






一、实验要求
(1)搭建Hadoop平台。
(2)使用Hadoop的MapReduce编程框架实现矩阵相乘。
(3)分析MapReduce并行编程模型的效率。
二、实验过程
(一)Hadoop的安装
1、下载虚拟机软件Vmware Workstation
本实验中我下载的版本是VMware Workstation 17.6.1
下载地址:https://softwareupdate.vmware.com/cds/vmw-desktop/ws/
2、下载Ubuntu系统镜像
本实验中我下载的版本是Ubuntu 24.04.1 LTS
下载地址:https://ubuntu.com/download/desktop
3、创建一个新账户
(1)使用CTRL+ALT+T打开命令行终端,输入命令创建新用户
sudo useradd -m lihongxia -s /bin/bash
注:“lihongxia” 是我的虚拟机账户名,在后续所有实验过程中,要把账户名换成自己的
(2)给新用户设置密码
sudo passwd lihongxia
(3)给新用户增加管理员权限
sudo adduser lihongxia sudo
(4)注销当前用户,登录新建的lihongxia账户
4、安装VM-tools
(1)打开终端,删除原来安装后的文件
sudo apt autoremove open-vm-tools
(2)输入安装命令
sudo apt install open-vm-tools
sudo apt install open-vm-tools-desktop
(3)重启虚拟机后即可进行粘贴复制
5、在Ubuntu中挂载共享文件夹
(1)在D盘新建一个共享文件夹VMshare,点击虚拟机设置,然后按照图片中顺序依次点击,选择要共享的文件夹路径。
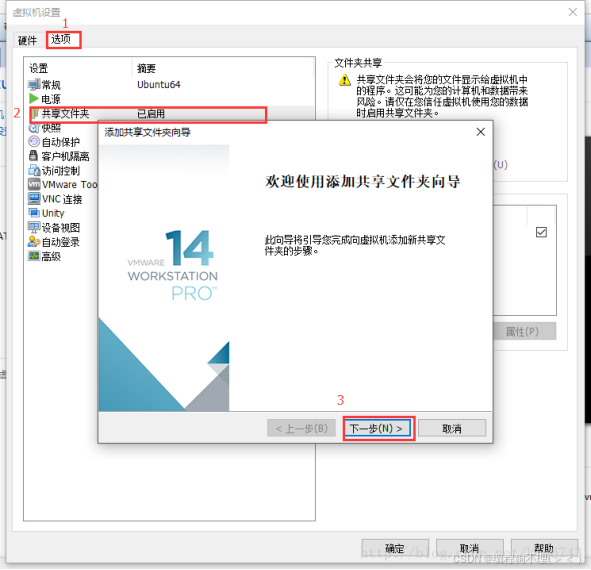

(2)挂载共享文件夹
sudo mount -t fuse.vmhgfs-fuse .host:/ /mnt/hgfs -o allow_other
此方法不足之处是每次重启虚拟机都需要挂载一次,可在.bashrc文件中添加下述代码实现永久挂载
sudo mount -t fuse.vmhgfs-fuse .host:/ /mnt/hgfs -o allow_other
(3)共享文件夹存放在/mnt/hgfs目录下,可通过ls命令来查看


6、安装一些必要的工具
(1)更新apt-get
sudo apt-get update (将用户模式切换到根模式)
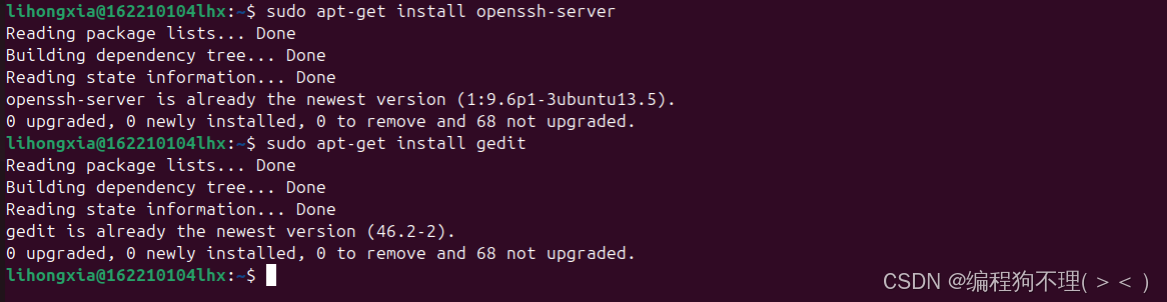
(2)安装ssh服务
sudo apt-get install openssh-server
(3)安装gedit
sudo apt-get install gedit
此处显示我已经安装过
7、配置免密登录
(1) 禁用防火墙
ufw disable
ufw status //查看防火墙状态

