







一,图的遍历
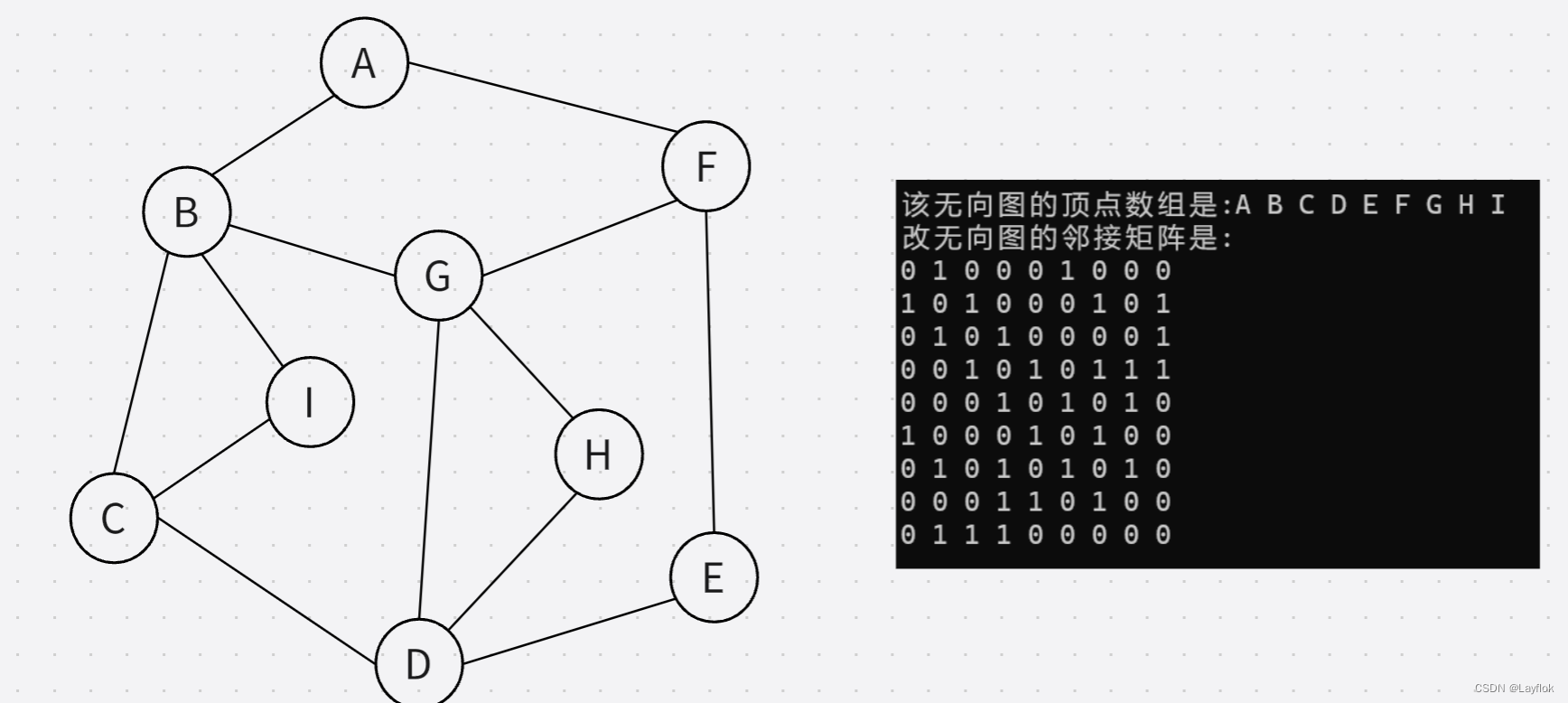
图的遍历呢一共就分为两种-----深度优先遍历(DFS)和广度优先遍历(BFS)。其实这两种算法在时间上是没有什么优劣之分的,不同之处仅仅在于对顶点的访问顺序。一下的遍历将会在下图中展开。
二,深度优先(DFS)
所谓深度优先的算法思想就是先一条路走到黑,直到前面的路都走过了,就返回去,重新走没走过的路,递归实现。
