽函数来执行某个操作。 -
标签 (QLabel)
用于显示文本或图像的标签。标签本身不可编辑,但可以用来显示信息或提示。 -
单选按钮 (QRadioButton)
用于在多个选项中进行选择。多个单选按钮通常会被放在一个组内,使得同一时间只能选择一个按钮。 -
窗口 (QMainWindow)
QMainWindow 是一个顶级窗口类,用来创建主窗口。它通常包括菜单栏、工具栏、状态栏等,可以用于创建应用程序的主要界面。 -
对话框 (QDialog)
QDialog 用于创建对话框窗口,可以用于获取用户输入、显示消息或选择操作等。它可以是模态对话框或非模态对话框。 -
下拉框 (QComboBox)
QComboBox 是一个下拉列表框,允许用户从一个预定义的选项列表中选择一个值。可以是单行或多行文本显示。 -
输入框 (QLineEdit)
QLineEdit 用于让用户输入单行文本。它支持多种文本编辑功能,如密码输入、输入限制、文本提示等。 -
日期时间选择控件(QDateTimeEdit)
QDateTimeEdit 是一个日期时间选择控件,允许用户选择日期和时间。它通常以日期和时间格式显示,用户可以通过下拉框或直接输入来选择。 -
编辑多行纯文本的控件(QPlainTextEdit)
QPlainTextEdit 是一个用于编辑多行纯文本的控件,适用于需要显示和编辑大量文本的应用场景。它支持高效的文本处理和高亮显示。
24. inline,explicit关键字
inline 关键字
inline 关键字主要用于函数定义中,他的目的是请求编译器在调用该函数时,将函数体的代码直接插入到调用处,而不是通过常规的函数调用机制(即栈帧管理等)。这有助于减少函数调用的开销,尤其是对于那些非常短小的函数。
特点:
- 提高效率:通过将函数体内联到调用点,避免了函数调用时的栈管理、参数传递等开销。
- 减少函数调用的开销:对于简单的小函数,内联可以提高性能。
- 函数体较小的场景:通常内联函数都是短小的函数,因为对于大的函数,内联会使代码膨胀,反而减低效率。
使用场景:
- 内联函数通常用于小型函数,比如getter/setter、简单的数学运算等
- 编译器有时会忽略inline关键字,尤其是当函数体比较大时,编译器可能不会内联函数,尽管我们用来inline
inline int add(int a, int b) {
return a + b;
}
int main() {
int sum = add(3, 4); // 编译器可能将这个调用内联
return 0;
}
注意事项:
- 使用inline关键字时要小心,因为如果函数太大,内联可能导致代码膨胀(即使增加了内存消耗,反而可能导致性能下降)
- 递归函数通常不适合内联,因为他可能导致无限递归展开
- inline是在编译阶段
explicit 关键字
explicit 关键字用于构造函数或者转换构造函数中,目的是避免隐式类型转换。C++中如果没有显式指定构造函数或者转换函数,编译器会自动尝试进行类型转换(隐式转换),然而,在某种情况下,这种隐式转换是不希望发生的,explicit就是用来阻止这种隐式转换的。
特点:
- 防止隐式类型转换:当构造函数或者转换函数标记为
explicit时,编译器不会在不明确要求的情况下执行该函数进行类型转换。 - 只允许显式调用:使用
explicit的构造函数只能通过显式地调用(或者通过强制转换)来进行类型转换,而不能自动进行隐式转换。
使用场景:
- 主要用于避免一些可能引起误解的隐式转换,尤其是当构造函数或转换函数有单一参数时,防止错误地进行类型转换。
- 对于只有一个参数的构造函数,C++ 编译器可能会把它当作隐式转换运算符来使用,因此需要显式地用
explicit来防止。
class MyClass {
public:
explicit MyClass(int x) {
// 构造函数
}
};
int main() {
MyClass obj1 = 10; // 错误:无法进行隐式转换
MyClass obj2(10); // 正确:显式调用构造函数
return 0;
}
注意事项:
- 使用
explicit时,必须明确调用构造函数,不能依赖编译器自动进行类型转换。
25. const 修饰成员函数
在 C++ 中,const 可以用于修饰成员函数,表示该成员函数不会修改对象的成员变量。通过在成员函数的声明和定义中使用 const,可以确保该函数不会改变对象的状态,并且在调用该函数时,编译器会对其进行相应的限制,防止不小心修改对象的状态。
