




【精选优质专栏推荐】
- 《AI 技术前沿》 —— 紧跟 AI 最新趋势与应用
- 《网络安全新手快速入门(附漏洞挖掘案例)》 —— 零基础安全入门必看
- 《BurpSuite 入门教程(附实战图文)》 —— 渗透测试必备工具详解
- 《网安渗透工具使用教程(全)》 —— 一站式工具手册
- 《CTF 新手入门实战教程》 —— 从题目讲解到实战技巧
- 《前后端项目开发(新手必知必会)》 —— 实战驱动快速上手
每个专栏均配有案例与图文讲解,循序渐进,适合新手与进阶学习者,欢迎订阅。
文章目录

前言
毫无疑问,搜索是计算机中最基础的问题之一。无论我们是在电脑上查找文件,在 Google 上搜索信息,还是使用简单的 find 命令,实际上都是在依赖某种形式的搜索引擎。
过去,大多数方法都是基于关键词搜索。但随着语言和数据的发展,这些方法逐渐显得力不从心。它们通过统计某个词出现的频率以及该词在整个数据集中出现的稀有程度来对文档进行排序,但这种方法非常字面化。举个例子,如果我们搜索“汽车维修”,而文档中写的是“车辆保养”,系统可能完全找不到结果,因为关键词没有完全匹配。
用户的表达与实际意图之间的这种差距,催生了能够理解不同语境的更智能的搜索系统,这就是向量搜索的作用所在。
你可能最近才开始听说向量搜索,尤其是在 RAG 兴起之后,但它其实已经存在相当长一段时间。向量搜索不是匹配精确词语,而是匹配意义。它将查询和文档都转换为数值向量——高维数组,用以捕捉文本的语义精髓。然后,它在向量空间中找到最接近查询向量的向量,返回语境相关的结果,而不仅仅是关键词相似的结果。你会在很多地方看到这种解释,但很少有人讲它的底层实现。
本文将带你完成从生成向量表示到使用余弦相似度搜索的每一步,我们甚至会可视化背后的过程。到最后,你不仅能理解向量搜索的工作原理,还会得到一个可以进一步开发的可用实现。
向量搜索是如何工作的?
从核心上讲,向量搜索包括三个步骤:
1.向量表示:
使用词嵌入或神经网络等技术,将数据(如文本、图像)转换为数值向量。每个向量在高维空间中表示数据的特征。
2.相似度计算:
使用余弦相似度或欧氏距离等指标,衡量查询向量与数据集中其他向量的“接近程度”。向量越接近,表示相似度越高。
3.检索:
根据相似度分数返回前 k 个最相似的项。
例如,如果我们搜索关于“机器学习”的文档,查询“机器学习”会被转换为向量,系统会找到与之最接近的文档向量,即使这些文档使用的是“人工智能”或“深度学习”等相关术语。
接下来,我们将在 Python 中从零构建一个向量搜索系统。我们将使用一个句子的小型数据集,将其转换为向量(为简化起见,使用词向量的简单平均),并实现一个搜索功能。同时,我们还会可视化向量,以观察它们在空间中的聚类情况。
步骤 1:设置环境
为了简化操作,我们将使用 NumPy 进行向量运算,Matplotlib 用于可视化。为了让教程易懂,我们不会使用 FAISS 或 spaCy 等外部库。
对于向量表示,我们将用一个小型预定义字典来模拟词嵌入,但在实际应用中,我们会使用 Word2Vec、GloVe 或 BERT 等模型。
先安装所需的包(如果尚未安装),并导入模块:
import numpy as np
import matplotlib.pyplot as plt
from collections import defaultdict
import re
# 使用 NumPy 进行向量计算
# 使用 Matplotlib 进行绘图
# 使用 Python 基础功能处理文本
# 使用 re 模块用于分词
步骤 2:创建示例数据集和词嵌入
本教程将使用一个关于科技的小型句子数据集。为了将单词表示为向量,我们创建一个简化的词嵌入字典,每个单词映射到一个二维向量(便于可视化)。这些向量是任意的,但设计上会将相关词聚集在一起(例如,“machine”和“neural”靠得很近)。
# 示例句子数据集
documents = [
"Machine learning is powerful",
"Artificial intelligence advances rapidly",
"Deep learning transforms technology",
"Data science drives innovation",
"Neural networks power AI"
]
# 简化的二维词嵌入(实际中使用预训练嵌入)
word_embeddings = {
"machine": [0.8, 0.2],
