







最后
🍅 硬核资料:关注即可领取PPT模板、简历模板、行业经典书籍PDF。
🍅 技术互助:技术群大佬指点迷津,你的问题可能不是问题,求资源在群里喊一声。
🍅 面试题库:由技术群里的小伙伴们共同投稿,热乎的大厂面试真题,持续更新中。
🍅 知识体系:含编程语言、算法、大数据生态圈组件(Mysql、Hive、Spark、Flink)、数据仓库、Python、前端等等。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
基本可以确定的是,如果爬虫使用不当,那么爬虫的开发者是有可能触犯法律的,而根据情况不同,获得的刑罚也有可能有差异。
要看开发和使用爬虫是否犯法,需要从爬什么数据、如何爬取数据以及爬到数据之后怎么用三个方面来判断。接下来就简单分析一下:

爬什么数据犯法?
1、属于著作权法保护的作品
有些网站发表的内容,如文章、评论等都是有著作权的,如果只是单纯的通过浏览器查看是不会触犯法律的。
但是,对于有著作权的作品,如果未经著作权人许可,以盈利为目的,对其作品进行复制是会触犯法律的。
根据《中华人民共和国著作权法》第46条:有下列侵权行为的,应当根据情况,承担停止侵害、消除影响、公开赔礼道歉、赔偿损失等民事责任,并可以由著作权行政管理部门给予没收非法所得、罚款等行政处罚:(一)剽窃、抄袭他人作品的;(二)未经著作权人许可,以营利为目的,复制发行其作品的;(三)出版他人享有专有出版权的图书的;(四)未经表演者许可,对其表演制作录音录像出版的;(五)未经录音录像制作者许可,复制发行其制作的录音录像的;(六)未经广播电台、电视台许可,复制发行其制作的广播、电视节目的;(七)制作、出售假冒他人署名的美术作品的。
如果是使用爬虫技术手段爬取数据之后将其保存下来或者传播,并且进行盈利,这种都是属于犯罪的。

2、用户的个人信息或者个人隐私
个人用户的个人信息,即使是用户自己放到一些网站上进行公开或者部分公开,如微博、_微信_等,不代表这些数据就可以被其他人随便获取!
根据《民法总则》第111条:任何组织和个人需要获取他人个人信息的,应当依法取得并确保信息安全。不得非法收集、使用、加工、传输他人个人信息;
根据《网络安全法》第44条:任何个人和组织不得窃取或者以其他非法方式获取个人信息。因此,如果爬虫在未经用户同意的情况下大量抓取用户的个人信息,则有可能构成非法收集个人信息的违法行为。
所以,如果爬取的数据涉及到个人信息,都是违法的!
还有些爬虫企图绕过权限校验等,爬取用户未公开的信息,如个人私密相册照片等,都是属于侵犯用户的个人隐私的,这种也是违法的。

3、反不正当竞争保护的数据
目前有很多网站中的数据系由用户生成,且该等数据和内容系原告网站的主要竞争力来源。如大众点评上面的店铺评价、评论等信息,携程网上面的关于酒店的评价评论等信息等。
根据《反不正当竞争法》第2条:经营者在市场交易中,应当遵循自愿、平等、公平、诚实信用的原则,遵守公认的商业道德。
那么,未经允许,爬取其他网站的核心数据,很明显并没有遵守《反不正当竞争法》中规定的自愿、平等、公平、诚实信用的原则。
在大众点评诉百度不正当竞争案件、以及新浪微博诉脉脉不正当竞争等案件中,法院都认定被告未经许可抓取、使用原告网站中的数据的行为,违反了诚实信用原则及公认的道德,损害了互联网的市场竞争秩序,损害了原告的竞争优势,从而构成不正当竞争。
因此,如果抓取大众点评、微博、豆瓣电影、知乎等UGC模式的网站上用户发布的信息,并在自己的产品或者服务中发布、使用该等信息,则有较大的风险构成不正当竞争。

