







目录
redis自身已经是键值对结构了,redis自身的键值对就是通过哈希的方式来组织的,把key这一层组织完成之后,到了value这一层,value的其中一种类型还可以再是哈希,如同套娃一般。
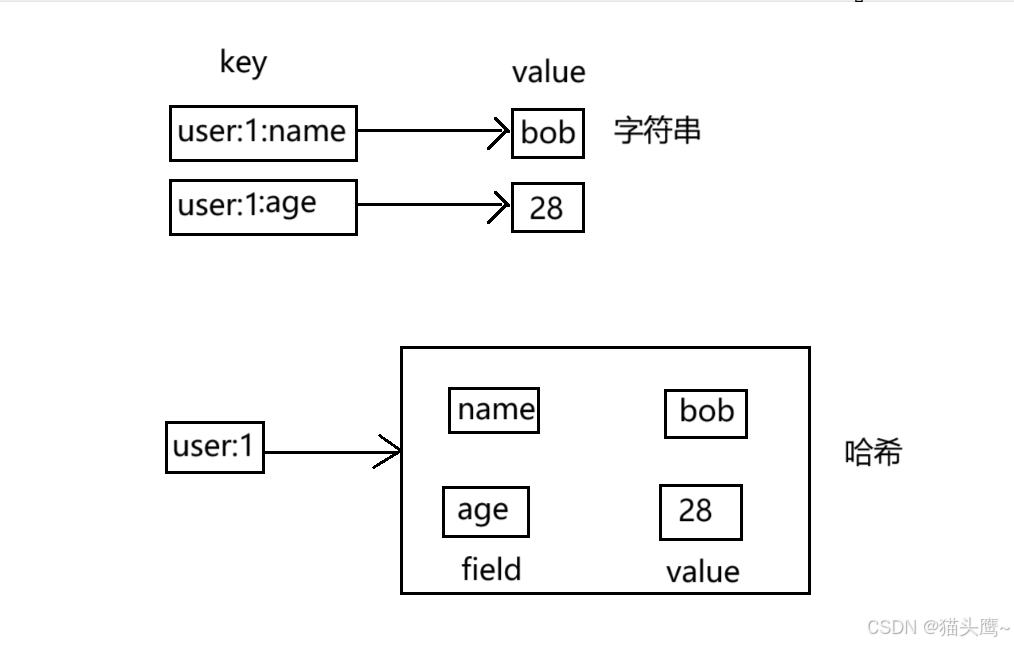
value里哈希的key值就不叫key了而是filed,当我们提到key就是外面的那一层,提到filed就是value里哈希的key。
hash命令
hset
hset可以同样可以设置多组键值对。
语法:
hset key field value [field value...]
返回值:设置成功的键值对filed-value的个数。
hset设置一组键值对
![]()
hset设置多组键值对
上面给key设置了f1 111,此处是给key又添加了三个键值对,也就是说此时key里存了4个键值对。

我们设置了之后要获取出来看看吧,就需要使用hget方法获取。
hget
通过key查一下哈希,在通过field查到value。
语法:
hget key field
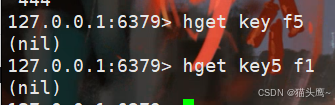
返回值:返回field的value,如果不存在返回nil。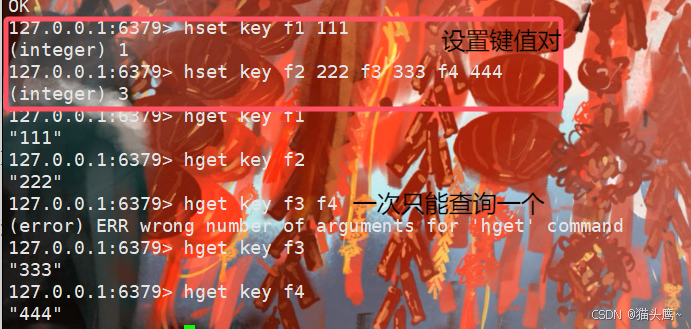
不管是key不存在还是filed不存在,都会返回nil。
第一条语句是filed不存在,第二条语句是key不存在。
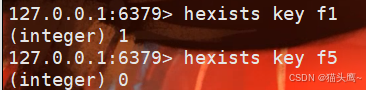
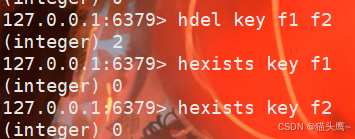
hexists
判定filed是否存在 。
语法:
hexists key filed
返回值:1表示存在,0表示不存在。
hdel
删除哈希中指定的字段。del删除的是keyhdel删除的是field。一次可以删除多个。
hdel key field [field]
返回值:本次操作删除的字段个数。
如果用del的话,是把整个哈希都删了。
![]()
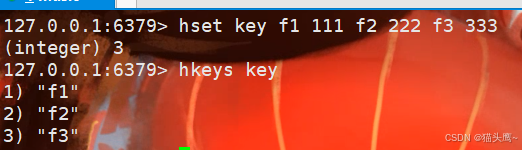
hkeys
获取到哈希中的所有filed。
语法:
hkeys key
这个操作会遍历哈希,根据key找到哈希,然后再遍历哈希 ,此时时间复杂度是O(N)的。这个N是哈希元素个数,如果哈希非常大,很可能导致redis服务器被阻塞住,因此要谨慎使用。
hkeys获取到的是所有的filed。
hvals
获取到哈希中的value。
语法:
hvals key
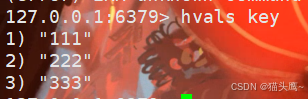
hvals的时间复杂度也是O(N),N是哈希元素个数,如果哈希非常大,也很可能导致redis服务器被阻塞住。
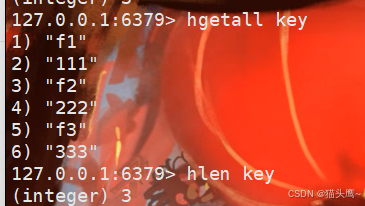
hgetall
获取hash中的所有字段。hgetall相当于是hvals和hkeys的结合体,可以获取到所有的filed和value
语法:
hgetall key
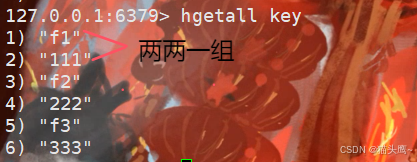
hgetall的风险还是很大的,多数情况下我们不需要查找所有的field,可能只需要查询其中几个field,此时就需要使用下面的命令。
hmget
类似于之前的mget,可以一次查询多个field。
语法:
hmget key field [field...]
这里结果中value的顺序和查询中filed的顺序是一一对应的。