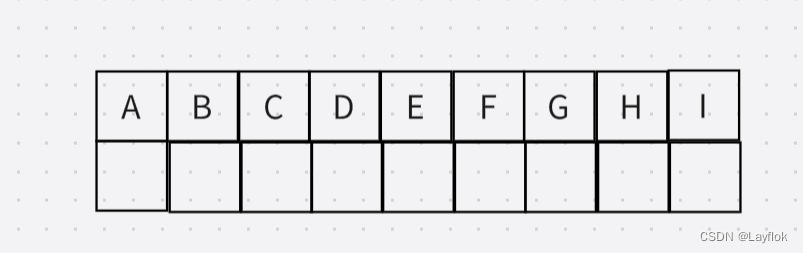
第一步:首先我们得构造一个辅助数组,来表示自己的到底访问过这个顶点没有。
int i;
for (i = 0; i < G.vexnum; i++)
{
visit[i] = FALSE; //初始化辅助数组全为未访问过。
}
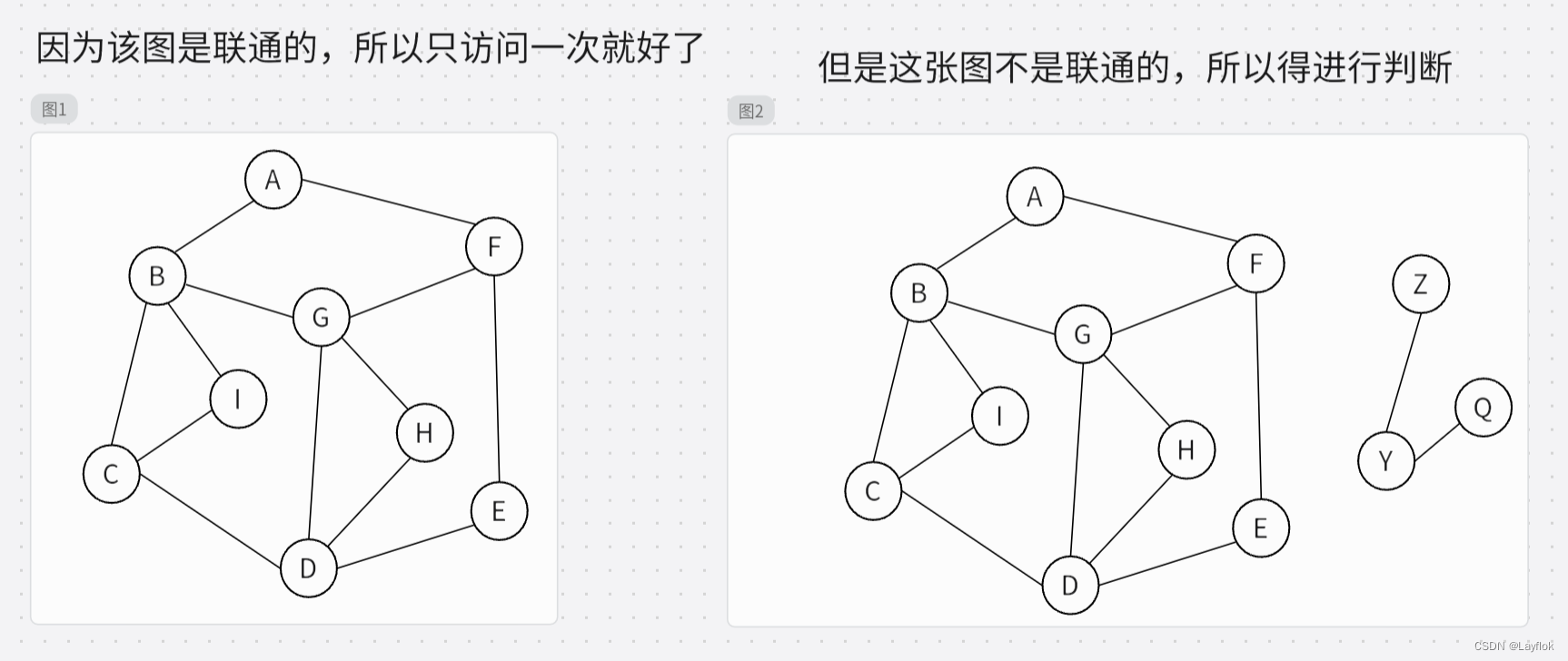
第二步:传入一个顶点过去,并且该顶点必须是没访问过的顶点.