怎么爬犯法?
======
如果是爬取公开的数据,通常不会被认为是侵权。Google、百度等搜索引擎都是这么爬取的。
那么,到底怎么爬数据是有可能触犯法律的呢,主要考虑是否涉及以下两种行为:
未遵守Robots协议
Robots协议是技术界为了解决爬取方和被爬取方之间通过计算机程序完成关于爬取的意愿沟通而产生的一种机制。
根据《互联网搜索引擎服务自律公约》第7条:机器人协议(robots协议)是指互联网站所有者使用robots.txt文件,向网络机器人(Web robots)给出网站指令的协议。具体而言,robots协议是网站所有者通过位于置于网站根目录下的文本文件robots.txt,提示网络机器人哪些网页不应被抓取,哪些网页可以抓取。
根据《互联网搜索引擎服务自律公约》第8条:互联网站所有者设置机器人协议应遵循公平、开放和促进信息自由流动的原则,限制搜索引擎抓取应有行业公认合理的正当理由,不利用机器人协议进行不正当竞争行为,积极营造鼓励创新、公平公正的良性竞争环境。
虽然《互联网搜索引擎服务自律公约》仅适用于中国互联网协会会员单位和自愿加入《中国互联网行业自律公约》的互联网从业单位,但在司法实践中,Robots协议已经被认定构成互联网行业搜索领域内的商业道德。
因此,无视网站设置的Robots协议而随意抓取网站内容的行为将涉嫌构成对《反不正当竞争法》的第2条的违反,即违反诚实信用原则和商业道德的不正当竞争行为。
绕过防护措施对数据的访问,强行突破反爬措施
由于爬虫的批量访问会给网站带来巨大的压力和负担,因此许多网站经营者会采取技术手段,以阻止爬虫批量获取自己网站信息。
所以,很多爬虫工具为了爬取数据,会想办法通过各种手段绕过防护措施,但是,这种行为也是会触犯法律的。
根据《刑法》第285条第二款:违反国家规定,侵入前款规定以外的计算机信息系统或者采用其他技术手段,获取该计算机信息系统中存储、处理或者传输的数据,或者对该计算机信息系统实施非法控制,情节严重的,处三年以下有期徒刑或者拘役,并处或者单处罚金;情节特别严重的,处三年以上七年以下有期徒刑,并处罚金。
企图通过技术手段,绕过网站的反爬机制,都属于《刑法》中规定的"侵入",都是要被处罚的。

怎么用犯法?
很多公司开发的爬虫遵守了Robots协议,也没有爬取不该爬取的数据,难道这样获取到的数据就可以随便使用了吗?其实也不是,如果使用不当,也会触犯法律的。
比如通过爬虫抓取到的数据进行盈利、损害他人利益、造假、诽谤等都是可能触犯法律的。
此外,未经被收集者同意,即使是将合法收集的公民个人信息向他人提供的,也属于刑法第二百五十三条之一规定的“提供公民个人信息”,可能构成犯罪。
小结
–
在使用爬虫的过程中,爬取的数据类型、爬取数据的方式以及爬取之后的使用都是可能触犯法律的。
其中,使用爬虫得到的数据进行盈利、损害他人利益、不正当竞争等一般都是针对经营者的。
但是对于程序员来说,如果你的老板让你开发的爬虫,是用来爬取用户的个人信息或者个人隐私,并且该爬虫未遵循Robots协议、或者有意的躲避反爬机制就可能触犯到法律了。

