







code
论文介绍 FreeControl: 无需额外训练实现文本到图像的空间操控!_freecontrol: training-free spatial control of any -优快云博客
Abstract
最近的方法,如ControlNet[59],为用户提供了对文本到图像(T2I)扩散模型的细粒度空间控制。然而,辅助模块必须针对每种类型的空间条件、模型架构和检查点进行训练,这使得它们与人类设计师在内容创建过程中想要传达给AI模型的各种意图和偏好不一致。在这项工作中,我们提出了FreeControl,这是一种可控制的T2I生成的免培训方法,同时支持多种条件、架构和检查点。FreeControl设计了结构引导,以促进与引导图像的结构对齐,并设计了外观引导,以实现使用相同种子生成的图像之间的外观共享。广泛的定性和定量实验证明了FreeControl在各种预训练的T2I模型中的优越性能。特别是,FreeControl可以方便地对许多不同的架构和检查点进行免培训控制,允许大多数现有免培训方法失败的具有挑战性的输入条件,并通过基于培训的方法实现具有竞争力的合成质量。
Introduction
经过训练的模型倾向于优先考虑空间条件而不是文本描述,这可能是因为输入-输出图像对的紧密空间对齐暴露了一条捷径。

为了解决这些限制,我们提出了FreeControl,这是一种用于可控T2I扩散的通用免训练方法。
我们的主要动机是,在生成过程中,T2I模型中的特征图已经捕获了输入文本中描述的空间结构和局部外观。通过对这些特征的子空间进行建模,我们可以有效地将生成过程导向引导图像中表达的类似结构,同时保留输入文本中概念的外观。
为此,FreeControl结合了分析阶段和合成阶段。在分析阶段,FreeControl查询T2I模型以生成最少一个种子图像,然后从生成的图像构建线性特征子空间。在合成阶段,FreeControl在子空间中使用制导来促进与制导图像的结构对齐,以及在有控制和没有控制的情况下生成的图像之间的外观对齐。
贡献:
(1)通过对中间扩散特征的线性子空间进行建模,并在生成过程中对该子空间进行引导,提出了一种新的无训练可控T2I生成方法FreeControl。
(2)我们的方法提供了第一个通用的免训练解决方案,支持多种控制条件(草图、法线图、深度图、边缘图、人体姿势、分割掩码、自然图像等)、模型架构(例如SD 1.5、2.1和SD- xl 1.0)和自定义检查站(例如使用DreamBooth[46]和LoRA[24])。
(3)与之前的无训练方法(例如,Plugand-Play[53])相比,我们的方法显示出更好的结果,并且与之前基于训练的方法(例如,ControlNet[59])相比,我们的方法取得了具有竞争力的性能。
Related Work
Text-to-image diffusion.
Controllable T2I diffusion.
Image-to-image translation with T2I diffusion.
Customized T2I diffusion.
Preliminary
Diffusion sampling.
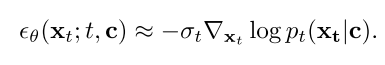
Guidance. 方程1中的更新规则可以通过与时间相关的能量函数g(xt;T, y)通过引导(强度为s)[14,15],使扩散采样条件为辅助信息y(如类标号):
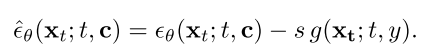
在实践中,g可以实现为分类器[14]或CLIP分数[34],也可以使用边界框[12,57]、注意图[18,37]或任何可测量的对象属性[15]来定义。