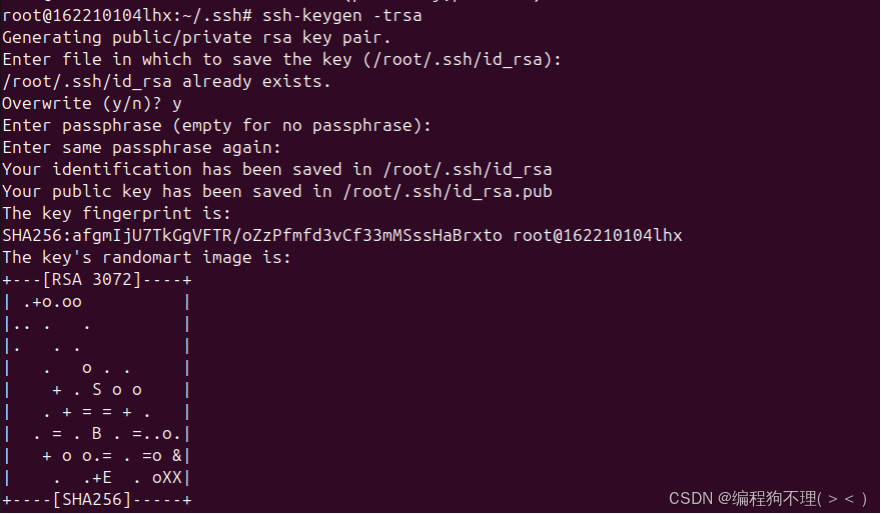
(2)生成密钥对,一路回车,在~/.ssh目录会生成两个文件,id_rsa和id_rsa.pub
cd ~/.ssh
ssh-keygen -t rsa

(3)将公钥复制到localhost
cat ./id_rsa.pub >> ./authorized_keys
(4)登录测试
ssh localhost

(5)输入exit退出连接
8、安装并配置jdk
(1)在家目录(~)下新建/app 文件夹
mkdir ~/app
(2)在真机中将jdk、hadoop的安装包复制到真机的共享文件夹中
(3)安装jdk
tar -zxvf /mnt/hgfs/VMshare/jdk-8u151-linux-x64.tar.gz -C /home/lihongxia/app //解压
mv /home/lihongxia/app/jdk1.8.0_151 /home/lihongxia/app/jdk //改名
(4)配置jdk
编辑配置文件.bashrc
gedit ~/.bashrc
然后在.bashrc文件中添加下面这段代码
export JAVA_HOME=/home/lihongxia/app/jdk
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
编译配置文件 .bashrc
source ~/.bashrc
然后输入java -version可查看jdk是否安装好

9、安装并配置Hadoop
(1)安装Hadoop
tar -zxvf /mnt/hgfs/VMshare/hadoop-2.10.2.tar.gz -C /home/lihongxia/app //解压
mv /home/lihongxia/app/hadoop-2.10.2 /home/lihongxia/app/hadoop //改名
sudo chown -R lihongxia ./hadoop //修改hadoop权限
(2)配置Hadoop
①配置环境变量
gedit ~/.bashrc
在配置文件中添加:
export HADOOP_HOME=/home/lihongxia/app/hadoop
exportPATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
②配置hadoop-env.sh
gedit /home/lihongxia/app/hadoop/etc/hadoop/hadoop-env.sh
找到export JAVA_HOME=${JAVA_HOME}这一行,将其修改为:
export JAVA_HOME=/home/lihongxia/app/jdk
③配置core-site.xml
gedit /home/lihongxia/app/hadoop/etc/hadoop/core-site.xml
在配置文件中添加:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/app/hadoop/tmp</value>
</property>
</configuration>
④配置hdfs-site.xml
gedit /home/lihongxia/app/hadoop/etc/hadoop/hdfs-site.xml
在配置文件中添加:
<configuration>
<property>
<!--配置块的副本数 -->
<name>dfs.replication</name>
<value>1</value>
<name>hadoop.tmp.dir</name>
<value>/opt/module/tmp</value>
</property>
</configuration>
⑤配置mapred-site.xml
gedit /home/lihongxia/app/hadoop/etc/hadoop/mapred-site.xml.template
在配置文件中添加:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
⑥配置yarn-site.xml
gedit /home/lihongxia/app/hadoop/etc/hadoop/yarn-site.xml
在配置文件中添加:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
10、运行Hadoop
(1)格式化namenode
cd /home/lihongxia/app/hadoop/bin
./hadoop namenode -format
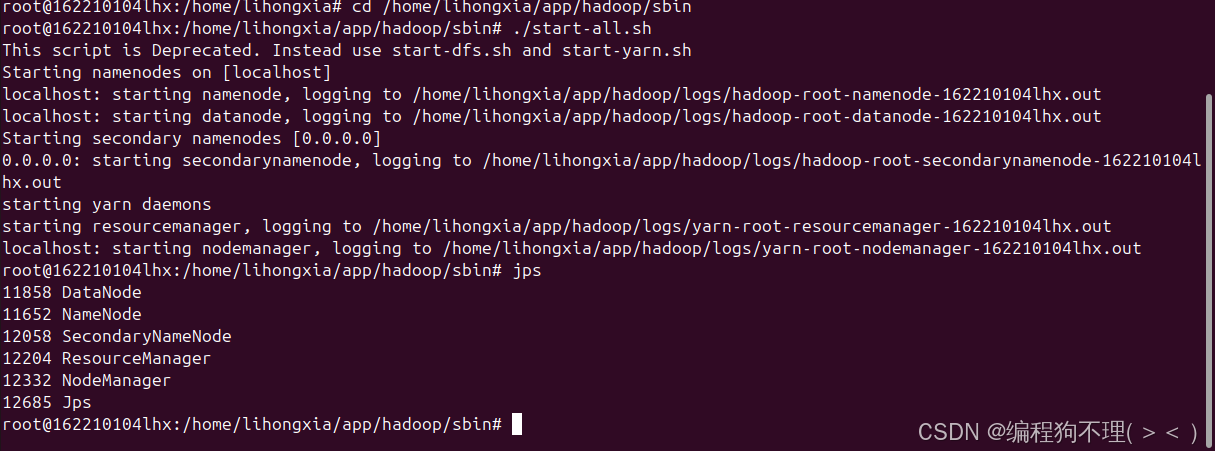
(2)运行Hadoop(要在用户模式下)
cd /home/lihongxia/app/hadoop/sbin
./start-all.sh
(3)查看进程 jps
不能缺少任何一个节点,如果缺少的话见遇到的问题及解决方法(3)
(二)测试wordcount程序
1、生成单词文件
mkdir ~/tmp
echo 'hello world hello hadoop' > ~/tmp/word1.txt
echo 'hive run on hadoop' > ~/tmp/word2.txt