hlen
获取到哈希的元素个数,不需要便利,为啥不需要便利呢?用一个变量存一下就可以。
语法:
hlen key
key有3组键值对,因此hlen key的返回值就是3。
hsetnx
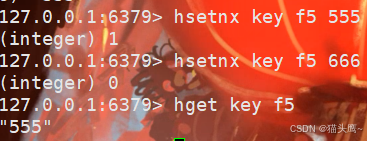
不存在的时候才能设置成功,如果存在,则失败。这里的不存在指的是filed不存在。
语法:
hsetnx key field value
我们先设置一个f5 555,此时f5不存在,设置成功,此时在尝试设置f5的value是666,此时f5已经存在就返回0失败了,此时用fget查询f5时,结果还是555。
hincrby /hincrbyfloat
hash这里的value,也可以当做数字来处理,使用hincrby就可以加减整数,hincrbyfloat就可以加减整数,使用频率不算很高,因此redis没有提供类似于incr decr...
hincrby
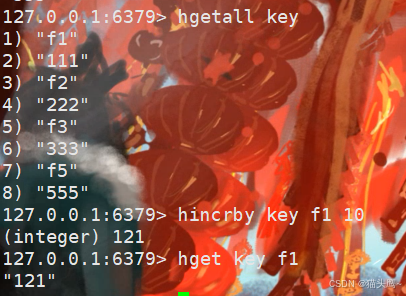
hincrby对value进行加n,这个n也可以是负数。
语法:
hincrby key field n
我们可以对f1的value进行+10。
hincrbyfloat
对value进行+n,这个n可以是浮点数,同样n也可以是负数。
使用方法和hincrby是一样的。

hstrlen
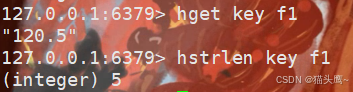
计算field对应value长度。
语法:
hstrlen key field
哈希命令总结
| 命令 | 执行效果 | 时间复杂度 |
| hset key filed value | 设置值 | O(1) |
| hget key field | 获取值 | O(1) |
| hdel key field [field...] | 删除field | O(1) |
| hlen key | 计算field个数 | O(1) |
| hgetall key | 获取所有的field-value | O(K) |
| hmget key field [field...] | 批量获取field-value | O(K) |
| hexists key field | 判断field是否存在 | O(1) |
| hkeys key | 获取所有的field | O(K) |
| hvals key | 获取所有的value | O(K) |
| hsetnx key field value | 设置值,但必须field不存在时才可以设置成功 | O(1) |
| hincrby key field n | 对应field的value + n | O(1) |
| hincrbyfloat key field n | 对应field的value + n | O(1) |
| hstrlen key field | 计算field的value长度 | O(1) |
哈希内部编码方式
哈希内部编码方式有两种:
- ziplist:压缩列表
- hashtable:哈希表
压缩
压缩我们挺常见到的,比如我们会把一个大文件压缩成rar、zip\gzip、7z等压缩文件,其实就是对数据执行了一些具体的压缩算法。
压缩的本质是对数据进行重新编码,不同的数据有不同的特点,结合这些特点,进行巧妙的设计,重新编码后可以缩小体积。
比如"abbcccddddeeeee"这样的字符串,重新编码表示为:1a2b3c4d5e。
再比如一个文件,内容是"abcd00000000......",abcd后面有99个0,重新编码后就成为abcd0[99]。
当然上述是比较粗糙的编码方式,压缩算法都是精妙设计的。
何时使用hashtable何时使用ziplist
ziplist也是同理,内部的数据都是精心设计过的,表示一个普通的哈希表可能会浪费一定的空间,哈希表首先是个数组,有些位置上有元素有些位置上没元素,可能就会浪费一些空间。
当然ziplist也会付出一些代价,它进行读写元素,速度是比较慢的,当然元素少的话,慢的并不明显,如果元素太多,就会慢的雪中送碳。
因此,如果元素少,则会使用ziplist表示,元素个数比较多,使用hashtable来表示。
其次,如果value的值长度比较短,使用ziplist,如果某个value太长,则会转换成hashtable。
因此如果要使用ziplist必须元素少并且value长度短。
配置文件
在redis的配置文件中有hash-max-ziplist-entries配置选项,这个选项默认是512,也就是说如果元素个数小于512时使用ziplist,大于则使用hashtable。
还有一个hash-max-ziplist-value配置选项,默认是64字节,如果所有元素的值都是小于64字节则使用ziplist,否则使用hashtable。
这个配置文件在 /etc/redis/目录下,可以通过配置文件手动的调整hash-max-ziplist-entries和hash-max-ziplist-value的默认大小。


















 4287
4287

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









