







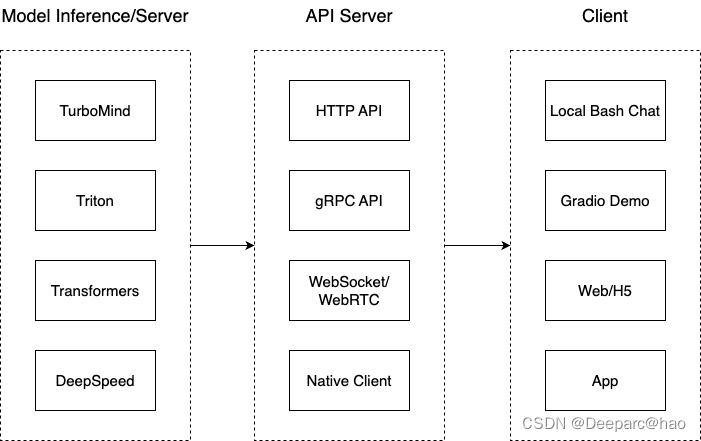
一、加速模型推理:
大模型的推理速度将严重影响,用户的体验感和使用效率,各个大厂都在尽可能的提升模型的推理输出速度,常见的方法有量化、蒸馏和剪枝等。本篇文章将重点介绍上海人工智能实验室推出的LMDeploy部署架构,提高模型的推理速度。
Tensor并行:
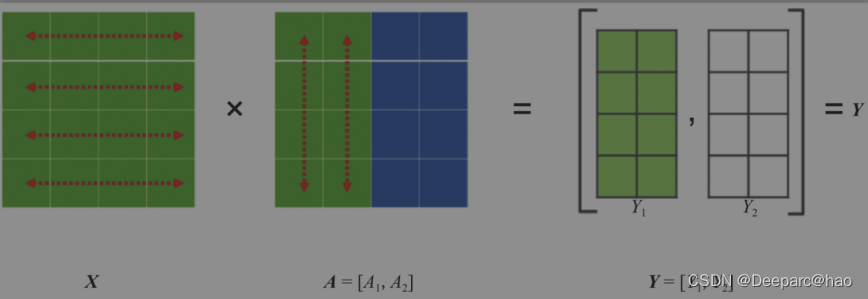
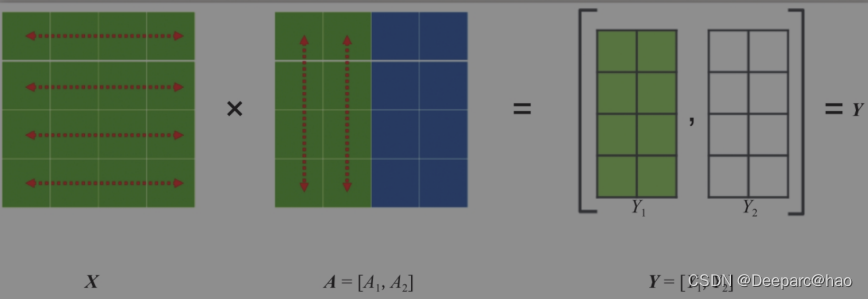
Tensor并行一般分为行并行或列并行,简单来说,就是把一个大的张量(参数)分到多张卡上,分别计算各部分的结果,然后再同步汇总。
行并行:
列并行:
模型量化:
- 计算密集(compute-bound): 指推理过程中,绝大部分时间消耗在数值计算上;针对计算密集型场景,可以通过使用更快的硬件计算单元来提升计算速。
- 访存密集(memory-bound): 指推理过程中,绝大部分时间消耗在数据读取上;针对访存密集型场景,一般通过减少访存次数、提高计算访存比或降低访存量来优化。
常见的 LLM 模型由于 Decoder Only 架构的特性,实际推理时大多数的时间都消耗在了逐 Token 生成阶段(Decoding 阶段),是典型的访存密集型场景。
可以使用 KV Cache 量化和 4bit Weight Only 量化(W4A16)。KV Cache 量化是指将逐 Token(Decoding)生成过程中的上下文 K 和 V 中间结果进行 INT8 量化(计算时再反量化),以降低生成过程中的显存占用。4bit Weight 量化,将 FP16 的模型权重量化为 INT4,Kernel 计算时,访存量直接降为 FP16 模型的 1/4,大幅降低了访存成本。Weight Only 是指仅量化权重,数值计算依然采用 FP16(需要将 INT4 权重反量化)。
二、环境准备:
# 拉取已有环境:
/root/share/install_conda_env_internlm_base.sh lmdeploy
# 激活lmdeploy虚拟环境:
conda activate lmdeploy
# 安装所需的依赖包:
# 解决 ModuleNotFoundError: No module named 'packaging' 问题
pip install packaging
# 使用 flash_attn 的预编译包解决安装过慢问题
pip install /root/share/wheels/flash_attn-2.4.2+cu118torch2.0cxx11abiTRUE-cp310-cp310-linux_x86_64.whl
pip install 'lmdeploy[all]==v0.1.0'
三、模型部署:
使用 TurboMind 推理模型需要先将模型转化为 TurboMind 的格式,目前支持在线转换和离线转换两种形式。在线转换可以直接加载 Huggingface 模型,离线转换需需要先保存模型再加载。
TurboMind 是一款关于 LLM 推理的高效推理引擎,基于英伟达的 FasterTransformer 研发而成。它的主要功能包括:LLaMa 结构模型的支持,persistent batch 推理模式和可扩展的 KV 缓存管理器。
在线转换:
lmdeploy 支持直接读取 Huggingface 模型权重,目前共支持三种类型:
- 在 huggingface.co 上面通过 lmdeploy 量化的模型,如 llama2-70b-4bit, internlm-chat-20b-4bit
- huggingface.co 上面其他 LM 模型,如 Qwen/Qwen-7B-Chat
# 需要能访问 Huggingface 的网络环境
lmdeploy chat turbomind internlm/internlm-chat-20b-4bit --model-name internlm-chat-20b
lmdeploy chat turbomind Qwen/Qwen-7B-Chat --model-name qwen-7b转换完成就可以开启和LLM直接对话,无需下面的操作。
离线转换:
离线转换需要在启动服务之前,将模型转为 lmdeploy TurboMind 的格式
# 转换模型(FastTransformer格式) TurboMind
lmdeploy convert internlm-chat-7b /path/to/internlm-chat-7b(1)TurboMind 推理+命令行本地对话
模型转换完成后,我们就具备了使用模型推理的条件,接下来就可以进行真正的模型推理环节。
我们先尝试本地对话(Bash Local Chat),下面用(Local Chat 表示)在这里其实是跳过 API Server 直接调用 TurboMind。简单来说,就是命令行代码直接执行 TurboMind。所以说,实际和前面的架构图是有区别的。
