







欢迎来到博主的专栏:从0开始linux
博主ID:代码小豪
线程与lwp
在linux内核当中,并没有为线程创建独立的内核数据结构,而是将一个进程内的所有线程,描述成lwp(轻量级进程)。
而在C语言线程库<pthread.h>中,线程又是实打实的被描述成线程,那么为什么内核与C语言之间会有如此割裂感呢?那么C语言又是如何与内核之间统一起来的呢?听博主娓娓道来。
为什么线程库与linux内核割裂呢?
与其他操作系统对于线程的管理方式不同,linux选择将线程与进程之间统一起来,于是线程与进程都同时使用了struct task_struct作为内核数据结构,而线程可以与进程之间共享进程地址空间,这都是我们前面所讲的内容。而windows系统则是创建了两种不同的内核数据结构来区分进程和线程,这一点博主不多赘述。
那么这就会导致linux创建线程(轻量级进程)的系统调用与其他操作系统的系统调用产生非常大的差异,我们linux的创建线程的系统调用叫做clone。而由于linux将线程和进程之间并没有区分太大的差异性(这并非缺点)。因此clone函数不仅能创建线程,还能创建进程。
clone函数的系统调用如下:(鉴于clone函数的复杂, 博主并不打算在这篇中介绍)
int clone(int (*fn)(void *), void *stack, int flags, void *arg, ...
/* pid_t *parent_tid, void *tls, pid_t *child_tid */ );
这个clone当中的参数这么复杂,而且作用也非常复杂,这学习成本当然会比较高,而且如果用户对linux系统不熟悉,之前只是学习过操作系统的线程概念,或者是一个专注于windows平台的开发者,那么大概率是不清楚lwp(轻量级进程)和线程之间到底有什么联系。因此,为了让用户可以减少时间成本,另外还能提高C语言的可移植性。C语言决定为所有平台都推出一个统一的接口,这就是线程库的由来。(其实C语言的文件接口也是出于这种考虑。)
那么此时问题就来了,C语言为了照顾到所有的平台,将这些接口都统统称为线程接口,但是linux上面的不叫线程,而是叫lwp,但是C语言出于通用性的考虑,还是将linux的lwp当成线程来封装了。这也是割裂感的由来。
线程与lwp的统一
那么既然linux内核当中用的是lwp,但是C语言要提供给用户的却是线程,那么这是怎么做到呢?很简单,既然linux没有定义线程的数据结构,那么我C语言自己定义出线程的数据结构不就行了?
在C语言线程库当中,存在一个struct pthread结构体类型,C语言就是使用这个结构体来描述lwp的。我们在进程地址空间中讲过,动态库都是保存在进程空间当中的共享区的。而C语言线程库是不是一个动态库啊?当然是了,因此,我们的struct pthread定义在库中,而库又保存在共享区当中,因此struct pthread是保存在共享区当中的。
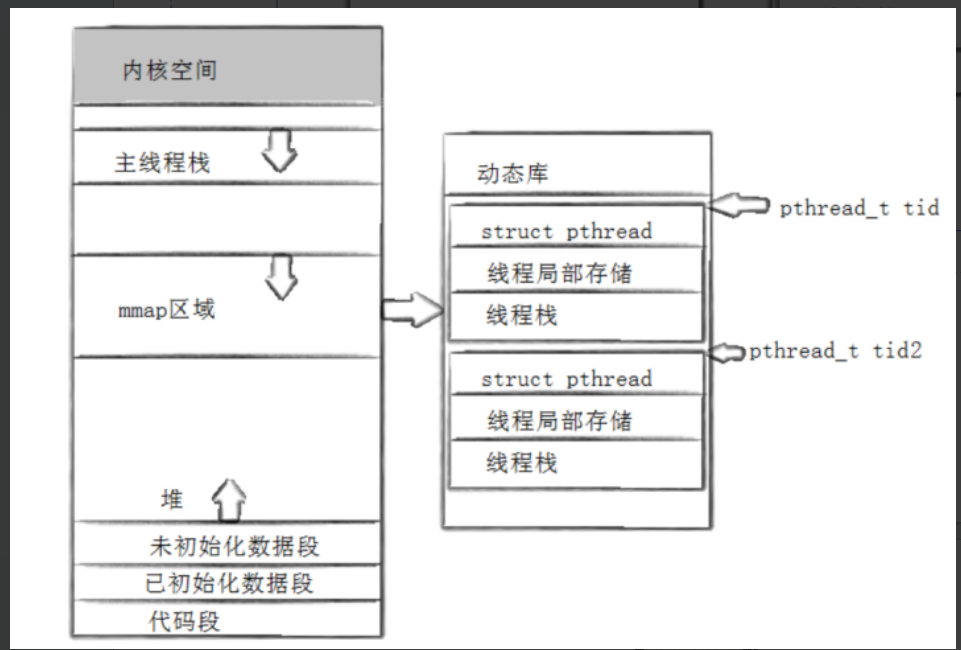
这里重点讲讲线程栈吧,由于线程之间(无论是分支线程,还是主线程)都是共用同一个进程地址空间的,那么线程会产生局部变量,要调用函数吧,而无论是局部变量,还是函数栈帧,都是保存在栈空间中的。但是我们进程地址空间就一个栈区间啊?局部变量和线程各自调用的函数栈可不是像全局变量那样可以共享,或者说它们应该私密一点。因此,每个线程虽然是共享进程地址空间的,但是还是要有一部分数据要隔离开来。
我们进程地址空间的栈区就一个,这个栈区属于主栈区,由主线程可以使用,而其他分支线程,会在共享区内部,申请一块空间,该空间就是线程独立的栈空间。但是和主线程的栈空间不同的是,线程的独立栈空间并没有太大空间,最多只有8M。
线程库源码
说了这么多,我们还是从线程库的源码开始了解吧。下面的线程库的版本为glibc2.4版本。
首先我们来看看线程的数据结构,struct pthread_struct。
/* Thread descriptor data structure. */
struct pthread
{
/* This descriptor's link on the `stack_used' or `__stack_user' list. */
list_t list;
/* Thread ID - which is also a 'is this thread descriptor (and
therefore stack) used' flag. */
pid_t tid;
/* Process ID - thread group ID in kernel speak. */
pid_t pid;
int flags;
/* The result of the thread function. */
// 线程运⾏完毕,返回值就是void*, 最后的返回值就放在tcb中的该变量⾥⾯
// 所以我们⽤pthread_join获取线程退出信息的时候,就是读取该结构体