赌博、S情网站
=======
除了爬虫以外,最近很多关于程序员参与赌博网站的开发,最终被判刑的新闻,那么,如果参与赌博、S情等网站的开发,是不是一定触犯法律呢?
这种情况主要看开发者是不是属于"明知故犯"。
根据《最高人民法院、最高人民检察院、公安部关于办理网络赌博犯罪案件适用法律若干问题的意见》中关于网上开设赌场共同犯罪的认定和处罚规定:
明知是赌博网站,而为其提供下列服务或者帮助的,属于开设赌场罪的共同犯罪,依照刑法第三百零三条第二款的规定处罚:
(一)为赌博网站提供互联网接入、服务器托管、网络存储空间、通讯传输通道、投放广告、发展会员、软件开发、技术支持等服务,收取服务费数额在2万元以上的;
(二)为赌博网站提供资金支付结算服务,收取服务费数额在1万元以上或者帮助收取赌资20万元以上的;
(三)为10个以上赌博网站投放与网址、赔率等信息有关的广告或者为赌博网站投放广告累计100条以上的。
也就是说,如果你作为程序员,你在帮公司开发赌博网站,只要公司付给你的费用超过了2万元以上,那么你就和开设赌场的人是共同犯罪。
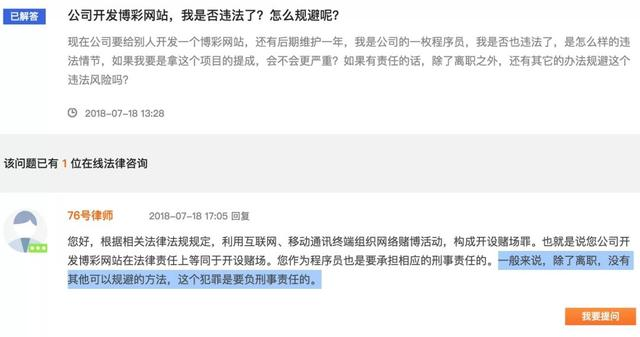
除了赌博网站,所有和黄赌毒有关的软件开发都不要参与,明知道是违法或者可能违法的行为,并为其提供技术支持,都是有可能触犯法律的。快播不就是个很好的例子吗。
所以,程序员一定要远离赌博、色情等网站,并拒绝为他们提供技术服务。
P2P
最近,P2P频繁暴雷,因为是网络借贷,所以这些暴雷的公司必然是有程序员的,所以,对于这种P2P公司如果涉及违法,那么参与开发的程序员到底算不算从犯?
前段时间,有脉脉用户发帖称"P2P公司暴雷,前端程序员被抓":
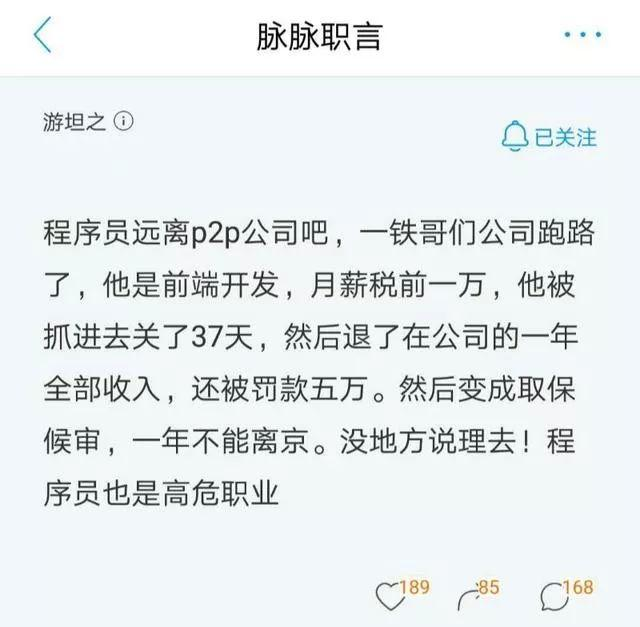
一时间,引起了广泛的讨论,有人认为程序员为违法提供了帮助,属于从犯,有人认为程序员可能不知道公司违法,是"不知者不罪"
那么,关于这个情况,知乎上有用户给过专业的解答:
『如果程序员只是单纯的负责开发,只拿合理的死工资,本人对于公司的合法性和P2P的政策不了解,找工作也是通过正规渠道的。』那么就不算从犯。
但是,如果还负责了公司的其他事情,或者没有只拿死工资,找工作也不是正规渠道的,那就另当别论了。重要的是,如果自己明知道公司是非法的,那么肯定就涉及犯罪了。
所以,对于这种做互联网金融的企业的程序员,需要多多了解一下自己公司当前的主营业务是否合法。是否涉及到非法集资、传销等违法行为。
外挂
==
外挂是指利用电脑技术针对一个或多个网络游戏,通过改变软件的部分程序制作而成的作弊程序。制作贩卖游戏外挂也是会受到我国司法机关打击的行为。