2、上传至hdfs
(在~/app/hadoop/bin目录下)
./hdfs dfs -mkdir /input //新建输入数据的目录
./hdfs dfs -put ~/tmp/word*.txt /input //上传文件

(此处显示我已经上传过)
3、运行hadoop自带的单词计数程序
./hadoop jar /home/lihongxia/app/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.2.jar wordcount /input output
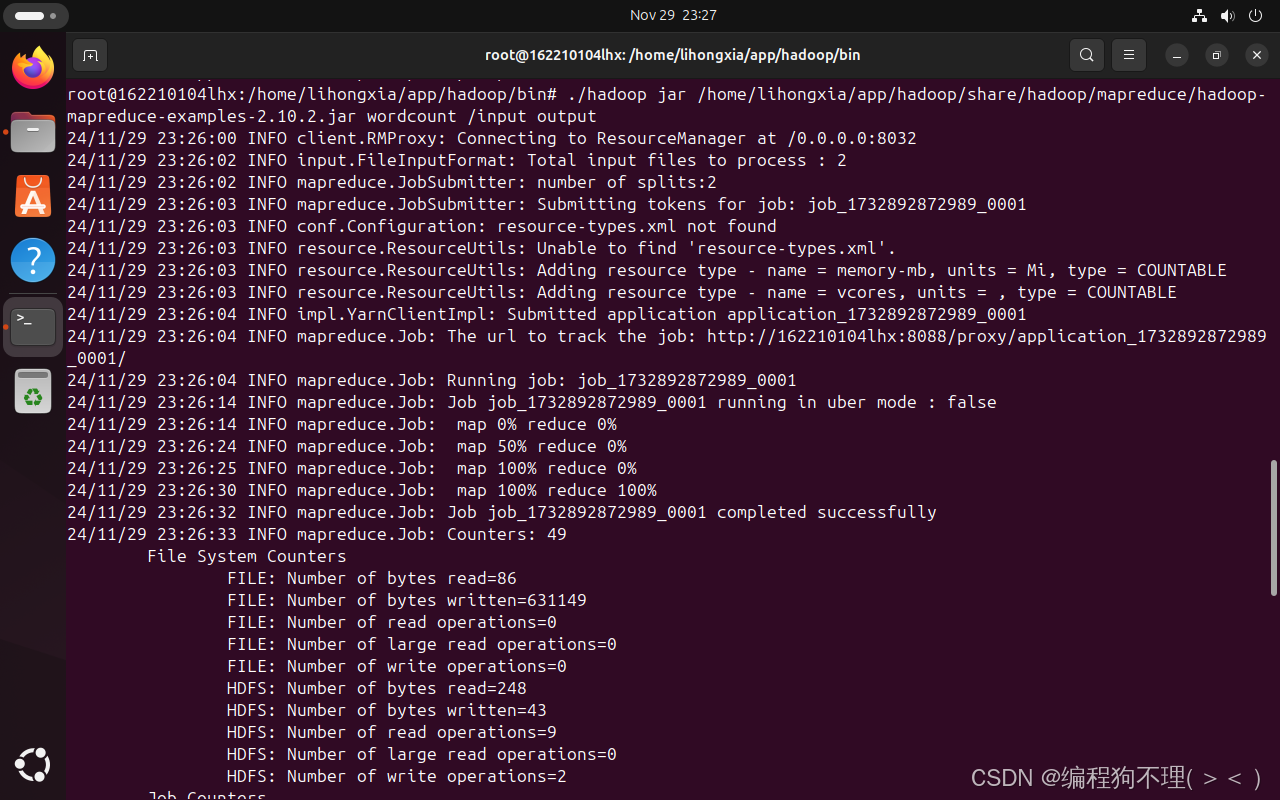
4、运行结果
./hdfs dfs -cat /user/root/output/part-r-00000 //可以看到每个单词出现的次数
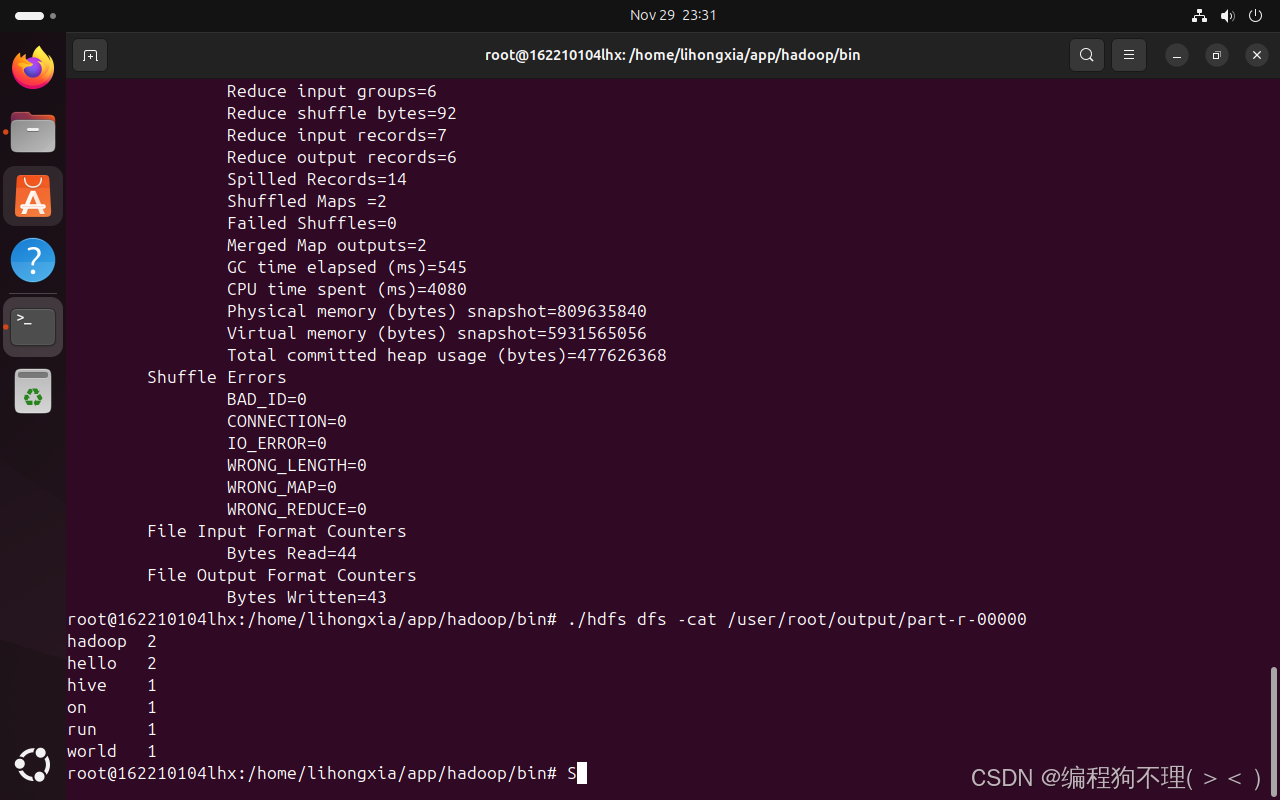
(三)利用Hadoop实现矩阵乘法
1、编写代码,得到源文件MartrixMultiplication.java
源代码:
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class MartrixMultiplication{
public static class MartrixMapper extends Mapper<Object,Text, Text, Text>{
private Text map_key = new Text();
private Text map_value = new Text();
int rNumber = 2;
int cNumber = 2; //一个2*2的矩阵
String fileTarget;
String i, j, k, ij, jk;
public void map(Object key, Text value,Context context) throws IOException, InterruptedException { //Map函数
String eachterm[] =value.toString().split("#");
fileTarget = eachterm[0];
if(fileTarget.equals("M"))
{
i = eachterm[1];
j = eachterm[2];
ij = eachterm[3];
for(int c = 1; c<=cNumber; c++)
{
map_key.set(i + "#" +String.valueOf(c));
map_value.set("M" +"#" + j + "#" + ij);
context.write(map_key,map_value);
}
}
else if(fileTarget.equals("N"))
{
j = eachterm[1];
k = eachterm[2];
jk = eachterm[3];
for(int r = 1; r<=rNumber; r++)
{
map_key.set(String.valueOf(r) +"#" +k);
map_value.set("N" +"#" + j + "#" + jk);