"learning": [0.7, 0.3],
"powerful": [0.6, 0.4],
"artificial": [0.9, 0.1],
"intelligence": [0.85, 0.15],
"advances": [0.5, 0.5],
"rapidly": [0.4, 0.6],
"deep": [0.75, 0.25],
"transforms": [0.65, 0.35],
"technology": [0.7, 0.4],
"data": [0.3, 0.7],
"science": [0.35, 0.65],
"drives": [0.4, 0.6],
"innovation": [0.45, 0.55],
"neural": [0.8, 0.2],
"networks": [0.78, 0.22],
"power": [0.6, 0.4],
"ai": [0.9, 0.1]
}
步骤 3:将句子转换为向量
为了搜索文档,我们需要将每个句子转换为单一向量。一个简单的方法是对句子中所有单词的向量取平均(在分词并去除停用词后)。这可以捕捉句子的“平均含义”。如果某个单词不在 word_embeddings 中,则使用零向量。
def tokenize(text):
"""将文本转换为小写并分词"""
return re.findall(r'\b\w+\b', text.lower())
def sentence_to_vector(sentence, embeddings):
"""通过平均词向量将句子转换为向量"""
words = tokenize(sentence)
vectors = [embeddings.get(word, [0, 0]) for word in words]
vectors = [v for v in vectors if sum(v) != 0] # 移除未知词
if not vectors:
return np.zeros(2) # 如果没有有效单词,返回零向量
return np.mean(vectors, axis=0)
# 将所有文档转换为向量
doc_vectors = [sentence_to_vector(doc, word_embeddings) for doc in documents]
步骤 4:实现余弦相似度
余弦相似度是向量搜索中常用的度量,因为它衡量向量间的夹角,而忽略向量的大小,这对于比较文本嵌入的语义相似度非常适合。
计算公式为两个向量的点积除以其范数的乘积。如果任一向量为零(例如没有有效单词),返回 0 以避免除零错误。该函数用于将查询向量与文档向量进行比较。
def cosine_similarity(vec1, vec2):
"""计算两个向量的余弦相似度"""
dot_product = np.dot(vec1, vec2)
norm1 = np.linalg.norm(vec1)
norm2 = np.linalg.norm(vec2)
if norm1 == 0 or norm2 == 0:
return 0.0
return dot_product / (norm1 * norm2)
步骤 5:构建向量搜索函数
现在,我们实现核心向量搜索函数。该函数接收一个查询,将其转换为向量,与每个文档向量计算余弦相似度,并返回前 k 个文档及其相似度分数。我们使用 np.argsort 对文档按相似度排序,并过滤掉得分为零的结果(例如查询中没有有效单词时)。
def vector_search(query, documents, embeddings, top_k=3):
"""执行向量搜索并返回前 k 个相似文档"""
query_vector = sentence_to_vector(query, embeddings)
similarities = [cosine_similarity(query_vector, doc_vec) for doc_vec in doc_vectors]
# 获取相似度前 k 的索引
ranked_indices = np.argsort(similarities)[::-1][:top_k]
results = [
(documents[i], similarities[i])
for i in ranked_indices
if similarities[i] > 0
]
return results
# 示例查询
query = "Machine learning technology"