Attentions in ϵθ. ϵθ的标准选择是U-Net[45],具有多种分辨率的自关注和交叉关注[54]。从概念上讲,自注意模拟图像中空间位置之间的相互作用,而交叉注意将空间位置与文本提示中的标记联系起来。这两种注意机制相互补充,共同控制生成图像的布局[9,18,38,53]。
Training-Free Control of T2I Models
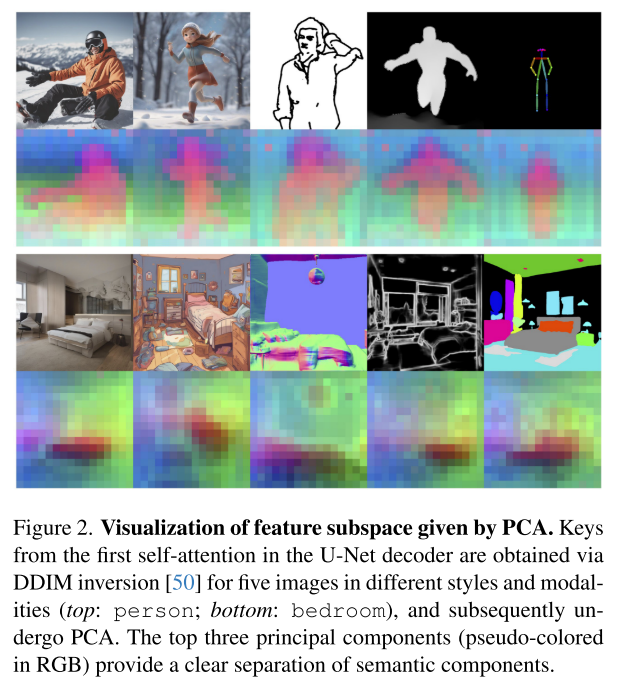
在预训练的ϵθ中,自注意力机制块特征的主要组成部分在广泛的图像模式中提供了强大且令人惊讶的一致的语义结构表示(参见图2中的示例)。为此,我们引入结构指导,在Ig的指导下,帮助起草I的结构模板。
为了用c描述的内容和风格纹理这个模板,我们进一步设计了外观指导,借用了¯I的外观细节,它是在不改变扩散过程的情况下生成的。最终,I模仿Ig的结构,其内容和风格与¯I相似。
Method overview.
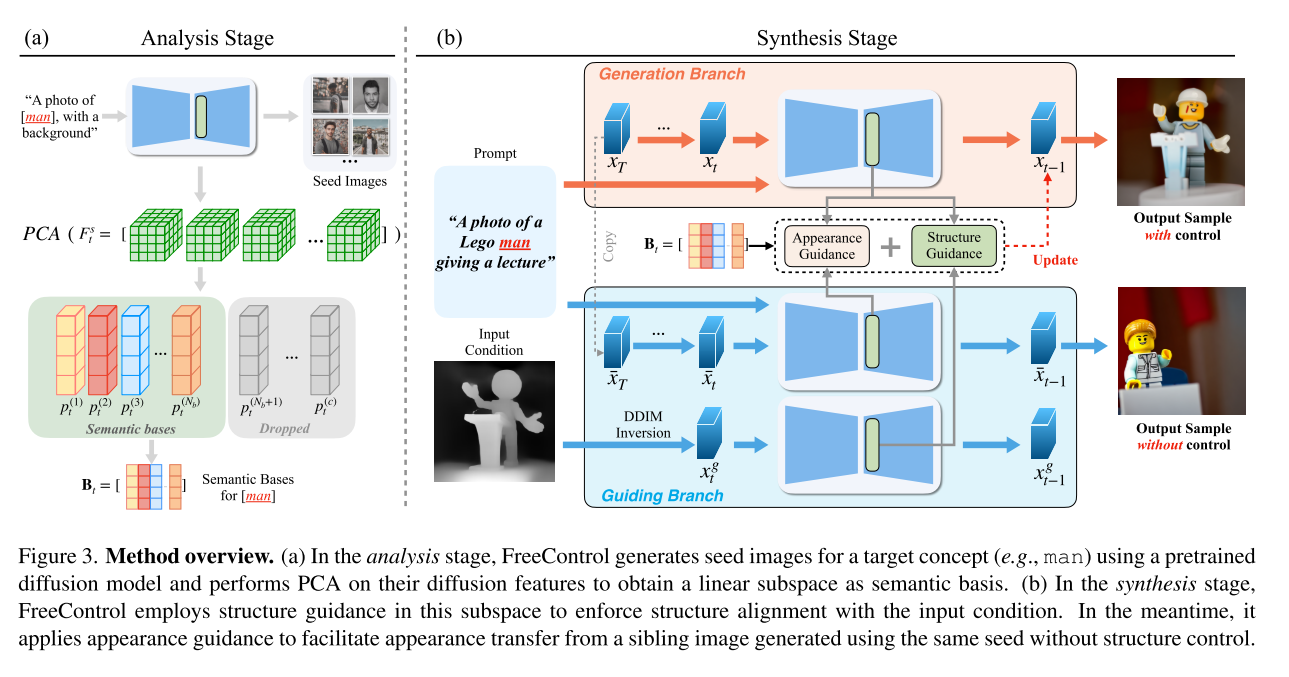
它从分析阶段开始,其中种子图像的扩散特征进行主成分分析(PCA),主要pc形成时间相关基Bt作为我们的语义结构表示。Ig随后进行DDIM反演[50],将其扩散特征投影到Bt上,得到它们的语义坐标Sg t。在合成阶段,结构引导通过吸引St到sgt来鼓励I发展与Ig相同的语义结构。同时,外观引导通过惩罚I和¯I特征统计的差异来提高它们之间的外观相似性。
Semantic Structure Representation
最近的研究发现自监督视觉变形[52]和T2I扩散模型[9]的自注意特征(即键和查询)是图像结构的强描述符。
为了解开图像结构和外观的纠缠,我们从Transformer特征可视化中获得灵感[35,53],对语义相似图像的自注意力机制特征进行PCA。我们的主要观察是,领先的pc形成了语义基础;它与物体姿势、形状和不同图像模式的场景构图有很强的相关性。
Analysis Stage
Seed images. 对于目标概念c,我们获取对应的Ns张图片。这些种子图像Is是从修改过的c生成的。具体地说,P2C将概念标记插入到有意保持通用的模板中(例如,“[]背景的照片。”)。重要的是,这允许{Is}覆盖不同的对象形状,姿势和外观以及图像组成和风格,这是语义基础表达能力的关键。
Semantic basis. 在Is上用DDIM反演,从网络θ获得尺寸为Ns ×C ×H ×W的相关扩散特征,产生了Ns ×H ×W个不同的特征向量,对此执行PCA获得时间相关语义信息Bt:
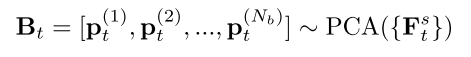
Bt跨越连接不同图像模态的语义空间St,允许在合成阶段中图像结构从IG传播到I。
Basis reuse. 一旦计算出来,Bt就可以被重复用于相同的文本提示,或者被具有相关概念的提示共享。因此,基础构建的成本可以在合成阶段的多次运行中摊销。
Synthesis Stage
I的产生以Ig为引导条件,表示Ig的语义基础是Bt。
Inversion of Ig. 对Ig进行反演获得大小为C ×H×W的扩散特征![]() ,并将其映射到Bt上获得大小为Nb × H ×W语义坐标
,并将其映射到Bt上获得大小为Nb × H ×W语义坐标![]() ,对于前景结构的局部控制,我们进一步从概念标记的交叉注意图中导出掩码M(大小H ×W)。M设置为1(大小H ×W),用于全局控制。
,对于前景结构的局部控制,我们进一步从概念标记的交叉注意图中导出掩码M(大小H ×W)。M设置为1(大小H ×W),用于全局控制。
Structure guidance. 在每个去噪步骤t处,我们通过将扩散特征Ft从ϵθ投影到Bt上来获得语义坐标St。我们用于结构引导的能量函数gs可以表示为:

其中i和j是St、Sg t和M的空间索引,w是平衡权重。阈值τt定义为:
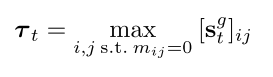
每个频道最大值。不严格地说,[st]ij > τt表示前景结构的存在。直觉上,前向项引导I的结构与前景中的IG对齐,而后向项在M = 1时有效,通过抑制背景中的虚假结构来帮助分割前景。
Appearance representation. 受DSG [15]的启发,我们将图像外观表示为![]() ,扩散特征的加权空间平均值Ft:
,扩散特征的加权空间平均值Ft:
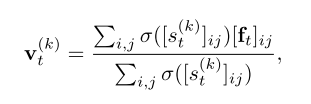
其中i和j是St和Ft的空间索引,k是[st]i,j的信道索引,σ是S形函数。我们将St重新用作权重,以便不同的v(k)t对不同语义分量的外观进行编码。我们在每个时间步t分别计算I和I的![]() 和
和![]() 。
。
Appearance guidance. 我们的用于外观引导的能量函数ga然后可以表示为:
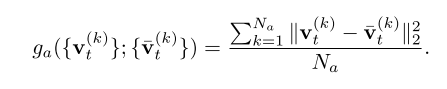
它惩罚了外观表征的差异,从而促进了从I到I的外观转移。
Guiding the generation process.最后,我们通过将结构和外观指导与无分类器指导一起纳入修改后的分数估计 ^ϵt [21]:
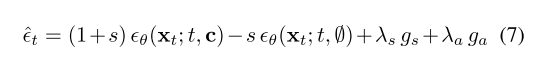
其中 s、λs 和 λa 分别是引导强度。



















 962
962

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