根据开发者制作的不同的外挂类型,以及使用方式等,根据以往案例,可能触犯非法经营罪、破坏计算机信息系统罪以及侵犯著作权罪等。

非法经营罪
外挂等违法行为的出现,严重侵害了游戏开发者、运营商以及正常消费者的合法权益,扰乱了互联网游戏经营的正常秩序,破坏了网络游戏产业的良性发展,违反国家规定,情节严重,应按刑法第225条第四项的规定处罚。
根据《刑法》第225条:违反国家规定,有下列非法经营行为之一,扰乱市场秩序,情节严重的,处五年以下有期徒刑或者拘役,并处或者单处违法所得一倍以上五倍以下罚金;情节特别严重的,处五年以上有期徒刑,并处违法所得一倍以上五倍以下罚金或者没收财产:
一)未经许可经营法律、行政法规规定的专营、专卖物品或者其他限制买卖的物品的;
二)买卖进出口许可证、进出口原产地证明以及其他法律、行政法规规定的经营许可证或者批准文件的;
三)未经国家有关主管部门批准非法经营证券、期货、保险业务的,或者非法从事资金支付结算业务的;
四)其他严重扰乱市场秩序的非法经营行为。
破坏计算机信息系统罪
有些外挂会修改网络游戏运行数据、干扰网络游戏服务端计算机信息系统功能、危害计算机信息系统安全的行为,符合破坏计算机信息系统罪的犯罪构成要件。
根据《刑法》第_286_条::违反国家规定,对计算机信息系统功能进行删除、修改、增加、干扰,造成计算机信息系统不能正常运行,后果严重的,处五年以下有期徒刑或者拘役;后果特别严重的,处五年以上有期徒刑。
侵犯著作权罪
还有些开发者通过非法手段,获取他人享有著作权的计算机软件中的核心程序文件,制作外挂后用以牟利。这种外挂程序虽然与官方客户端程序并不完全一致,但主体结构、功能构成实质性相同,故被告人的行为构成非法复制计算机软件的行为,应以侵犯著作权罪定罪处罚。
根据《刑法》第217条:以营利为目的,有下列侵犯著作权情形之一,违法所得数额较大或者有其他严重情节的,处三年以下有期徒刑或者拘役,并处或者单处罚金;违法所得数额巨大或者具有其他特别严重情节的,处三年以上七年以下有期徒刑,并处罚金:
1、未经著作权人许可,复制发行其文字作品、音乐、电影、电视、录像作品、计算机软件及其他作品 的;
做了那么多年开发,自学了很多门编程语言,我很明白学习资源对于学一门新语言的重要性,这些年也收藏了不少的Python干货,对我来说这些东西确实已经用不到了,但对于准备自学Python的人来说,或许它就是一个宝藏,可以给你省去很多的时间和精力。
别在网上瞎学了,我最近也做了一些资源的更新,只要你是我的粉丝,这期福利你都可拿走。
我先来介绍一下这些东西怎么用,文末抱走。
(1)Python所有方向的学习路线(新版)
这是我花了几天的时间去把Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
最近我才对这些路线做了一下新的更新,知识体系更全面了。

(2)Python学习视频
包含了Python入门、爬虫、数据分析和web开发的学习视频,总共100多个,虽然没有那么全面,但是对于入门来说是没问题的,学完这些之后,你可以按照我上面的学习路线去网上找其他的知识资源进行进阶。

(3)100多个练手项目
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。

(4)200多本电子书
这些年我也收藏了很多电子书,大概200多本,有时候带实体书不方便的话,我就会去打开电子书看看,书籍可不一定比视频教程差,尤其是权威的技术书籍。
基本上主流的和经典的都有,这里我就不放图了,版权问题,个人看看是没有问题的。
(5)Python知识点汇总
知识点汇总有点像学习路线,但与学习路线不同的点就在于,知识点汇总更为细致,里面包含了对具体知识点的简单说明,而我们的学习路线则更为抽象和简单,只是为了方便大家只是某个领域你应该学习哪些技术栈。

(6)其他资料
还有其他的一些东西,比如说我自己出的Python入门图文类教程,没有电脑的时候用手机也可以学习知识,学会了理论之后再去敲代码实践验证,还有Python中文版的库资料、MySQL和HTML标签大全等等,这些都是可以送给粉丝们的东西。

这些都不是什么非常值钱的东西,但对于没有资源或者资源不是很好的学习者来说确实很不错,你要是用得到的话都可以直接抱走,关注过我的人都知道,这些都是可以拿到的。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









