






我们在日常抓取网页中的数据时经常会遇到“分页”的情况,为了能抓取网站上不同分页的内容通常会通过循环遍历这些“特征序号”来访问对应网页分页;下图中是豆瓣电影Top250的网页,可以观察到不同分页间的特征序号为url"start="后的数字,初始值为0、分页间隔25,到225结束。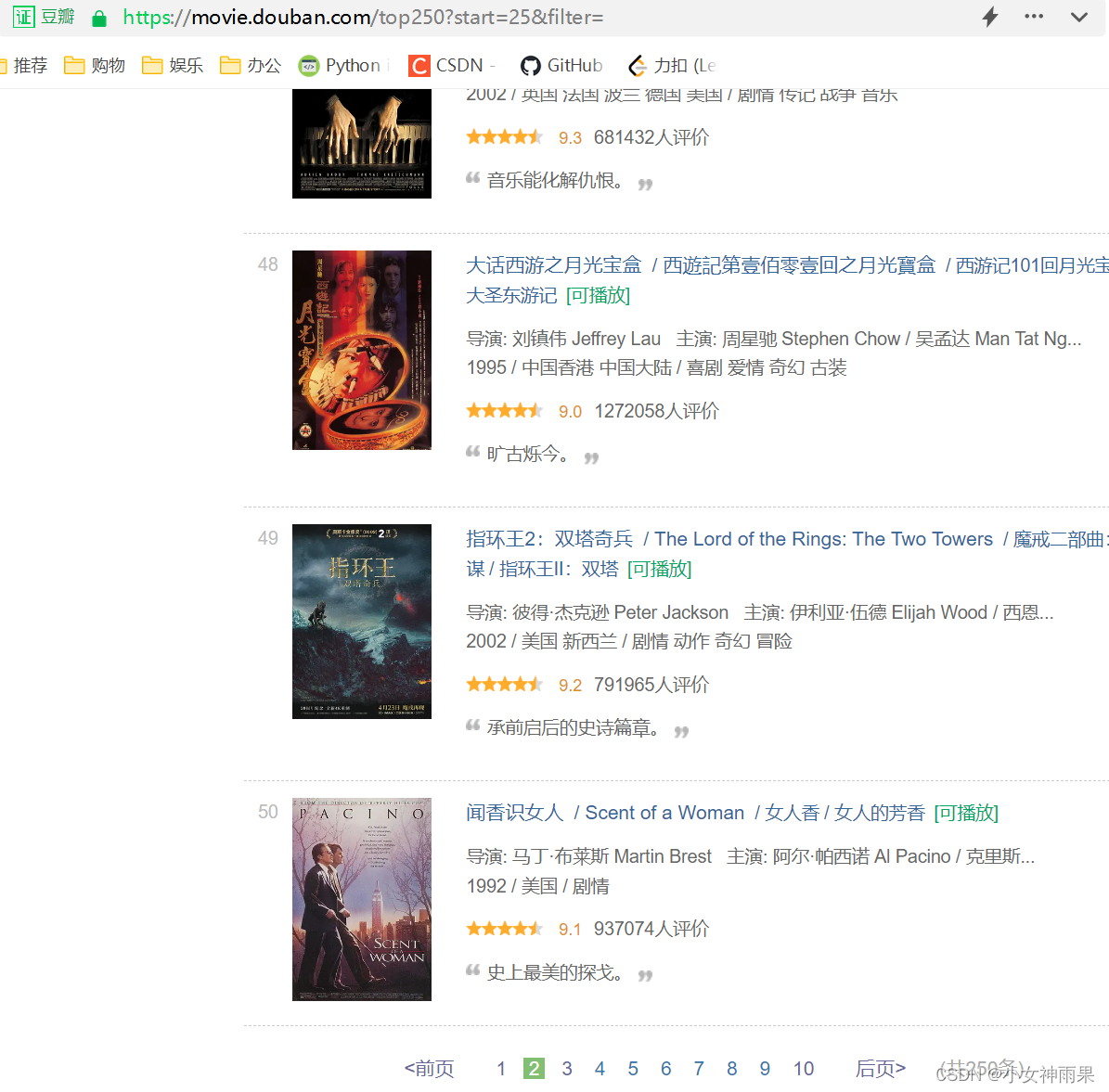
对分页的访问爬取可通过如下代码实现
import requests
from bs4 import BeautifulSoup
url = "https://movie.douban.com/top250?start=%d&filter="
head={'User-Agent':''}#字典的值从标头获取
for i in range(0,226,25):
req = requests.get(url%i,headers=head)
soup = BeautifulSoup(req.text, 'html.parser')
'''下方写爬取数据的代码'''
'''代码结束'''
但在其它的一些网页的表单分页数据的加载方式与上述不同,网页会在你选择不同的分页按钮后动态加载对应的数据。以下用获取某编程网站线上赛排行信息来进行分析
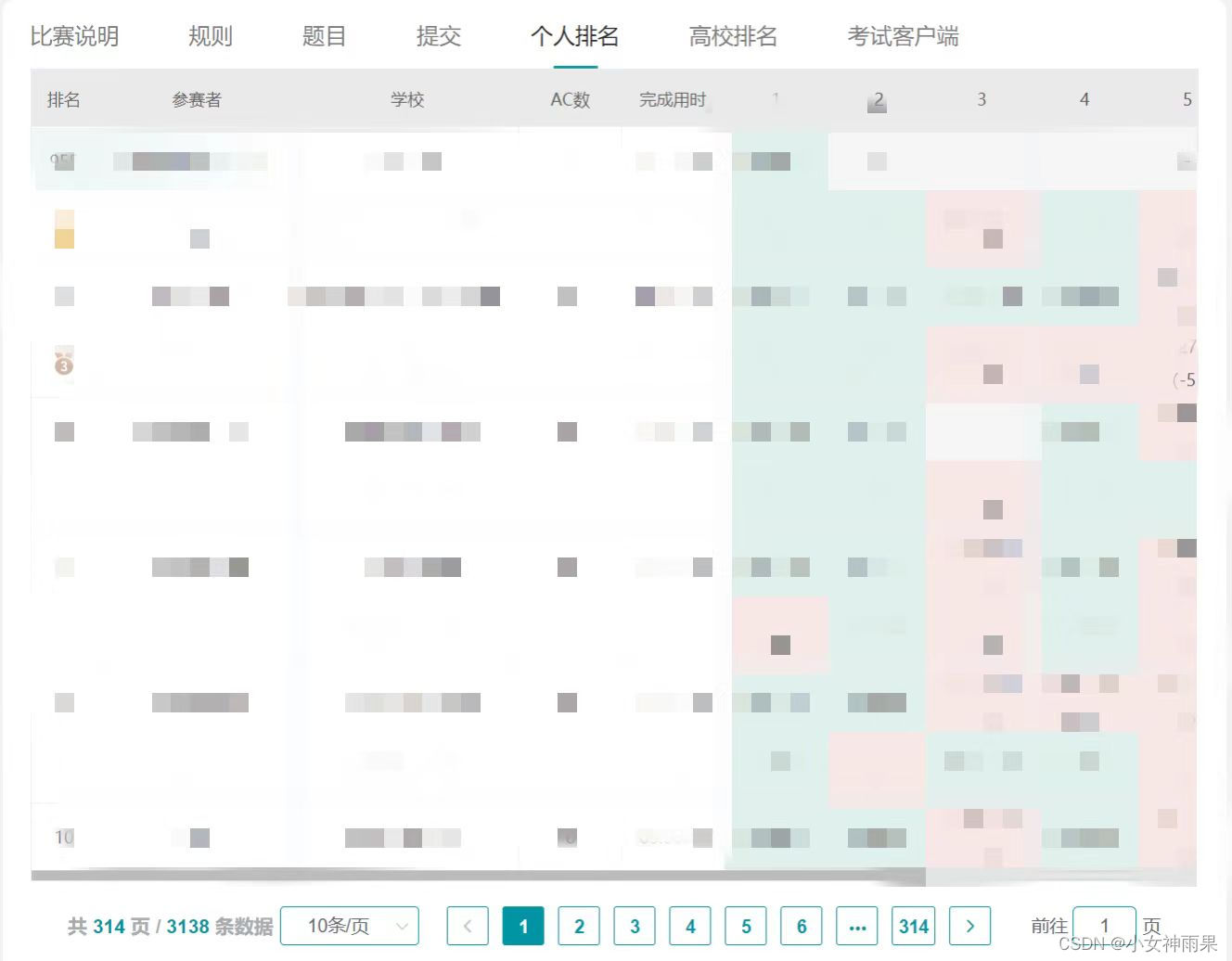