context.write(map_key,map_value);
}
}
}
}
public static class MartrixReducer extends Reducer<Text,Text,Text,Text> {
private Text reduce_value = new Text();
int jNumber = 2;
int M_ij[] = new int[jNumber+1];
int N_jk[] = new int[jNumber+1];
int j, ij, jk;
String fileTarget;
int jsum = 0;
public void reduce(Text key,Iterable<Text> values, Context context) throws IOException,InterruptedException { //reduce函数
jsum = 0;
for (Text val : values)
{
String eachterm[] =val.toString().split("#");
fileTarget = eachterm[0];
j = Integer.parseInt(eachterm[1]);
if(fileTarget.equals("M"))
{
ij= Integer.parseInt(eachterm[2]);
M_ij[j]= ij;
}
else if(fileTarget.equals("N")){
jk= Integer.parseInt(eachterm[2]);
N_jk[j]= jk;
}
}
for(int d = 1; d<=jNumber; d++)
{
jsum += M_ij[d] * N_jk[d];
}
reduce_value.set(String.valueOf(jsum));
context.write(key, reduce_value);
}
}
public static void main(String[] args) throws Exception { //main函数入口
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage:MartrixMultiplication <in> <out>");
System.exit(2);
}
Job job = new Job(conf,"martrixmultiplication");
job.setJarByClass(MartrixMultiplication.class);
job.setMapperClass(MartrixMapper.class);
job.setReducerClass(MartrixReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ?0 : 1);
}
}
2、编写测试用例M.txt
M.txt中的数据形式为:(一行一个数据)
M#a#b#c 表示M矩阵第a行第b列的值是c;
N#a#b#c 表示N矩阵第a行第b列的值是c;
本实验的测试用例是一个2行2列和一个2行三列的矩阵

