





背景
一个系统页面上的按钮点击到结果反馈,在微服务框架里,是由N个服务组成返回结果,中间可能经过a->b->c->b->a,或a->b->a->c等等简单或复杂重复的服务调用,如果调用链路某一节点出错导致服务崩溃,将无法快速定位问题解决。
在大规模分布式与微服务集群下,出现问题时,需要:
1、可实时观察系统整理调用链路情况
2、快速发现并定位问题
3、精准判断故障对系统的影响范围和程度
4、梳理服务之间的依赖关系,并判断依赖关系是否合理是否可优化
5、精准分析调用链的性能瓶颈以及容量规划
以上分布式链路追踪技术可以解决的问题,分布式链路追踪(Distributed Tracing),就是将一次分布式请求还原成调用链路,进行日志记录,性能监控并将一次分布式请求的调用情况集中展示。比如各个服务节点上的耗时、请求具体到达哪台机器上、每个服务节点的请求状态等等。
Micrometer
springcloud 对分布式链路追踪提供了支持:Spring Cloud Sleuth 为分布式跟踪提供 Spring Boot 自动配置,但目前Spring Cloud Sleuth 的最后一个次要版本是 3.1,已停止更新,以后使用推荐 Micrometer Tracing
Micrometer与ZipKin之间的关系
可能会有同志们在想,既然有了Micrometer作为链路追踪,那么还要ZipKin干嘛?
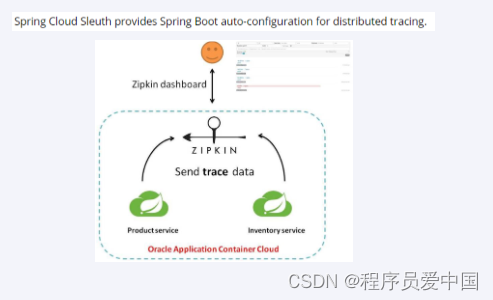
看以上图,可理解为,Micrometer作为链路追踪可以采集到整条完整链路的所有请求信息,但是以数据方式呈现在日志当中,虽然也可以直接观看,但想要更客观统计和分析,仍然有局限性。ZipKin支持接入Micrometer的数据,作为仪表板,可以清晰看见每条链路的请求响应数据。
专业术语
Span:基本工作单位。例如,发送 RPC 是一个新的跨度,向 RPC 发送响应也是如此。跨度还包含其他数据,例如描述、时间戳事件、键值注释(标记)、导致这些值的跨度的 ID 以及进程 ID(通常为 IP 地址)
Trace:形成树状结构的一组跨度。例如,如果运行分布式大数据存储,则 PUT 跟踪可能由请求形成。
Annotation/Event:用于及时记录事件的存在。
Tracer:处理跨度生命周期的库。它可以通过报告器/导出器创建、启动、停止和报告跨度到外部系统。
Tracing context:要使分布式跟踪正常工作,跟踪上下文(跟踪标识符、跨度标识符等)必须通过进程(例如通过线程)和网络传播。
Log correlation:跟踪上下文的某些部分(例如跟踪标识符、跨度标识符)可以填充到给定应用程序的日志中。然后,可以将所有日志收集到单个存储中,并通过跟踪 ID 对它们进行分组。这样,就可以从按时间顺序排列的所有服务中获取单个业务操作(跟踪)的所有日志。
Latency analysis tools:收集导出的跨度并可视化整个跟踪的工具。允许轻松分析延迟。
分布式链路追踪原理
见上图,分布式链路追踪是怎么知道服务的上游和下游是谁呢?