在切换分页时观察url并未发生变化,即可知不能通过遍历特征序号进行操作;此时打开控制台的“网络”页,再点击不同的分页按钮时观察到加载了一个“query"开头的文件,双击该文件再选择预览项可发现此文件包含网页分页的内容,此时考虑如何爬取这些数据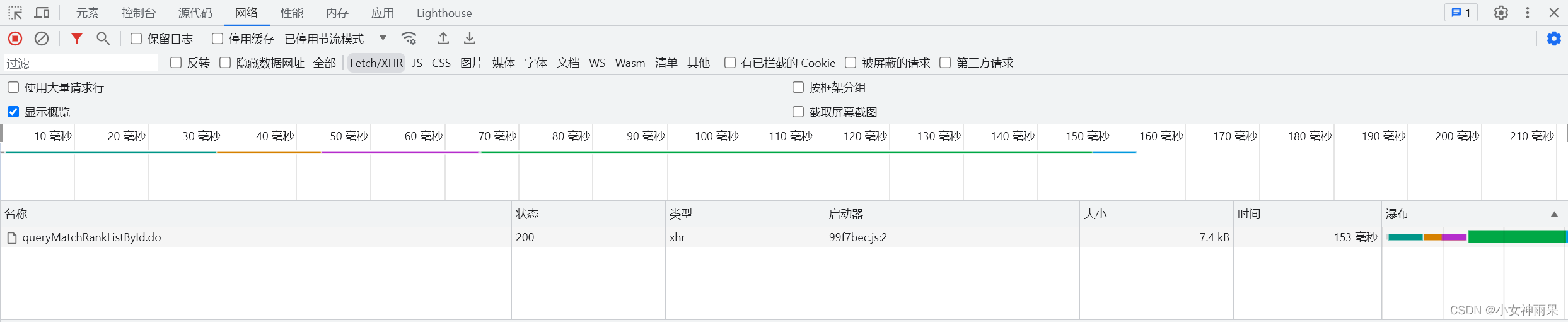
点击不同分页query文件的”载荷“选项发现”start"对应的值与”特征序号“有同样特性,此处是从0开始中间每页间隔10;按照此思路模仿爬取豆瓣电影的操作,代码实现如下
import requests
import json
url = "https://www.matiji.net/exam-back/pc/queryMatchRankListById.do"#query文件地址
head = {'User-Agent': ''}#值从标头获取
num=0
while num<=3130:
data = {'start': num,'limit': 10,'matchId': 144}
res = requests.post(url, headers=head, data=data)
ans = json.loads(res.text)["data"]
ans0=ans['datas']
'''下面写爬取数据的逻辑'''
'''代码结束'''


















 1359
1359

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