//若是联通图,只需要进行一次即可。
for (i = 0; i < G.vexnum; i++)
{
if(visit[i] != TRUE)
{
AMDFS(G,i);
}
}
至于代码中为何会有for循环,直接把图中的一个顶点传入不就好了。看完下图就懂了。
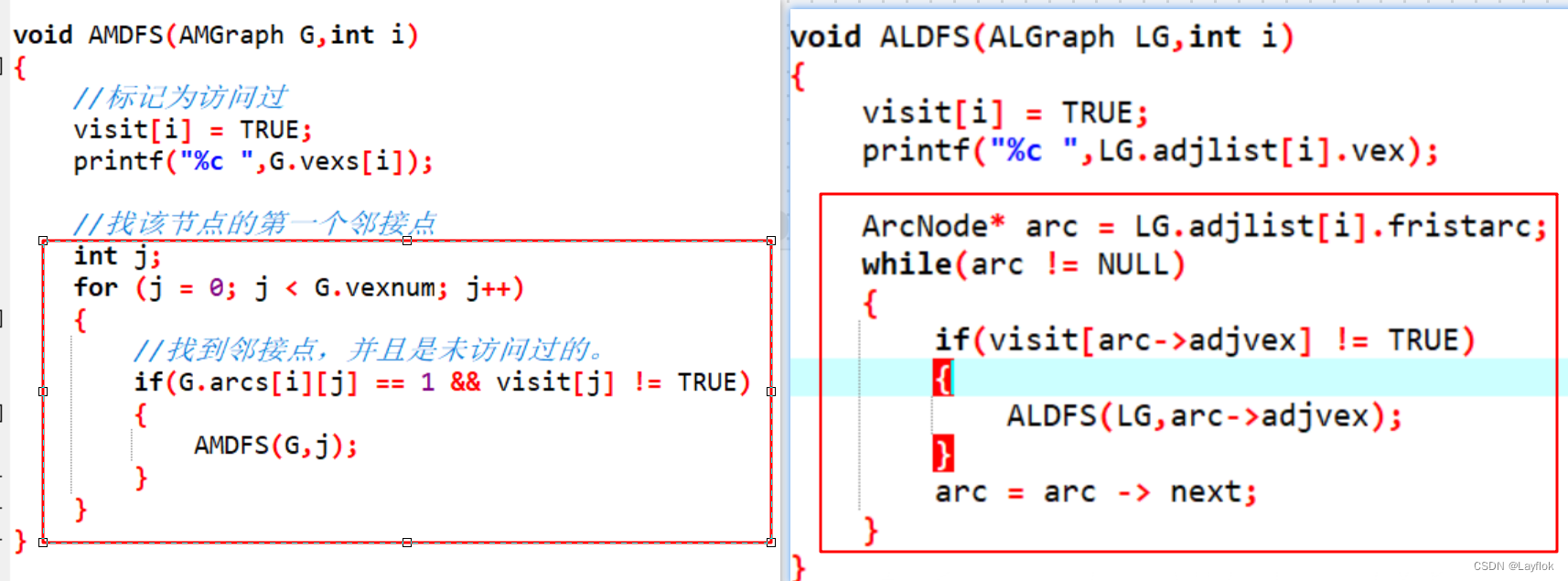
第三步:开始遍历当前顶点,如果发现该顶点有边,则进去第一条发现的边中去,访问它的邻接点。依次递归。
void AMDFS(AMGraph G,int i)
{
//标记为访问过
visit[i] = TRUE;
printf("%c ",G.vexs[i]);
//找该节点的第一个邻接点
int j;
for (j = 0; j < G.vexnum; j++)
{
//找到邻接点,并且是未访问过的。