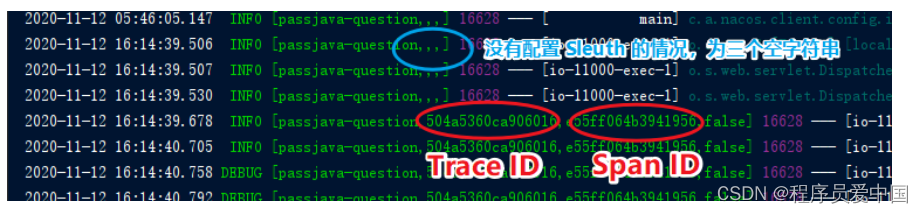
那么一条链路追踪会在每个服务调用的时候加上Trace ID(全局唯一id) 和 Span ID(每次请求的id)
链路通过TraceId唯一标识,
Span标识发起的请求信息,各span通过parent id 关联起来 (Span:表示调用链路来源,通俗的理解span就是一次请求信息)
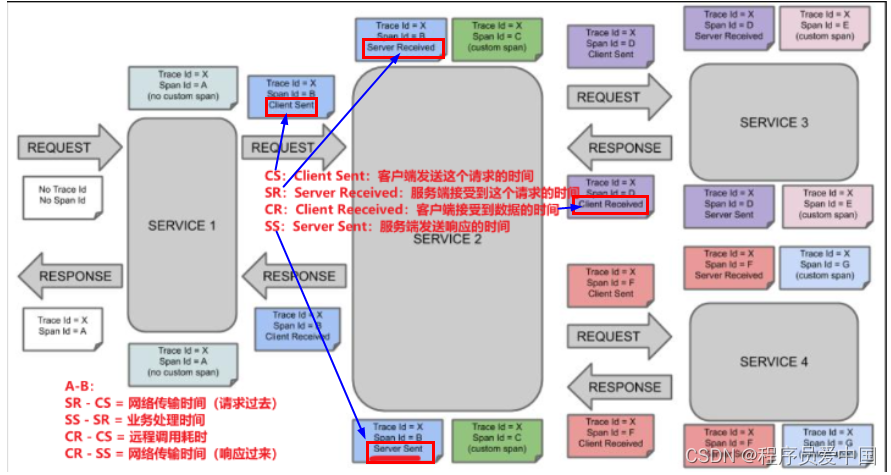
简单来说
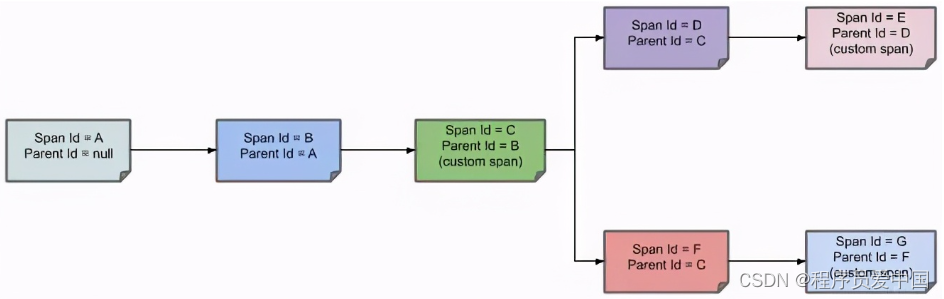
第一个节点:Span ID = A,Parent ID = null,Service 1 接收到请求。
第二个节点:Span ID = B,Parent ID= A,Service 1 发送请求到 Service 2 返回响应给Service 1 的过程。
第三个节点:Span ID = C,Parent ID= B,Service 2 的 中间解决过程。
第四个节点:Span ID = D,Parent ID= C,Service 2 发送请求到 Service 3 返回响应给Service 2 的过程。
第五个节点:Span ID = E,Parent ID= D,Service 3 的中间解决过程。
第六个节点:Span ID = F,Parent ID= C,Service 3 发送请求到 Service 4 返回响应给 Service 3 的过程。