这里支持多种方式运行,比如Turbomind、PyTorch、DeepSpeed。但 PyTorch 和 DeepSpeed 调用的其实都是 Huggingface 的 Transformers 包,PyTorch表示原生的 Transformer 包,DeepSpeed 表示使用了 DeepSpeed 作为推理框架。Pytorch/DeepSpeed 目前功能都比较弱,不具备生产能力,不推荐使用。
# Turbomind + Bash Local Chat
lmdeploy chat turbomind ./workspace 输入后两次回车,退出时输入exit 回车两次即可。
(2)TurboMind推理+API服务
在上面的部分我们尝试了直接用命令行启动 Client,接下来我们尝试如何运用 lmdepoy 进行服务化。
”模型推理/服务“目前提供了 Turbomind 和 TritonServer 两种服务化方式。此时,Server 是 TurboMind 或 TritonServer,API Server 可以提供对外的 API 服务。
TurboMind
首先启动sever服务端:
# ApiServer+Turbomind api_server => AsyncEngine => TurboMind
lmdeploy serve api_server ./workspace \
--server_name 0.0.0.0 \
--server_port 23333 \
--instance_num 64 \
--tp 1再开启另外一个terminal作为client客户端:
# ChatApiClient+ApiServer(注意是http协议,需要加http)
lmdeploy serve api_client http://localhost:23333TritonServer
使用 Triton Server 需要安装一下 Docker 及其他依赖
先装一些基本的依赖
apt-get update
apt-get install cmake sudo -y安转docker
# Add Docker's official GPG key:
sudo apt-get install ca-certificates curl gnupg
sudo install -m 0755 -d /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
sudo chmod a+r /etc/apt/keyrings/docker.gpg
# Add the repository to Apt sources:
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
# install
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin把提供模型推理服务的引擎从 TurboMind 换成了 TritonServer
# ApiServer+Triton
bash workspace/service_docker_up.sh再开一个窗口执行 Client 命令
# ChatTritonClient + TritonServer(注意是gRPC协议,不要用http)
lmdeploy serve triton_client localhost:33337(3) SSH+fastapi查看部署之后的日志信息:
使用ssh -CNg -L 23333:127.0.0.1:23333 root@ssh.intern-ai.org.cn -p <你的ssh端口号>,直接打开 http://{host}:23333 查看接口信息。
(4)网页 Demo 演示
TurboMind 服务作为后端
启动sever端:
# ApiServer+Turbomind api_server => AsyncEngine => TurboMind
lmdeploy serve api_server ./workspace \
--server_name 0.0.0.0 \
--server_port 23333 \
--instance_num 64 \
--tp 1再启动服务端:
# Gradio+ApiServer。必须先开启 Server,此时 Gradio 为 Client
lmdeploy serve gradio http://0.0.0.0:23333 \
--server_name 0.0.0.0 \
--server_port 6006 \
--restful_api TrueTurboMind 推理作为后端
Gradio直接和 TurboMind 连接
# Gradio+Turbomind(local)
lmdeploy serve gradio ./workspaceTurboMind 推理 + Python 代码集成