if(G.arcs[i][j] == 1 && visit[j] != TRUE)
{
AMDFS(G,j);
}
}
}
上面是针对邻接矩阵的代码实现。而邻接表的只不过是把遍历二维矩阵,换成了遍历链表而已,主要是要掌握这个算法的思想。
三,广度优先(BFS)
广度优先算法就不是一条路走到黑了,这个广字可不是白叫的,就是从自身顶点出发,挨个访问于自己有关的顶点,直到全部访问结束。用这个算法需要队列,广度和深度的开始都一样,都是先给辅助数组初始化,然后传一个顶点进去,在此就不多解释。
//BFS ----- 广度优先遍历
void AMBFSTravers(AMGraph MG)
{
int i;
//初始化辅助数组都未访问
for (i = 0; i < MG.vexnum; i++)
{
visit[i] = FALSE;
}
//若是连通图,只进行一次
for(i = 0; i < MG.vexnum; i++)
{
//如果该节点未被访问过
if(visit[i] != TRUE)
{
AMBFS(MG,i);
}
}
}
主要看看其中如何遍历的。
第一步:先把传进来的顶点入队列。
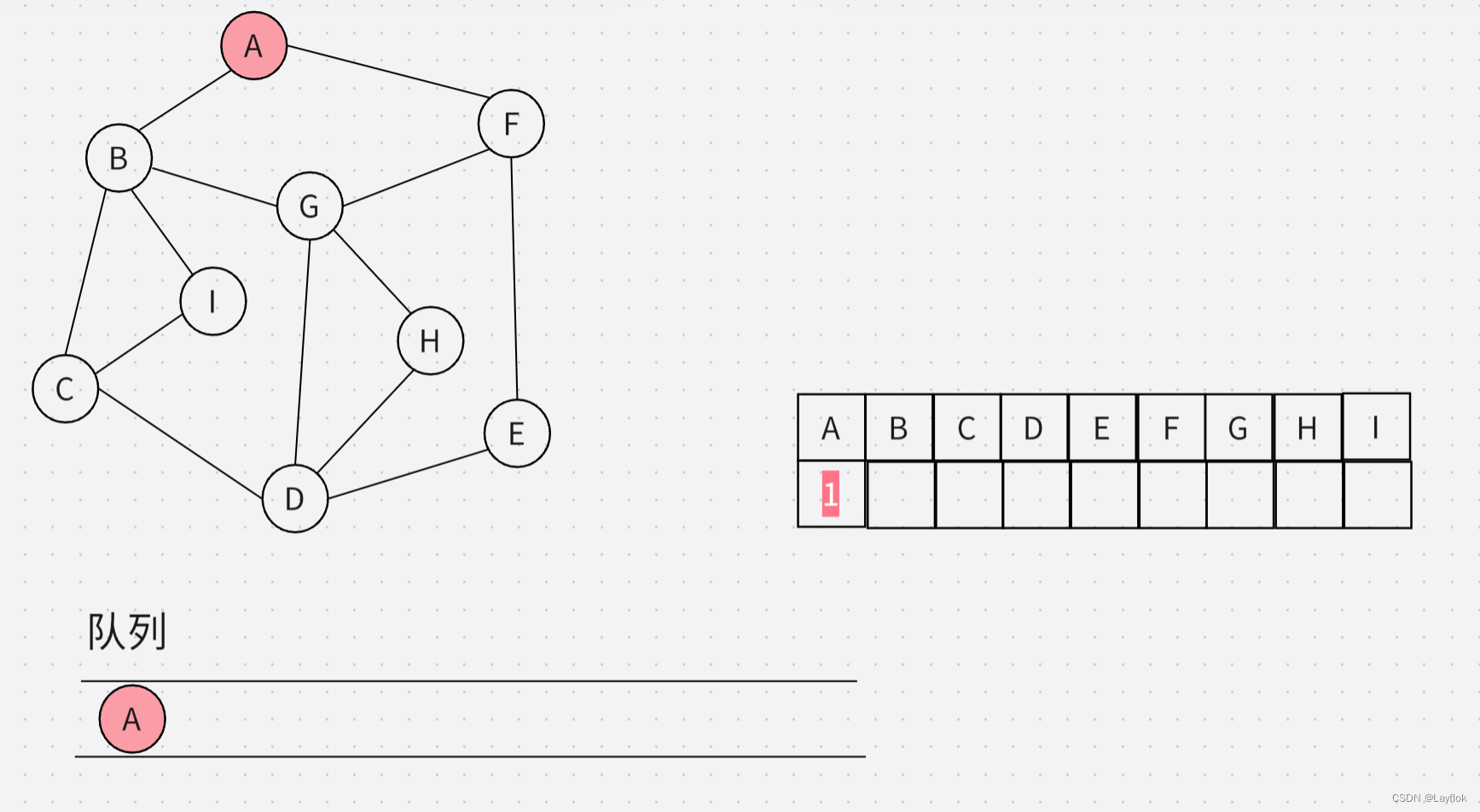
//创建一个队列
Queue Q;
QueueInit(&Q);
//入队列
QueuePush(&Q,i);
visit[i] = TRUE;
第二步:把当前队列的第一个元素有关的顶点(并且是未访问过的)依次入队列。
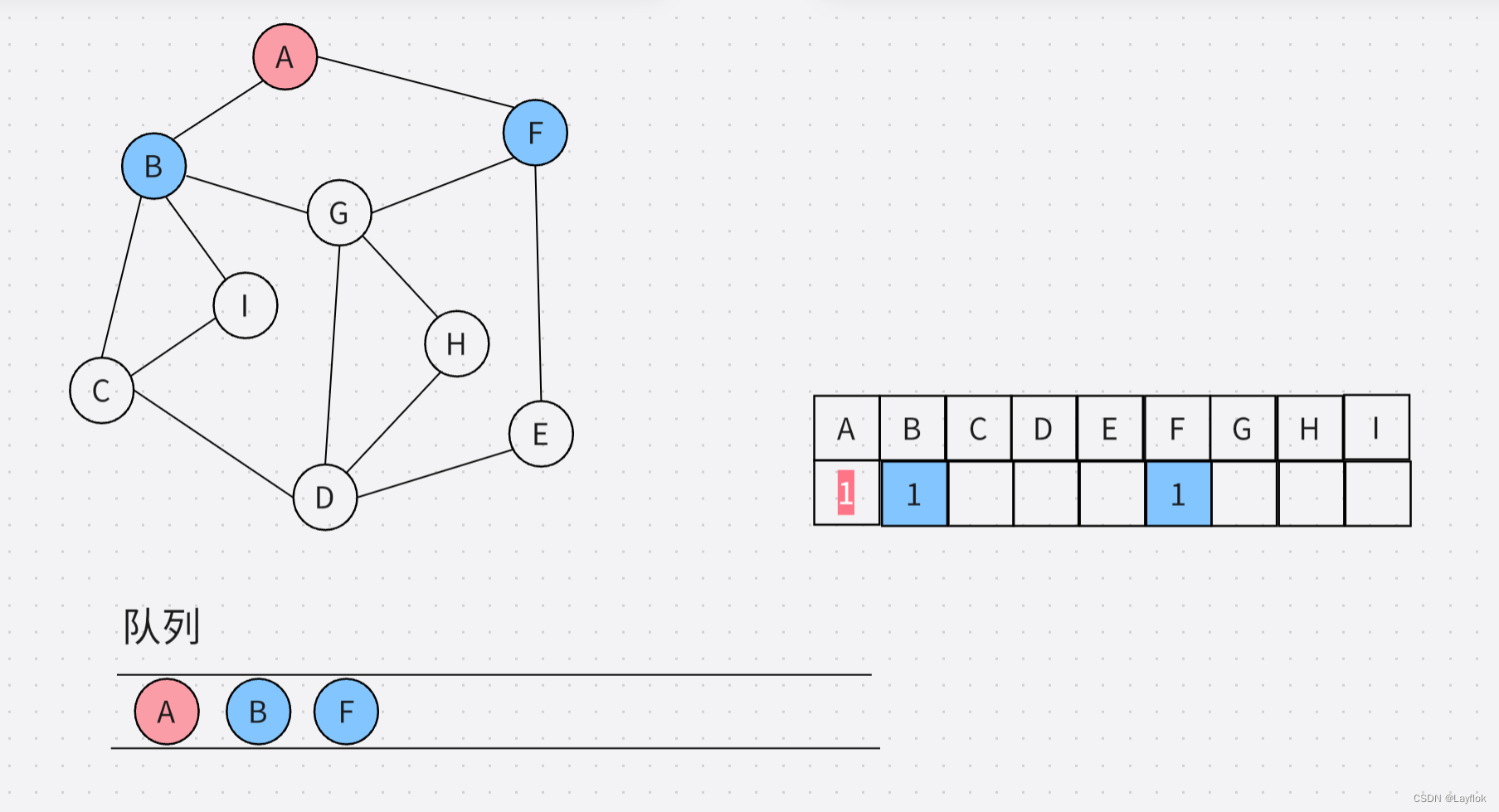
//队列不为空
while(!QueueEmpty(Q))
{
int j;
//将于当前顶点有关的边全部队列,并且是没有访问过的
for (j = 0; j < MG.vexnum; j++)
{