const修饰成员函数的基本语法
class MyClass {
public:
void myFunction() const; // 常成员函数声明
};
常成员函数的定义
当你在成员函数的声明中使用const,这表示该成员函数不会修改类的任何非mutable成员变量,也不能调用其他非const成员函数。
class MyClass {
private:
int value;
public:
MyClass(int v) : value(v) {}
// 常成员函数,不允许修改成员变量
int getValue() const {
return value;
}
// 非常成员函数,可以修改成员变量
void setValue(int v) {
value = v;
}
};
常成员函数的要求
- 不能修改对象的状态:常成员函数不能修改任何非mutable成员变量。他们只能调用其他成员函数或者修改mutable成员变量。
- 只能调用常成员函数:常成员函数只能调用其他的常成员函数,不能调用任何非const成员函数。
const成员函数的实际应用
- 访问器函数(Getter):通常我们会使用
const来修饰那些只读取数据、不修改数据的函数。 - 避免不小心修改对象:通过将某些成员函数标记为
const,可以在编译时避免不小心修改对象的状态。
#include <iostream>
class MyClass {
private:
int value;
public:
// 构造函数
MyClass(int v) : value(v) {}
// 常成员函数:不能修改成员变量 value
int getValue() const {
return value; // 只读取,不修改
}
// 非常成员函数:可以修改成员变量 value
void setValue(int v) {
value = v; // 修改值
}
// 常成员函数,修改的是 mutable 成员变量
void increment() const {
// value++; // 错误!常成员函数不能修改非 mutable 成员变量
++value; // 不能在常成员函数中直接修改成员变量
}
// 使用 mutable 修饰的成员变量
void changeValue() const {
value = 42; // OK,mutable 变量可以在常成员函数中修改
}
};
int main() {
MyClass obj(10);
std::cout << "Initial value: " << obj.getValue() << std::endl;
// 调用常成员函数
obj.setValue(20);
std::cout << "Updated value: " << obj.getValue() << std::endl;
return 0;
}
26. gitee和github的区别
26. 用过哪些ai
27. 常见的算法有哪些
常见的算法有很多,按照不同的分类方式,可以分为排序算法,查找算法,图算法,动态规划,贪心算法等。
排序算法:
排序算法用于将一个数据集合按照一定的顺序(通常是升序或降序)排列。
- 冒泡排序 (Bubble Sort): 通过反复比较相邻元素并交换它们的位置,直到整个序列有序。
- 选择排序 (Selection Sort): 每次从未排序的部分选择最小(或最大)元素,并将其放到已排序部分的末尾。
- 插入排序 (Insertion Sort): 每次将一个元素插入到已排序部分的正确位置。
- 归并排序 (Merge Sort): 使用分治法,将数组分为两半,分别排序后再合并。
- 快速排序 (Quick Sort): 使用分治法,选择一个基准元素,将数组分成两部分,分别排序后再合并。
- 堆排序 (Heap Sort): 利用堆数据结构,每次选择堆顶元素,构建有序序列。
- 希尔排序 (Shell Sort): 是插入排序的改进版,通过逐步缩小步长来插入排序。
查找算法:
查找算法用于从数据中查找目标元素。
- 线性查找 (Linear Search): 从头到尾逐一检查每个元素,直到找到目标元素。
- 二分查找 (Binary Search): 假设数据已经排序,通过不断将搜索范围折半来查找目标元素。
图算法:
图算法用于处理图结构的数据,常见的有以下几种:
- 深度优先搜索 (DFS): 从一个起始节点开始,沿着图的边深入到无法继续的节点,再回溯到未访问过的节点。
- 广度优先搜索 (BFS): 从一个起始节点开始,访问所有相邻节点,再访问这些节点的相邻节点,直到遍历完所有节点。
- Dijkstra 算法: 用于计算从一个起始节点到图中所有其他节点的最短路径。
- Bellman-Ford 算法: 用于计算带权图中从起始节点到所有其他节点的最短路径,能处理负权边。
- Floyd-Warshall 算法: 用于计算所有节点对之间的最短路径。
- Kruskal 算法: 用于寻找最小生成树(MST),通过逐步选择边来连接图中的所有节点。
- Prim 算法: 也是用于寻找最小生成树(MST),从一个节点开始,逐步扩展生成树。
动态规划:
动态规划算法通过将大问题拆解为小问题,并利用子问题的解来求解大问题,常用于优化问题。
- 斐波那契数列 (Fibonacci Sequence): 通过递推关系计算斐波那契数列中的第 n 项。
- 背包问题 (Knapsack Problem): 给定一组物品,每个物品都有重量和价值,求在给定的重量限制下,如何选择物品使得总价值最大。
- 最长公共子序列 (LCS): 在两个字符串中,找到最长的公共子序列。
- 最长递增子序列 (LIS): 在给定的序列中,找到最长的递增子序列。
- 矩阵链乘法 (Matrix Chain Multiplication): 给定一组矩阵,计算出最优的矩阵链乘法顺序。
贪心算法:
贪心算法在每一步都选择当前状态下最优的选择,期望通过局部最优的选择得到全局最优解。
- 贪心选择活动 (Activity Selection Problem): 给定一组活动的开始和结束时间,选择最多的互不重叠的活动。
- 霍夫曼编码 (Huffman Coding): 用来构建最优的前缀编码(常用于数据压缩)。
- 硬币找零问题 (Coin Change Problem): 给定若干种面额的硬币,求最少的硬币数来构成一个特定的金额。
分治算法:
分治算法通过将问题分解为多个子问题,分别解决子问题,再将结果合并得到原问题的解。
- 归并排序 (Merge Sort): 使用分治法将数组分为两半,分别排序后再合并。
- 快速排序 (Quick Sort): 选择一个基准元素,将数组分成两部分,分别排序后再合并。
- 大整数乘法 (Karatsuba Algorithm): 用分治法进行大整数的乘法运算。
回溯算法:
回溯算法用于寻找所有可能的解,通常在解决组合问题时使用。
- N 皇后问题 (N-Queens Problem): 放置 N 个皇后,使得它们之间不互相攻击。
- 数独 (Sudoku): 在数独棋盘上填充数字,满足行、列和宫内的约束条件。
- 组合求解 (Combinatorial Problem Solving): 如求解所有组合、排列问题。
位运算:
位运算是直接对整数的二进制表示进行操作,效率非常高。
- 计算整数的二进制中 1 的个数 (Hamming Weight): 统计二进制中 1 的个数。
- 判断一个整数是否是 2 的幂: 通过位运算判断。
- 按位与、按位或、按位异或:用来处理二进制数据,常用于加密、压缩等。
28. 分治和动态规划的区别
分治法和动态规划都是常见的算法设计技巧,他们的目的是通过将问题分解成更小的子问题来解决复杂的问题。尽管它们有相似之处,但它们的核心思想和应用场景存在一些明显的区别。下面是它们的主要区别:
核心思想
-
分治法(Divide and Conquer):
- 分治法的核心思想是将一个大问题分解成多个小的子问题,递归地求解这些子问题,然后将子问题的结果合并成原问题的解。
- 每个子问题相互独立,没有重复的子问题。
-
动态规划(Dynamic Programming, DP):
- 动态规划的核心思想是将问题拆解成多个子问题,并且这些子问题是重叠的(即子问题之间存在重复)。通过保存已经解决的子问题的解,避免重复计算,从而提高效率。
- 动态规划通常用于优化问题(例如最短路径、最大值等),它通过记忆化或表格法(自底向上)来存储中间结果。
子问题的重叠性
-
分治法:子问题通常是互不重叠的,分治法是“递归分解问题”,每个子问题被单独解决,且不需要重复计算。
- 例如,归并排序和快速排序就是典型的分治算法,分解后的子问题是独立的。
-