lmdeploy 还支持 Python 直接与 TurboMind 进行交互
from lmdeploy import turbomind as tm
# load model
model_path = "/root/share/temp/model_repos/internlm-chat-7b/"
tm_model = tm.TurboMind.from_pretrained(model_path, model_name='internlm-chat-20b')
generator = tm_model.create_instance()
# process query
query = "你好啊兄嘚"
prompt = tm_model.model.get_prompt(query)
input_ids = tm_model.tokenizer.encode(prompt)
# inference
for outputs in generator.stream_infer(
session_id=0,
input_ids=[input_ids]):
res, tokens = outputs[0]
response = tm_model.tokenizer.decode(res.tolist())
print(response)四、模型配置信息:
weights目录下的config.ini ,存放的就是 模型相关的配置信息
[llama]
model_name = internlm-chat-7b
tensor_para_size = 1
head_num = 32
kv_head_num = 32
vocab_size = 103168
num_layer = 32
inter_size = 11008
norm_eps = 1e-06
attn_bias = 0
start_id = 1
end_id = 2
session_len = 2056
weight_type = fp16
rotary_embedding = 128
rope_theta = 10000.0
size_per_head = 128
group_size = 0
max_batch_size = 64
max_context_token_num = 1
step_length = 1
cache_max_entry_count = 0.5
cache_block_seq_len = 128
cache_chunk_size = 1
use_context_fmha = 1
quant_policy = 0
max_position_embeddings = 2048
rope_scaling_factor = 0.0
use_logn_attn = 0模型属性相关的参数不可更改,主要包括下面这些。
model_name = llama2
head_num = 32
kv_head_num = 32
vocab_size = 103168
num_layer = 32
inter_size = 11008
norm_eps = 1e-06
attn_bias = 0
start_id = 1
end_id = 2
rotary_embedding = 128
rope_theta = 10000.0
size_per_head = 128数据类型相关的参数也不可随意更改
# weight_type 表示权重的数据类型。目前支持 fp16 和 int4。int4 表示 4bit 权重。当 weight_type 为 4bit 权重时,group_size 表示 awq 量化权重时使用的 group 大小
weight_type = fp16
group_size = 0剩余参数
tensor_para_size = 1
session_len = 2056
max_batch_size = 64
max_context_token_num = 1
step_length = 1
cache_max_entry_count = 0.5
cache_block_seq_len = 128
cache_chunk_size = 1
use_context_fmha = 1
quant_policy = 0
max_position_embeddings = 2048
rope_scaling_factor = 0.0
use_logn_attn = 0可能需要调整的参数
- KV int8 开关:
- 对应参数为
quant_policy,默认值为 0,表示不使用 KV Cache,如果需要开启,则将该参数设置为 4。 - KV Cache 是对序列生成过程中的 K 和 V 进行量化,用以节省显存。我们下一部分会介绍具体的量化过程。
- 当显存不足,或序列比较长时,建议打开此开关。
- 对应参数为
- 外推能力开关:
- 对应参数为