// 另外,要能理解线程执⾏流可以退出,但是tcb可以暂时保留,这句话
void *result;
/* Scheduling parameters for the new thread. */
// ⽤⼾指定的⽅法和参数
void *(*start_routine) (void *);
void *arg;
// 线程⾃⼰的栈和⼤⼩
void *stackblock;
size_t stackblock_size;
size_t guardsize;
size_t reported_guardsize;
struct __res_state res;
char end_padding[];
} __attribute ((aligned (TCB_ALIGNMENT)));
这里博主删除了大部分代码,和一些英文注释。如果大伙对线程库源码比较感兴趣,可以去github、gitee当中找gilbc中的线程库源码。
像我们前面所说的,struct pthread是对系统内核当中的lwp的封装,我们也可以看到,在struct pthread当中存在一些内核数据,比如pid,tid(其实就是lwp号)。除此之外,往后还有线程的返回结果,线程的执行路径(strat_routine)。还有线程栈的地址和大小,这些都保存struct pthread当中。
那么接下来我们看看pthread_create函数,看看它们是如何创建线程的。
int __pthread_create_2_1(newthread, attr, start_routine, arg)
pthread_t *newthread;
const pthread_attr_t *attr;
void *(*start_routine)(void *);
void *arg;
{
STACK_VARIABLES;
// 重点1: 线程属性,虽然我们不设置,但是不妨碍我们了解
const struct pthread_attr *iattr = (struct pthread_attr *)attr;
if (iattr == NULL)
iattr = &default_attr;
// 重点2:传说中的原⽣线程库中的⽤来描述线程的tcb
struct pthread *pd = NULL;
// 重点3: ALLOCATE_STACK会在先申请struct pthread对象,当然其实是申请⼀⼤块空间,
int err = ALLOCATE_STACK(iattr, &pd);
if (__builtin_expect(err != 0, 0))
versioned_symbol return err;
// 重点4:向线程tcb中设置未来要执⾏的⽅法的地址和参数
pd->start_routine = start_routine;
pd->arg = arg;
/* Copy the thread attribute flags. */
struct pthread *self = THREAD_SELF;
pd->flags = ((iattr->flags & ~(ATTR_FLAG_SCHED_SET | ATTR_FLAG_POLICY_SET))
| (self->flags & (ATTR_FLAG_SCHED_SET | ATTR_FLAG_POLICY_SET)));
pd->joinid = iattr->flags & ATTR_FLAG_DETACHSTATE ? pd : NULL;
pd->eventbuf = self->eventbuf;
pd->schedpolicy = self->schedpolicy;
pd->schedparam = self->schedparam;
// 重点5:把pd(就是线程控制块地址)作为ID,传递出去,所以上层拿到的就是⼀个虚拟地址
*newthread = (pthread_t)pd;
// 重点6: 检测线程属性是否分离,这个很好理解
bool is_detached = IS_DETACHED(pd);
/* Start the thread. */
err = create_thread(pd, iattr, STACK_VARIABLES_ARGS); // 重点函数
return 0;
}
// 版本确认信息,意思就是如果⽤的库是GLIBC_2_1,pthread_create函数就是__pthread_create_2_1
这里也是删除了大部分的源码和注释。我们可以看到,当我们调用pthread_create时,函数内部,会将我们传入给pthread_create的参数,用来初始化struct pthread对象中的成员,并且调用了一个叫做create_pthread的函数,那么这个函数有什么用呢?我们再来看看。
tatic int
create_thread(struct pthread *pd, const struct pthread_attr *attr,
STACK_VARIABLES_PARMS)