动态规划:子问题通常是重叠的,即不同的子问题之间有很多相同的部分需要重新计算。动态规划通过保存子问题的解来避免重复计算。
- 例如,斐波那契数列、背包问题和最短路径问题都是动态规划的经典应用
是否需要保存中间结果
-
分治法:通常不需要保存子问题的解,子问题的解直接合并得到最终结果。
- 例如,在快速排序中,分治法递归地划分数组,不需要存储中间的排序状态。
-
动态规划:需要保存子问题的解,通常通过记忆化递归或表格法来存储每个子问题的结果,以便后续使用。
- 例如,在计算斐波那契数列时,动态规划会保存已计算的结果,以避免重复计算。
时间复杂度
-
分治法:分治法的时间复杂度通常较高,特别是当子问题之间存在重叠时。例如,分治法的经典例子“归并排序”或“快速排序”,它们的复杂度通常是 O(n log n)。
-
动态规划:由于动态规划通过缓存中间结果来避免重复计算,它的时间复杂度通常比分治法要低,尤其是在子问题重叠的情况下。例如,背包问题的动态规划解法比简单的递归解法要快很多,时间复杂度通常是 O(n * W),其中 n 是物品数,W 是背包的最大容量。
是否适用递归
-
分治法:通常采用递归实现。问题被分解成小的子问题,通过递归来解决这些子问题。
-
动态规划:可以通过递归(带记忆化)或者迭代(自底向上)来实现。通常使用自底向上的方式,通过填充一个表格来存储结果。
29. 贪心的思路是什么
贪心算法是一种在每一步选择中都采取当前状态下最优的选择,从而期望通过局部最优解达到全局最优解的算法。他的基本思想是:在解决问题时,总是选择当前最优的选项,而不考虑未来的选择。这种策略往往能在许多实际问题中找到近似最优解,甚至在某些情况下能得到全局最优解。
贪心算法的基本特点:
- 局部最优选择:每次做出选择时,都会选择当前最优的选项,而不考虑之后的情况。
- 无法回退:一旦做出了某个选择,就无法回到之前的状态。也就是说,贪心算法在选择时不会回溯。
- 全局最优解的保证:并不是所有问题都能通过贪心算法找到全局最优解,但在某些问题中,贪心策略可以得到全局最优解。
贪心算法的应用前提:
- 问题可以分解为子问题:每一个局部最优的选择都能影响整体问题的最优解。
- 具有“贪心选择性质”:通过局部最优的选择能够得到全局最优解,保证每次选择都朝着最优解逼近。
- 具有“最优子结构”:问题的最优解可以通过子问题的最优解来构造。
贪心算法的步骤:
- 选择贪心策略:决定每一步的最优选择。
- 可行性检查:确保所做的选择是符合问题约束的。
- 实现选择并更新状态:将当前最优选择加入解中,并更新问题的状态。
- 重复步骤1-3直到达到终止条件。
30. Qt的信号槽原理
Qt 的信号槽机制是其核心特性之一,广泛用于事件驱动的编程。它允许对象之间通过 信号 和 槽 进行通信,而不需要它们彼此了解对方的具体实现。信号和槽机制是 Qt 实现对象间松耦合通信的方式,是基于事件和回调的思想。
基本概念
- 信号(Signal):一个对象发出的事件或状态变化的通知。信号是一个特殊的成员函数,不能带有函数体,只能在类声明中声明。
- 槽(Slot):一个对象接收到信号后的反应处理。槽也是一个普通的成员函数,可以接受信号发出的数据并进行处理。
- 连接(Connect):将一个信号和一个槽连接起来,使得当信号发出时,槽会被自动调用。
信号和槽的工作原理
- 信号是由对象发出的,通常在某些事件发生时触发。例如,按钮被点击时会发出一个
clicked信号。 - 槽是一个普通的成员函数,用来响应信号。槽函数会在信号发出时自动被调用,并处理相关的操作。
信号和槽的工作过程
-
信号发射:对象会发出一个信号,信号一般是通过某些事件的触发,如用户点击按钮、修改数据等。
-
信号连接:信号和槽通过
QObject::connect()方法连接 -
槽执行:当信号发出时,Qt 会自动调用与该信号连接的槽。
信号和槽的连接方式
在 Qt 中,信号和槽的连接方式有几种:
-
默认连接:信号和槽通过
SIGNAL()和SLOT()宏进行连接,Qt 会自动处理连接。 -
直接连接(默认方式):信号直接调用槽。适用于信号和槽处于同一线程时。
-
队列连接:信号和槽在不同线程之间通信时,Qt 会将信号排入事件队列,并在目标线程中执行槽。这是线程安全的。
-
自动连接:Qt 通过
QMetaObject::connect()动态连接信号和槽。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