if(MG.arcs[i][j] == 1 && visit[j] != TRUE)
{
QueuePush(&Q,j);
visit[j] = TRUE;
}
}
//…………………………………………
}
第三步:出队列
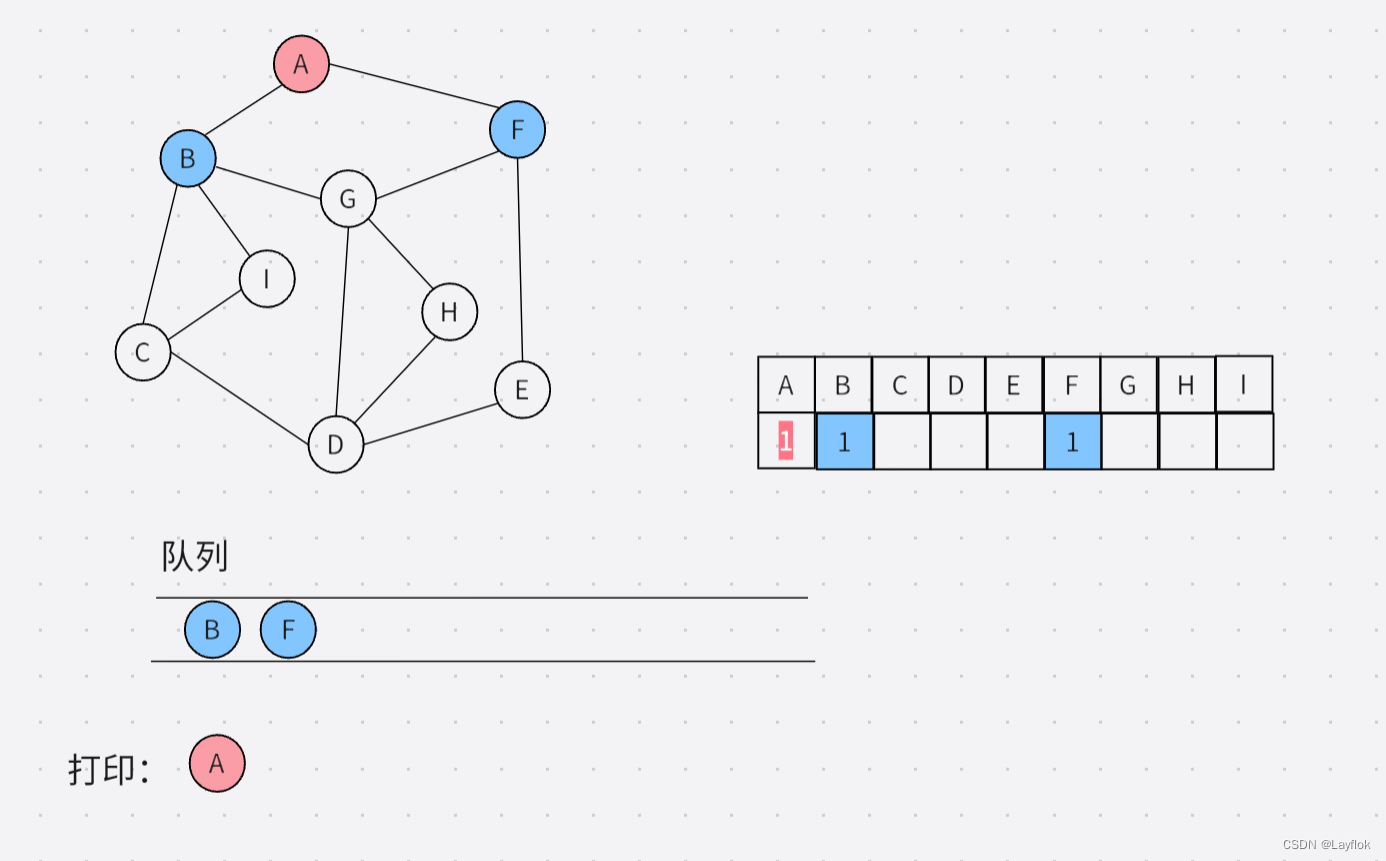
//出队列
int index;
QueuePop(&Q,&index);
printf("%c ",MG.vexs[index]);
后续的操作都是一样的就不重复了,而邻接表的算法也一样,还是把二维数组的遍历换成了链表的遍历而已。
四,总结
这两种算法都非常的神奇,所以写这种东西不是抄,而是理解这个思路,当理解了这个算法思路,逻辑之后,把他写出来并不是难事。
DFS和BFS的源码链接


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