{
int clone_flags = (CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGNAL |
CLONE_SETTLS | CLONE_PARENT_SETTID | CLONE_CHILD_CLEARTID | CLONE_SYSVSEM
if (__builtin_expect(THREAD_GETMEM(THREAD_SELF, report_events), 0))
{
/* The parent thread is supposed to report events. Check whether
the TD_CREATE event is needed, too. */
const int _idx = __td_eventword(TD_CREATE);
const uint32_t _mask = __td_eventmask(TD_CREATE);
if ((_mask & (__nptl_threads_events.event_bits[_idx] | pd-
>eventbuf.eventmask.event_bits[_idx])) != 0)
{
/* We always must have the thread start stopped. */
pd->stopped_start = true;
/* Create the thread. We always create the thread stopped
so that it does not get far before we tell the debugger. */
int res = do_clone(pd, attr, clone_flags, start_thread,
STACK_VARIABLES_ARGS, 1);
}
博主依然是删除了大部分源码和注释,可以看到在create_pthread当中,依然是在初始化大量的数据,作为do_clone函数的函数参数,我们接着看看do_clone干了什么?
static int
do_clone(struct pthread *pd, const struct pthread_attr *attr,
int clone_flags, int (*fct)(void *), STACK_VARIABLES_PARMS,
int stopped)
{
#ifdef PREPARE_CREATE
PREPARE_CREATE;
#endif
// 执⾏特性体系结构下的clone函数
if (ARCH_CLONE(fct, STACK_VARIABLES_ARGS, clone_flags,
pd, &pd->tid, TLS_VALUE, &pd->tid) == -1)
{
atomic_decrement(&__nptl_nthreads); /* Oops, we lied for a second. */
/* Failed. If the thread is detached, remove the TCB here since
the caller cannot do this. The caller remembered the thread
as detached and cannot reverify that it is not since it must
not access the thread descriptor again. */
if (IS_DETACHED(pd))
__deallocate_stack(pd);
return errno;
}
// 下⾯是调⽤相关系统调⽤,设置轻量级进程的调度参数和⼀些异常处理,不关⼼
return 0;
}
在do_clone中,函数主要的任务有两个。第一个就是将create_clone当中处理好的参数,拿过来,用来作为系统调用clone()的参数,来创建出一个轻量级进程lwp,接着再将lwp的数据设置好。
那么有人可能就说了,我在上面的代码当中找了好久,也没找到clone函数啊,这是因为clone函数被封装到了ARCH_CLONE当中,但是由于ARCH_CLONE是由汇编代码写的,所以博主就不节外生枝了,总之,ARCH_CLONE就是将参数,传给clone系统调用就行!!!
所以说,pthread库其实为我们创建了一个用户级别的线程概念,用来减少对linux系统当中的lwp陌生感,而且他真的很好用不是吗?直接使用pthread_create就能创建出线程,而且还会将lwp的参数设置好,相比较与用户使用clone函数创建出lwp,然后再用各种各样的系统调用,将lwp的参数设置好。他真的是减少了用户对于linux线程使用的学习成本了。


















 728
728

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