3、在虚拟机/home/lihongxia/app/hadoop目录下新建文件夹:local_matrix和input,把修改好的MartrixMultiplication.java文件和测试文件M.txt通过共享文件夹分别放到local_matrix,input
mv /mnt/hgfs/VMshare/MartrixMultiplication.java/home/lihongxia/app/hadoop/local_matrix/MartrixMultiplication.java
mv /mnt/hgfs/VMshare/M.txt /home/lihongxia/app/hadoop/input/M.txt
4、编译MartrixMultiplication.java文件,生成class文件
javac -classpath share/hadoop/common/hadoop-common-2.10.2.jar:share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.10.2.jar:share/hadoop/common/lib/commons-cli-1.2.jar -d local_matrix local_matrix/MartrixMultiplication.java
5、打包发布,生成MartrixMultiplication.jar文件
jar -cvf local_matrix/MartrixMultiplication.jar -C local_matrix/ .
6、在hdfs上新建输入数据的目录并上传文件
./hdfs dfs -mkdir /input2
./hdfs dfs -put -f /home/lihongxia/app/hadoop/input/M.txt /input2
7、运行hadoop矩阵相乘程序
./hadoop jar /home/lihongxia/app/hadoop/local_matrix/MartrixMultiplication.jar MartrixMultiplication /input2/M.txt output2
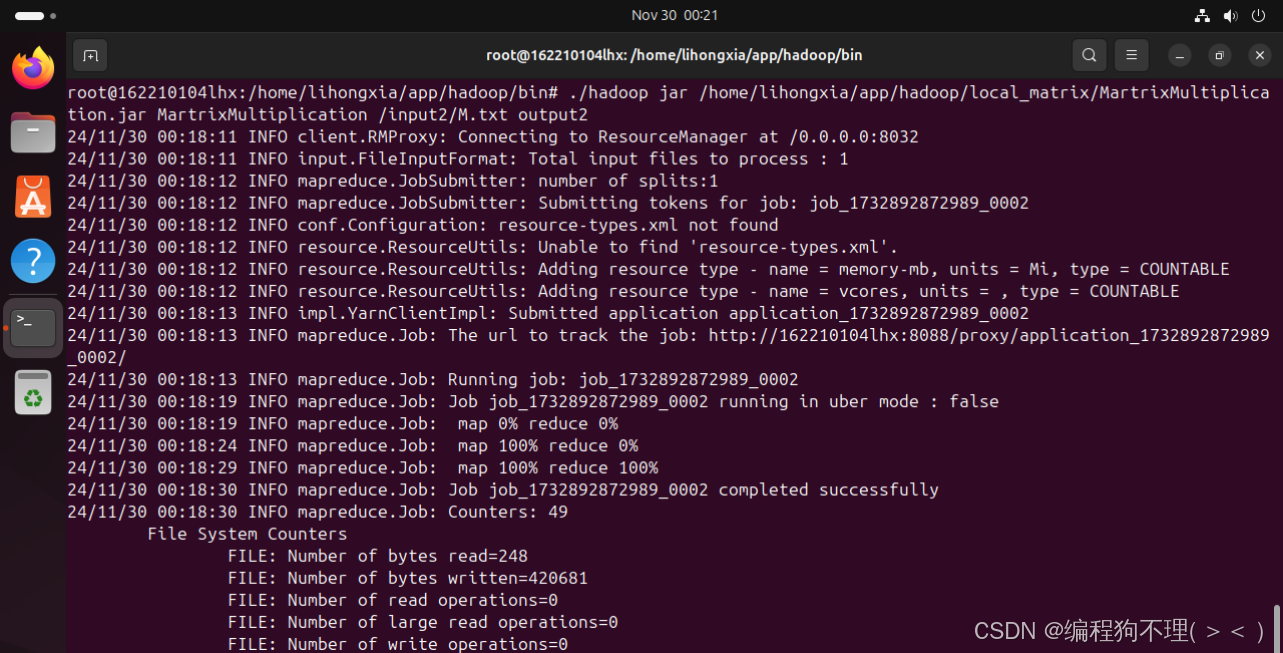
8、运行结果
./hdfs dfs -cat /user/root/output2/part-r-00000 //查看运行结果
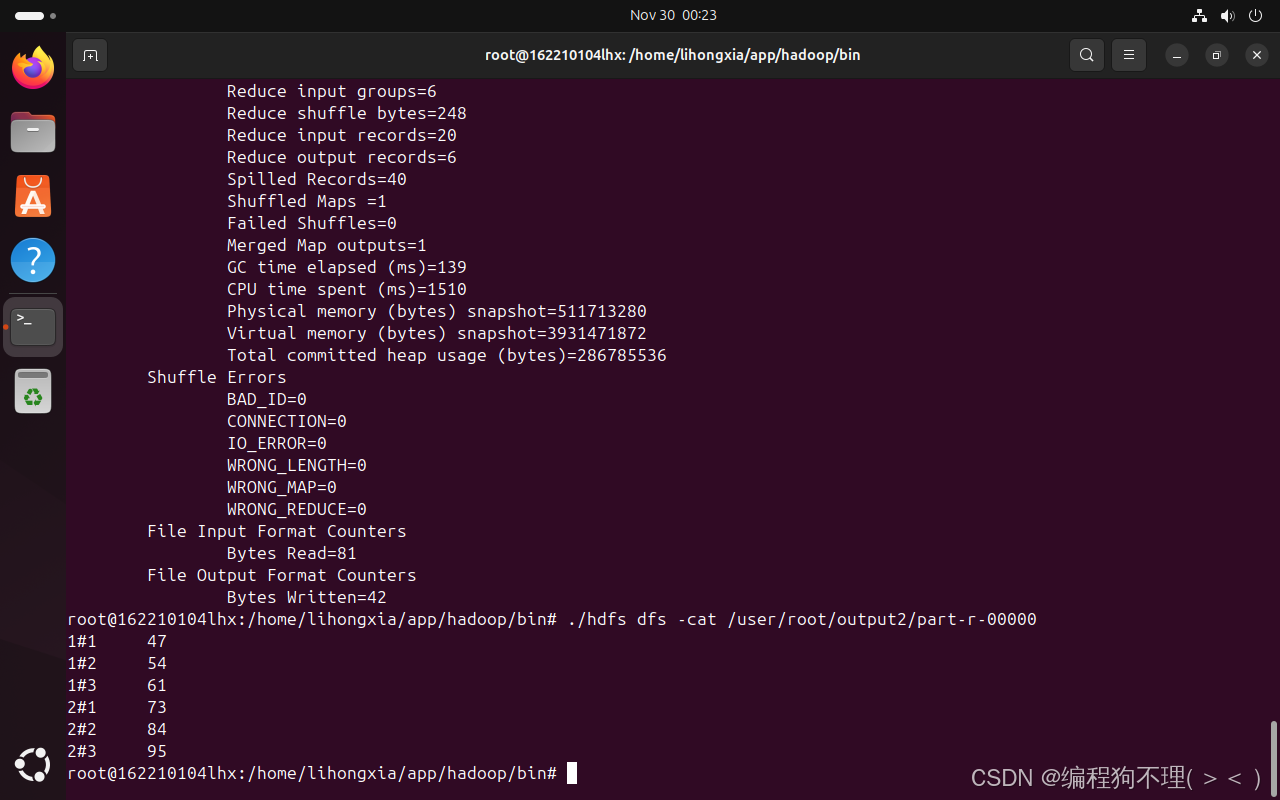
在Web UI上查看:
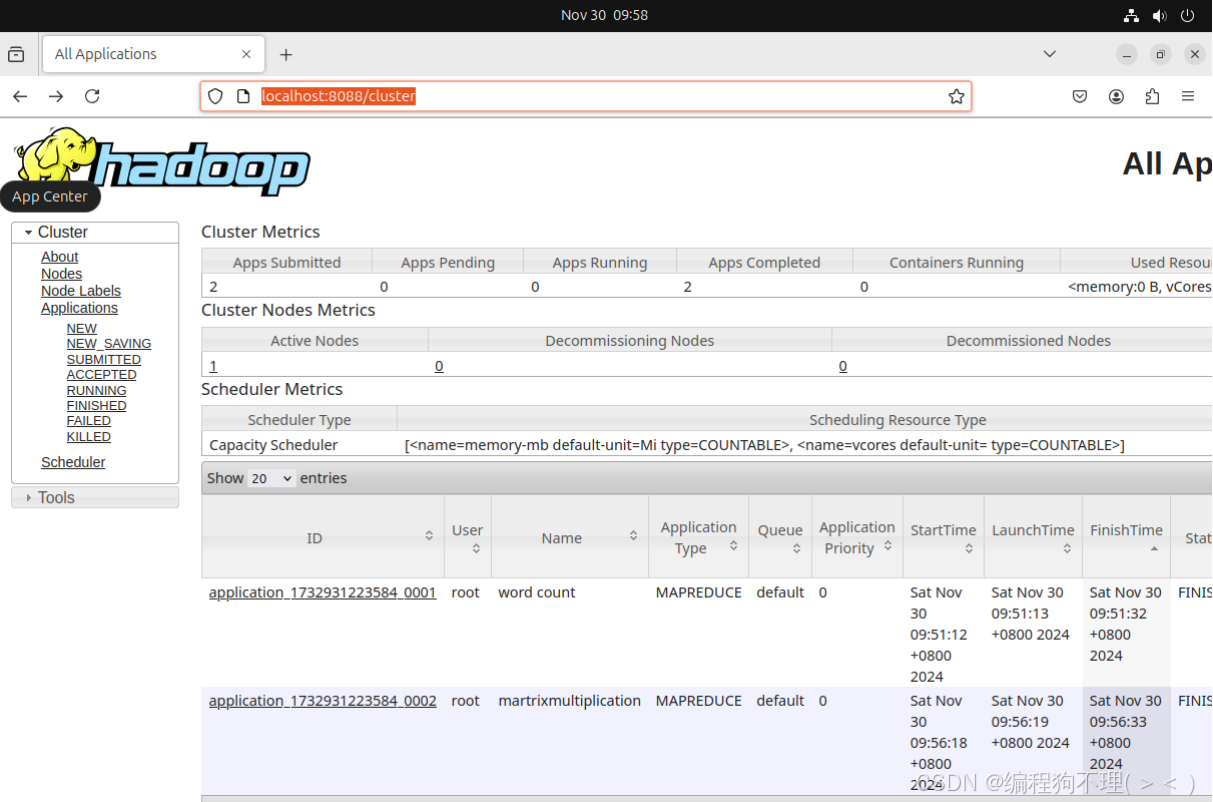
三、遇到的问题及解决方法
问题一:按照ppt教程上的步骤点击重新安装VMtools,一直出现如下错误
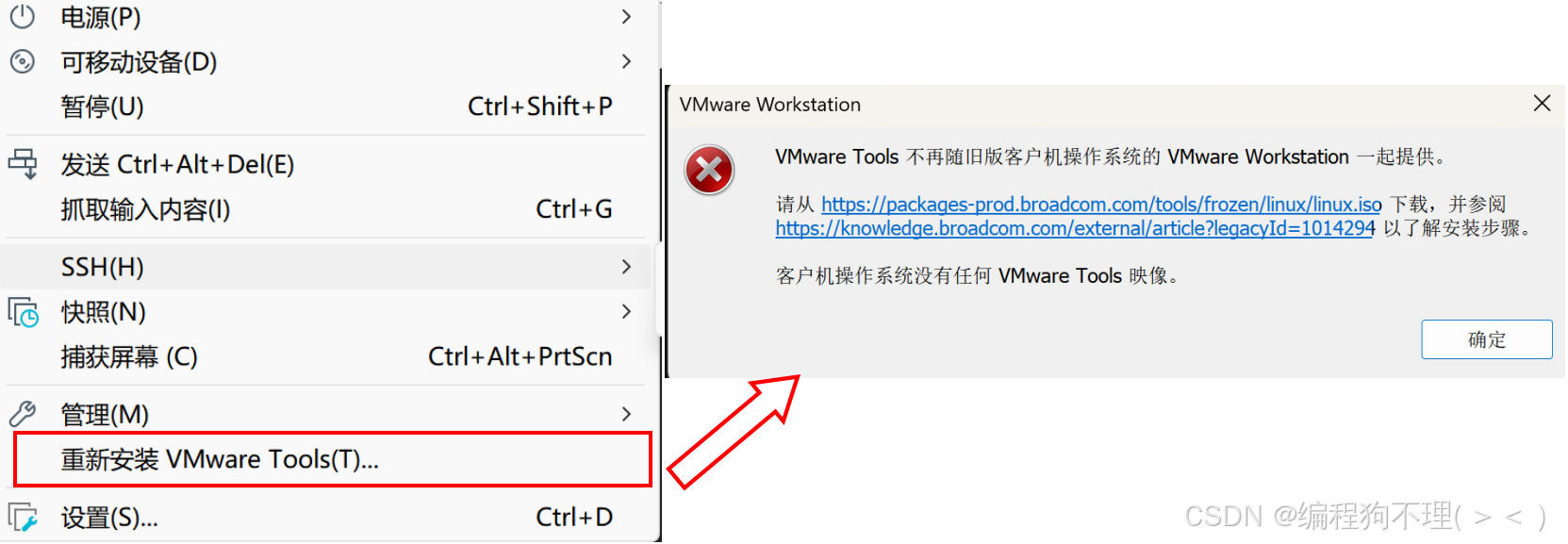
解决方案:使用命令行终端下载VMtools,具体代码如下:
sudo apt autoremove open-vm-tools
sudo apt install open-vm-tools
sudo apt install open-vm-tools-desktop
问题二:虽然下载了VMtools,但是只能粘贴复制代码、文字,不能粘贴复制文件,jdk和hadoop的安装包无法传到虚拟机,也找不到虚拟机中的共享文件夹。