第七个节点:Span ID = G,Parent ID= F,Service 4 的中间解决过程。
通过 Parent ID 就可找到父节点,整个链路即可以进行跟踪追溯了。
ZipKin
Zipkin 是一个分布式跟踪系统。它有助于收集解决服务架构中的延迟问题所需的计时数据。功能包括此数据的收集和查找。
如果日志文件中有跟踪 ID,则可以直接跳转到该 ID。否则,您可以根据服务、操作名称、标签和持续时间等属性进行查询。将为您总结一些有趣的数据,例如在服务中花费的时间百分比,以及操作是否失败。
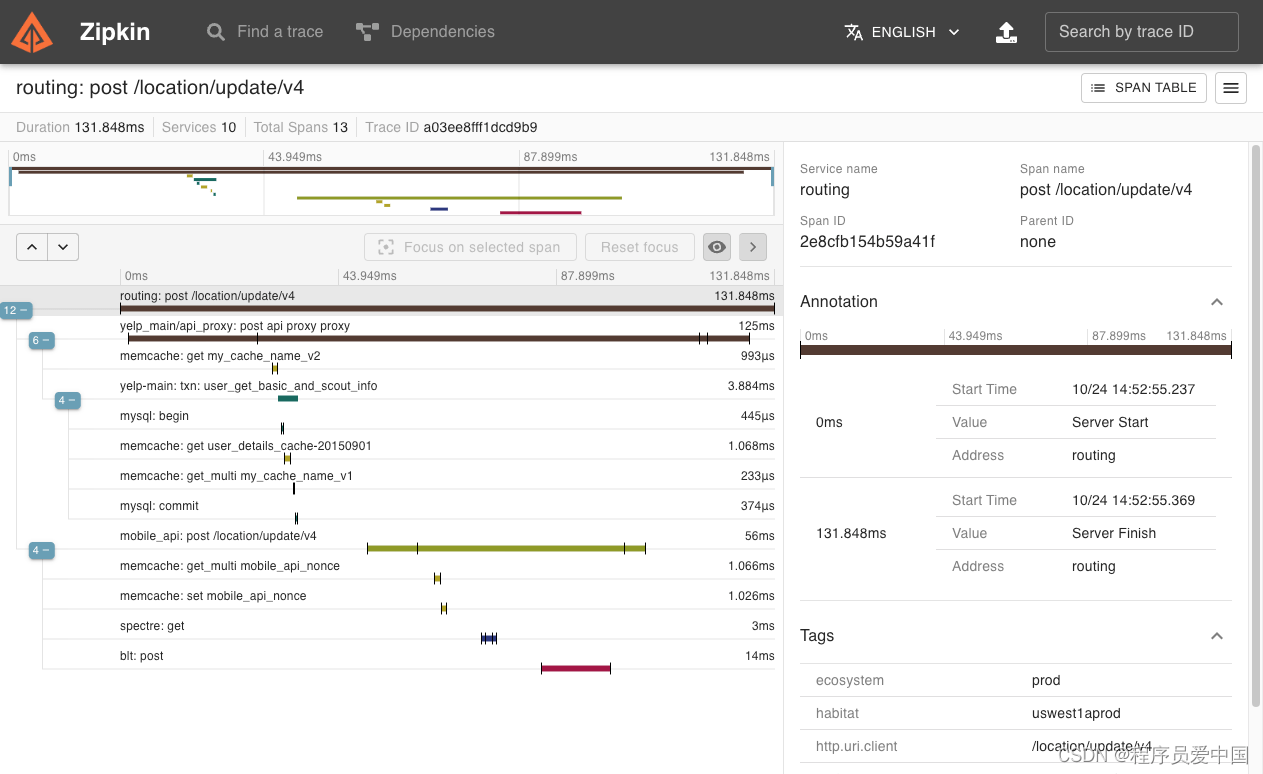
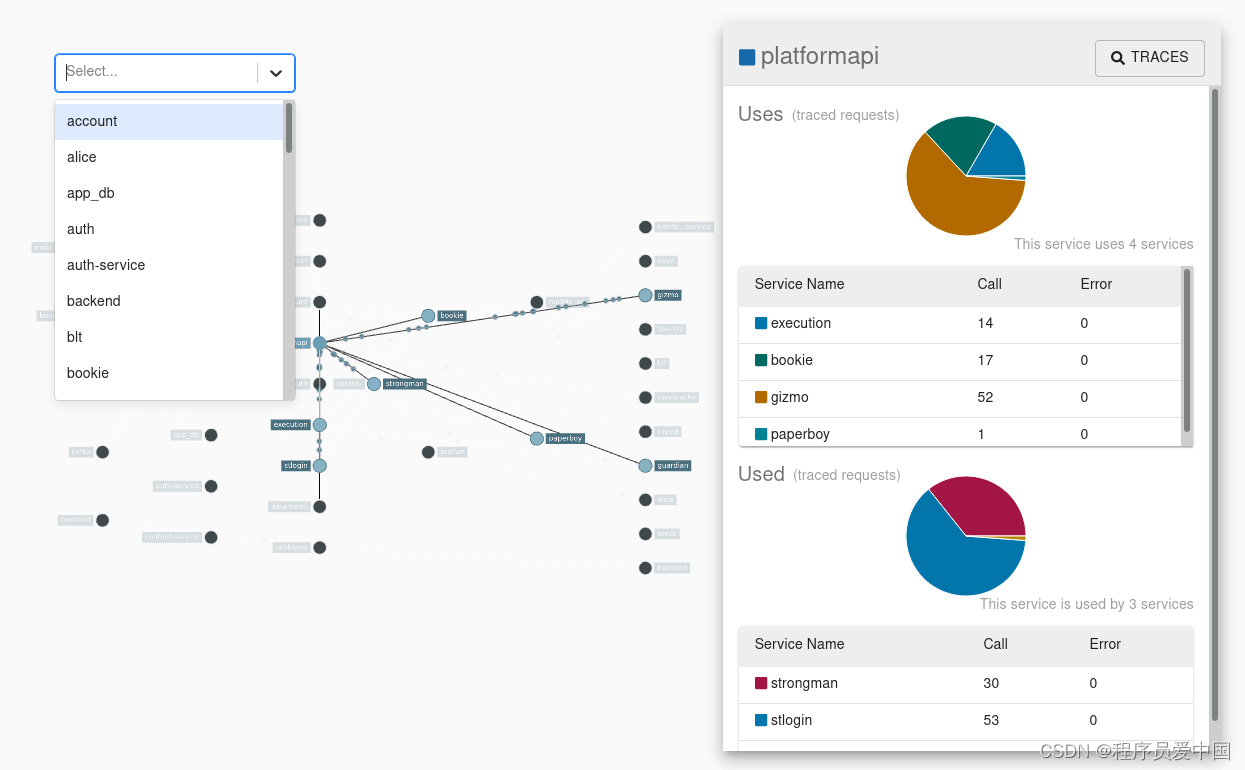
Zipkin UI 还显示一个依赖关系图,显示每个应用程序经过的跟踪请求数。这有助于识别聚合行为,包括错误路径或对已弃用服务的调用。
安装下载
官方支持三种安装下载:Java、Docker 或从源代码运行。
java下载:https://zipkin.io/pages/quickstart
下载完成后运行jar
java -jar zipkin-server-3.0.0-rc0-exec.jar
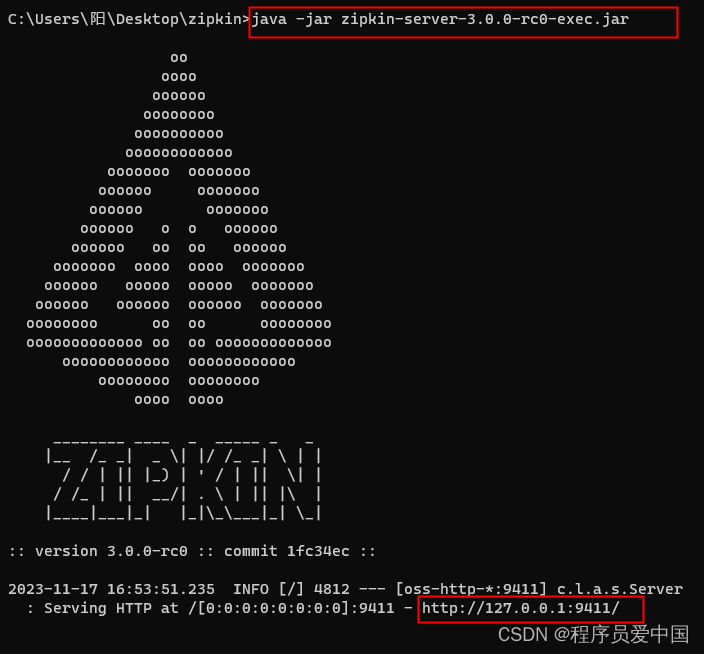
启动完成之后访问http://your_host:9411,成功
Micrometer+ZipKin 案例演示
Micrometer+ZipKin两者各自分工
- Micrometer:数据采集
- ZipKin:图形展示
本案例采用两个服务模块演示,a服务提供者、b服务调用者
总父工程pom依赖引入
<properties>
<micrometer-tracing.version>1.2.0</micrometer-tracing.version>
<micrometer-observation.version>1.12.0</micrometer-observation.version>
<feign-micrometer.version>12.5</feign-micrometer.version>
<zipkin-reporter-brave.version>2.17.0</zipkin-reporter-brave.version>
</properties>
<!--micrometer-tracing-bom导入链路追踪版本中心 1-->
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-tracing- 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1881
1881

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