rope_scaling_factor,默认值为 0.0,表示不具备外推能力,设置为 1.0,可以开启 RoPE 的 Dynamic NTK 功能,支持长文本推理。另外,use_logn_attn参数表示 Attention 缩放,默认值为 0,如果要开启,可以将其改为 1。 - 外推能力是指推理时上下文的长度超过训练时的最大长度时模型生成的能力。如果没有外推能力,当推理时上下文长度超过训练时的最大长度,效果会急剧下降。相反,则下降不那么明显,当然如果超出太多,效果也会下降的厉害。
- 当推理文本非常长(明显超过了训练时的最大长度)时,建议开启外推能力。
- 对应参数为
- 批处理大小:
- 对应参数为
max_batch_size,默认为 64,也就是我们在 API Server 启动时的instance_num参数。 - 该参数值越大,吞度量越大(同时接受的请求数),但也会占用更多显存。
- 建议根据请求量和最大的上下文长度,按实际情况调整。
- 对应参数为
五、量化:
KV Cache量化:
KV Cache 量化是将已经生成序列的 KV 变成 Int8,使用过程一共包括三步:
第一步:计算 minmax。主要思路是通过计算给定输入样本在每一层不同位置处计算结果的统计情况。
- 对于 Attention 的 K 和 V:取每个 Head 各自维度在所有Token的最大、最小和绝对值最大值。对每一层来说,上面三组值都是
(num_heads, head_dim)的矩阵。这里的统计结果将用于本小节的 KV Cache。 - 对于模型每层的输入:取对应维度的最大、最小、均值、绝对值最大和绝对值均值。每一层每个位置的输入都有对应的统计值,它们大多是
(hidden_dim, )的一维向量,当然在 FFN 层由于结构是先变宽后恢复,因此恢复的位置维度并不相同。这里的统计结果用于下个小节的模型参数量化,主要用在缩放环节
# 计算 minmax
lmdeploy lite calibrate \
--model /root/share/temp/model_repos/internlm-chat-7b/ \
--calib_dataset "c4" \
--calib_samples 128 \
--calib_seqlen 2048 \
--work_dir ./quant_output第二步:通过 minmax 获取量化参数。主要就是利用下面这个公式,获取每一层的 K V 中心值(zp)和缩放值(scale)
zp = (min+max) / 2
scale = (max-min) / 255
quant: q = round( (f-zp) / scale)
dequant: f = q * scale + zp
# 需要执行的代码
# 通过 minmax 获取量化参数
lmdeploy lite kv_qparams \
--work_dir ./quant_output \
--turbomind_dir workspace/triton_models/weights/ \
--kv_sym False \
--num_tp 1第三步:修改配置。也就是修改 weights/config.ini 文件
把 quant_policy 改为 4 即可
W4A16量化:
W4A16中的A是指Activation,保持FP16,只对参数进行 4bit 量化。使用过程也可以看作是三步
第一步,和KV Cache一样
# 计算 minmax
lmdeploy lite calibrate \
--model /root/share/temp/model_repos/internlm-chat-7b/ \
--calib_dataset "c4" \
--calib_samples 128 \
--calib_seqlen 2048 \
--work_dir ./quant_output第二步:量化权重模型。利用第一步得到的统计值对参数进行量化,具体又包括两小步:
- 缩放参数,主要是性能上的考虑。
- 整体量化。
# 转换模型的layout,存放在默认路径 ./workspace 下
lmdeploy convert internlm-chat-7b ./quant_output \
--model-format awq \
--group-size 128最后一步:转换成 TurboMind 格式
# 转换模型的layout,存放在默认路径 ./workspace 下
lmdeploy convert internlm-chat-7b ./quant_output \
--model-format awq \
--group-size 128
--dst_path ./workspace_quant # 设置指定输出目录。

















 2086
2086

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