解决方案:在虚拟机中挂载共享文件夹,在命令行输入如下代码,即可将共享文件夹挂载在/mnt/hgfs/目录下。之后使用mv命令可将共享文件夹下的文件移动到虚拟机任意目录下。
sudo mount -t fuse.vmhgfs-fuse .host:/ /mnt/hgfs -o allow_other
/mnt/hgfs/ 是挂载点
-o allow_other 表示普通用户也能访问共享目录
但这种使用这种方法每次重启虚拟机都需要重新挂载,可在.bashrc文件中添加
sudo mount -t fuse.vmhgfs-fuse .host:/ /mnt/hgfs -o allow_other 实现永久挂载
问题三:配置完成Hadoop后,运行进程只有3个,缺少NameNode、NodeManager、ResourceManager。
解决方案:缺少NodeManager、ResourceManager是jdk版本的问题,需要重新安装并配置jdk18(此处还是采用共享文件夹的方式传送jdk18的安装包,然后将原来的jdk21删除,将jdk18放进/home/lihongxia/app/jdk/目录下,由于jdk文件名和路径没有改变,所以不需要修改环境变量)。而缺少NameNode需要修改Hadoop配置文件hdfs-site.xml,具体修改方式如下:
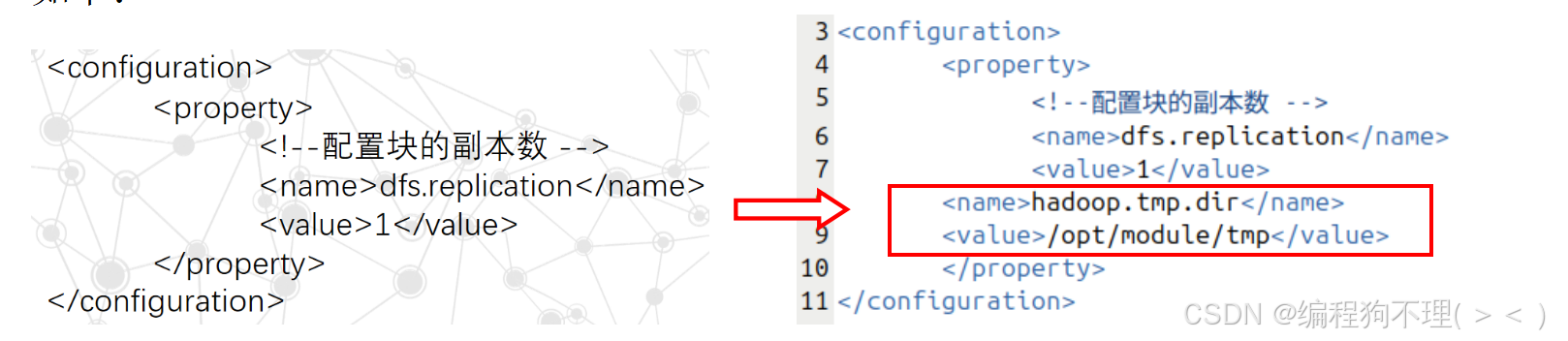
问题四:测试用例M.txt是2×2的矩阵,但是运行结果出现了超过2行的数据。
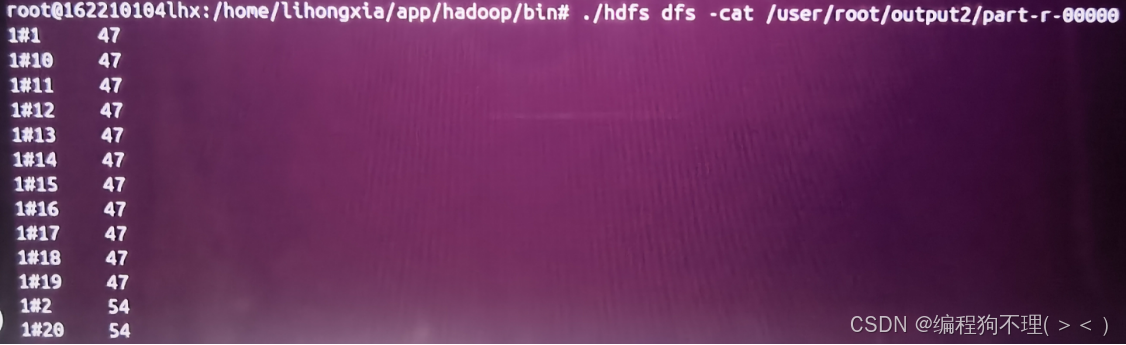
解决方案:源代码中rNumber和cNumber的值不正确,将50改成2即可。

