






首先创建这4个项目
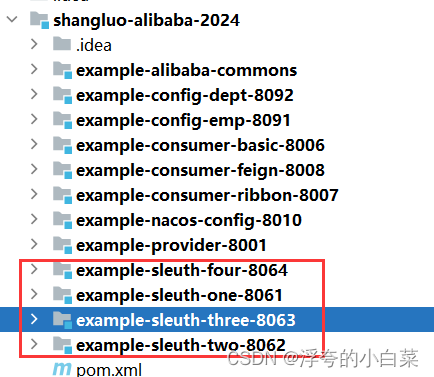
它们之间的调用关系如下:1调用2,2调用3和4
下面是8061端口sleuth的日志信息

下面是8062端口sleuth的日志信息

下面是8063端口sleuth的日志信息

下面是8064端口sleuth的日志信息

可以看出它们的第二个trace(链路的id)是一致的,第三个spanId(块id)不一致,这样看有点麻烦。
所以下面引出ZipKin用图形界面化工具把这个展示出来
ZipKin链接:https://pan.baidu.com/s/15usJnSQ4tWgPTkJravEbWw?pwd=1234
提取码:1234
将下载完成后的ZipKin的jar包上传至linux中,如下图:
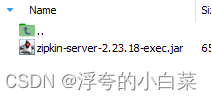
启动ZipKin(端口号9411)服务端,下面为启动命令
java -jar zipkin-server-2.23.18-exec.jar
启动成功后,界面是这样的(linux环境中必须有JDK)
启动成功后通过浏览器访问,输入以下网址:你的Linux虚拟机地址:9411就可以访问了,以我的为例,进去之后是这样的
想让你的项目用到这个zipkin还需要再每个项目的pom.xml加入下面依赖
<!-- 添加zipkin依赖包 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
<version>2.2.8.RELEASE</version>
</dependency>
然后再你的每个配置文件(application.yml)中添加如下配置:这里的地址是你linux的地址
spring:
zipkin:
base-url: http://192.168.242.128:9411/ #zipkin server的请求地址
discovery-client-enabled: false #让zipkin把它当成一个URL,而不要当作服务名
sleuth:
sampler:
probability: 1.0 #采样百分比
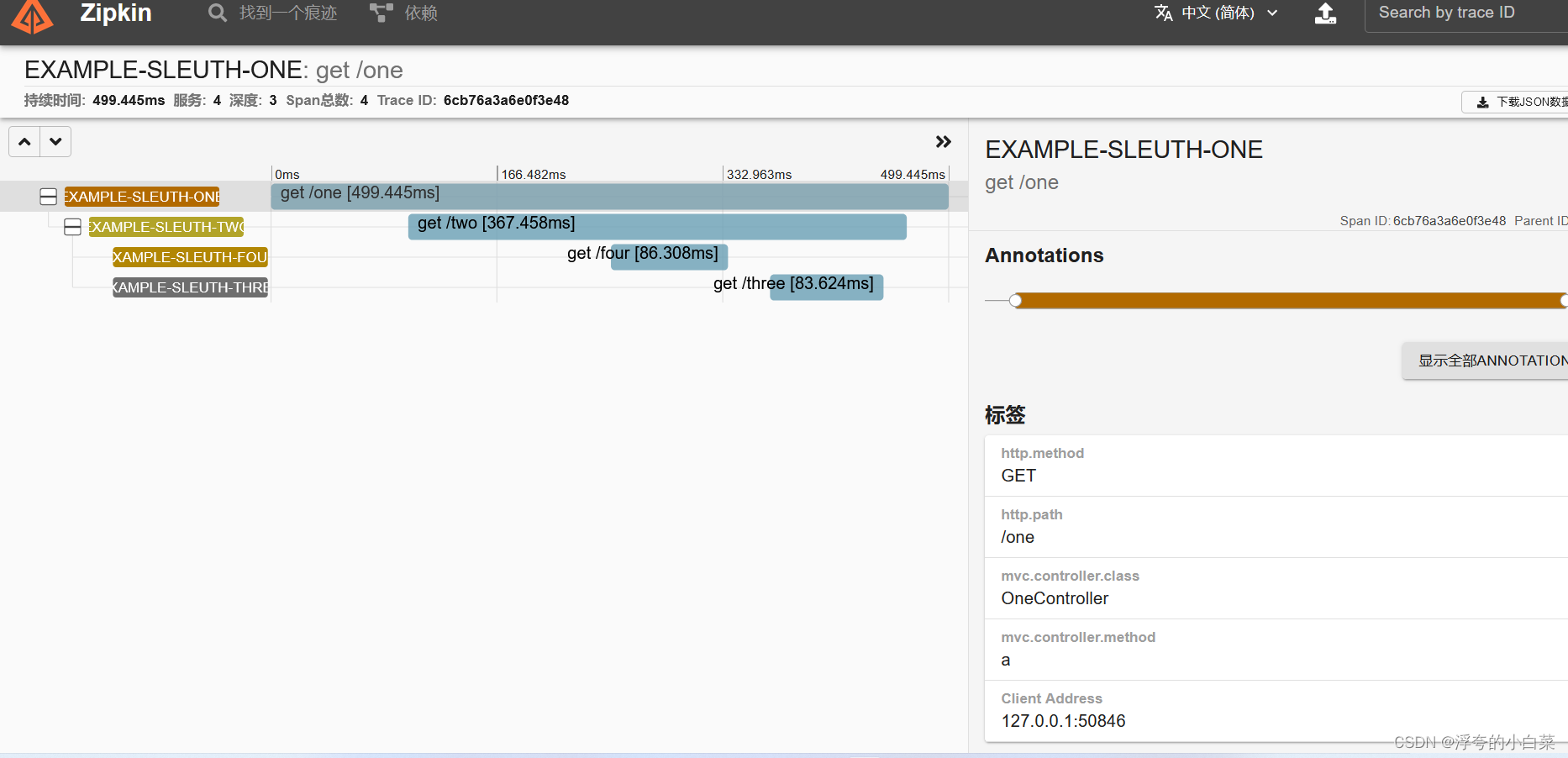
然后重新启动这几个服务后,然后再次项目之间的请求后,然后登录zipkin查看,下面是我的

















 1783
1783

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