results = vector_search(query, documents, word_embeddings)
print("Query:", query)
print("Top results:")
for doc, score in results:
print(f"Score: {score:.3f}, Document: {doc}")
输出示例:
Query: Machine learning technology
Top results:
Score: 1.000, Document: Machine learning is powerful
Score: 0.999, Document: Deep learning transforms technology
Score: 0.997, Document: Artificial intelligence advances rapidly
如上所见,该函数成功检索了与查询语义最相关的文档。即使这些文档中没有完全匹配的短语“machine learning technology”,它们的含义仍高度契合,这就是基于向量搜索的强大之处。
步骤 6:可视化向量
为了更直观地理解向量搜索的工作原理,我们可以将文档向量和查询向量在二维空间中可视化。这有助于观察相似向量是如何聚集在一起的:
def plot_vectors(doc_vectors, documents, query, query_vector):
"""在二维空间中绘制文档和查询向量"""
plt.figure(figsize=(8, 6))
# 绘制文档向量
doc_x, doc_y = zip(*doc_vectors)
plt.scatter(doc_x, doc_y, c='blue', label='Documents', s=100)
for i, doc in enumerate(documents):
plt.annotate(doc[:20] + "...", (doc_x[i], doc_y[i]))
# 绘制查询向量
plt.scatter(query_vector[0], query_vector[1], c='red', label='Query', s=200, marker='*')
plt.annotate(query[:20], (query_vector[0], query_vector[1]), color='red')
plt.title('Vector Search: Document and Query Vectors')
plt.xlabel('Dimension 1')
plt.ylabel('Dimension 2')
plt.legend()
plt.grid(True)
plt.show()
plt.close()
# 生成可视化图
query_vector = sentence_to_vector(query, word_embeddings)
plot_vectors(doc_vectors, documents, query, query_vector)
执行该代码后,我们会看到文档向量以蓝色点标出,查询向量以红色星号标出。相似的文档向量会聚集在查询向量附近,从而直观地展示了向量搜索如何根据语义进行匹配。
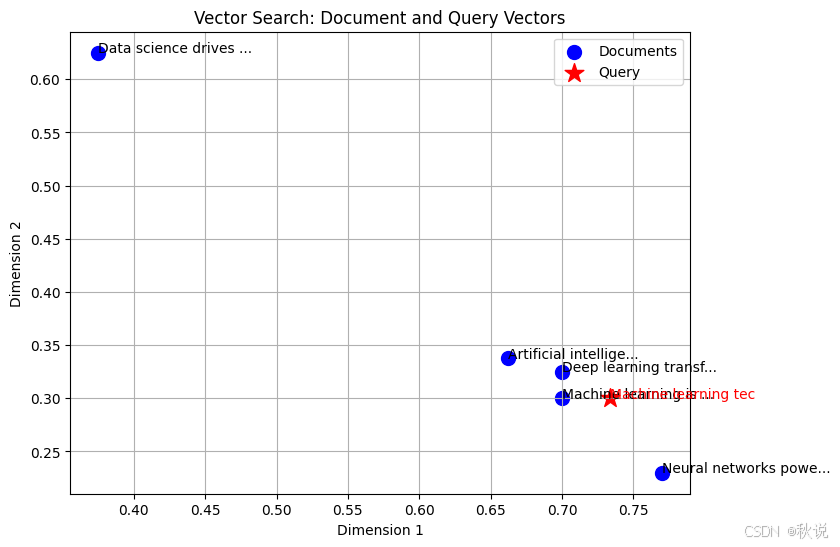
蓝色点表示文档向量,红色星号表示查询向量。标注显示了每个文档和查询的前 20 个字符。
我们还可以看到,离查询向量更近的文档在语义上更相似,从视觉上验证了向量搜索的工作原理。
为什么向量搜索对 RAG 很重要
在 RAG 中,向量搜索是检索步骤的核心。通过将文档和查询转换为向量,RAG 能够获取语境相关的信息,即使面对复杂查询也能如此。
我们这个简单实现模拟了这一过程:查询向量会检索语义上接近的文档,而语言模型可以基于这些文档生成响应。在实际应用中,这通常涉及高维嵌入和优化的搜索算法(如 HNSW 或 IVF),但核心理念保持不变。
结论
在本教程中,我们使用 Python 从零实现了向量搜索。
我们还可以通过使用真实的词嵌入(例如 Hugging Face 的 Transformers 提供的模型)或使用近似最近邻算法优化搜索来扩展此实现。



















 5054
5054

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