问题五:在第二次运行程序的时候,程序会报错,显示将Hadoop作业的输出写入一个已经存在的hdfs目录。在Hadoop中,输出目录必须是空的或者不存在的,以防止数据覆盖

解决方案:删除现有的输出目录,即可正常运行
hdfs dfs -rm -r hdfs://localhost:9000/user/root/output2

四、总结和体会
在这次云计算实验中,我不仅加深了对专业知识的理解,还积累了宝贵的实践经验,特别是在文件路径理解和Hadoop分布式系统应用方面有了更深入的认识。除此之外,这次实验令我收获最大的是解决错误的能力得到加强。
在实验过程中,我遇到的最频繁的问题就是文件路径找不到,最初,每当遇到路径错误的时候,我都点进文件夹里,一步一步去找,然后再复制正确的路径,这样做显然效率很低,而且有的文件我根本不知道存放在哪里,没有办法下手。通过不断尝试和在网上查找资料,我逐渐掌握了使用 cd /xx/xx命令进入指定目录的方法,并通过ls命令查看目录下的所有文件,通过mv指令将文件移动到指定的路径下,这些基本命令的熟练应用帮我解决了许多路径问题。同时,我也深刻体会到路径的重要性,在云计算和分布式系统中,文件路径的准确性直接关系到数据的存取效率和系统的稳定性。
除此外,我也加深了对Hadoop分布式系统的深入理解。Hadoop作为大数据处理领域的经典框架,其分布式存储和分布式计算的能力让我印象深刻,通过实验,我不仅学会了Hadoop的基本配置和使用方法,还深入了解了其内部的工作机制和原理,特别是在处理大规模数据集时,hadoop的分布式处理能力展现出了巨大的优势。
对我而言,这次实验收获最大的就是错误解决能力的提升。在之前的各种实验中,遇到错误的时候,我都会先自己阅读错误提示,分析错误所在,然后通过上网查找资料解决错误,但这次我很多时候根本看不懂错误提示或者找不到错误提示在哪里,因此,我学会了利用chatgpt、文心一言来帮助我查找错误,这些工具能够我给出的错误描述,快速给出错误可能出现的原因和解决方案,还会帮我找到一些参考资料。在实验中,我多次利用这些工具来分析错误日志,极大地提高了我的问题解决效率。当然,如何准确地向这些AI工具描述我的错误以便它们能更加准确地分析出我的错误也是我在这次实验中有所提高的能力和以后要多加练习的能力。
总之,这次云计算实验是一次非常宝贵的学习经历,它不仅让我学到了专业知识,还锻炼了我的实践能力和解决问题的能力。我相信,在未来的学习和工作中,我将能够不断进步,学习更多技能,提升更多能力。
五、参考资料
张老师的ppt
https://zhuanlan.zhihu.com/p/650638983
https://blog.youkuaiyun.com/weixin_44016035/article/details/117376246
https://blog.youkuaiyun.com/m0_61530293/article/details/128399748

















 1277
1277

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









