




 本文解析了LeetCode模拟面试中的三道经典题目,包括如何使用最少操作在记事本中打印特定数量的字符,寻找DNA序列中的重复子串,以及通过有限次猜测找出秘密单词。文章深入探讨了解题思路和算法优化。
本文解析了LeetCode模拟面试中的三道经典题目,包括如何使用最少操作在记事本中打印特定数量的字符,寻找DNA序列中的重复子串,以及通过有限次猜测找出秘密单词。文章深入探讨了解题思路和算法优化。
写在前面:
看到LeetCode上有个模拟面试,好奇点进来看看,这个比刷题好玩,计时让人有紧迫感,hard类的题目前来说比较难通过,中等的有希望,上图:
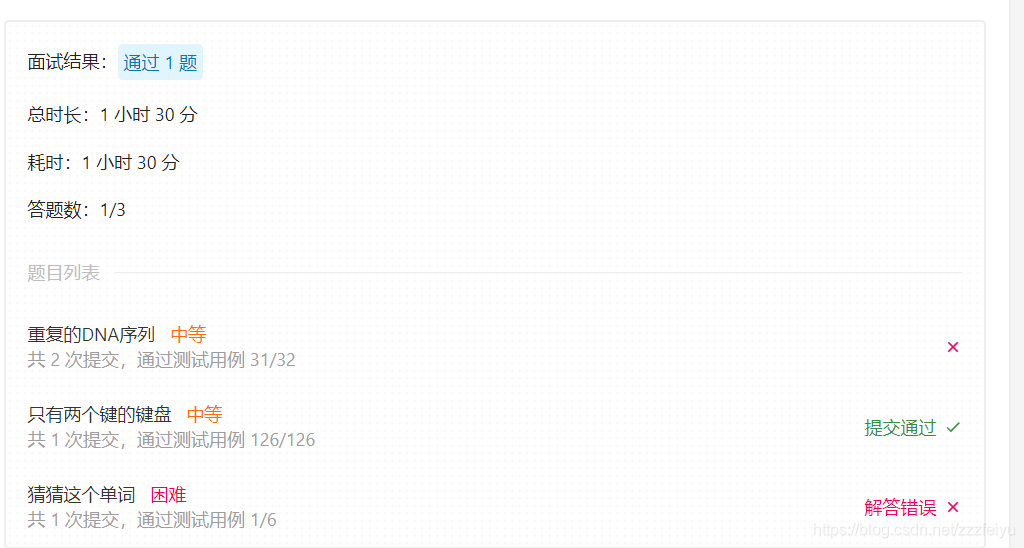
第一题:只有两个键的键盘
最初在一个记事本上只有一个字符 'A'。你每次可以对这个记事本进行两种操作:
Copy All(复制全部) : 你可以复制这个记事本中的所有字符(部分的复制是不允许的)。Paste(粘贴) : 你可以粘贴你上一次复制的字符。
给定一个数字 n 。你需要使用最少的操作次数,在记事本中打印出恰好 n 个 'A'。输出能够打印出 n 个 'A' 的最少操作次数。
示例 1:输入: 3 输出: 3
解释: 最初, 我们只有一个字符 'A'。 第 1 步, 我们使用 Copy All 操作。 第 2 步, 我们使用 Paste 操作来获得 'AA'。 第 3 步, 我们使用 Paste 操作来获得 'AAA'。 说明:n 的取值范围是 [1, 1000] 。
题解:
1、对数n进行copyall(k次) = n*(k+1)
2、判断n是否为素数,只要copyall(大于1的数)使用过,则n必非素数
3、若n为素数时,不能使用copy,故用n次
4、n为非素数时候,取其最大可约数subN且cnt = n/subN,如n=21,subN=7,cnt=3;若令a[n]代表n个‘A’,则先得出a[subN]即a[7],然后copyAll,在粘贴cnt-1次,对于a[7]重复处理即可,我这里用递归写,可以用while循环效率应该会高一点
class Solution {
public int minSteps(int n) {
/*
1、对数n进行copyall(k次) = n*(k+1)
2、判断n是否为素数,只要copyall(大于1的数)使用过,则n必非素数
3、若n为素数时,不能使用copy,故用n次
4、n为非素数时候,取其最大可约数subN且cnt = n/subN,如n=21,subN=7,cnt=3;若令a[n]代表n个‘A’,则先得出a[subN]即a[7],然后copyAll,在粘贴cnt-1次,对于a[7]重复处理即可,我这里用递归写,可以用while循环效率应该会高一点
*/
if(n == 1){
return 0;
}
int sub=0 ;
for(int i=n-1 ; i>=2 ; i--){
if(n%i == 0){
sub = i;
break;
}
}
if(sub == 0){
return n;
}else{
return minSteps(sub)+n/sub;
}
}
}
第二题:重复的DNA序列
所有 DNA 由一系列缩写为 A,C,G 和 T 的核苷酸组成,例如:“ACGAATTCCG”。在研究 DNA 时,识别 DNA 中的重复序列有时会对研究非常有帮助。
编写一个函数来查找 DNA 分子中所有出现超多一次的10个字母长的序列(子串)。
示例:
输入: s = "AAAAACCCCCAAAAACCCCCCAAAAAGGGTTT" 输出: ["AAAAACCCCC", "CCCCCAAAAA"]
题解:
这题有点迷,开始感觉真简单,直接indexOf,但是会超时,现在想想应该是用DP,留坑
class Solution {
public List<String> findRepeatedDnaSequences(String s) {
/*
挨个取出子串,然后indexOf()?
*/
List<String> ret = new ArrayList<>();
if(s.length() <= 10){
return ret;
}
for(int i=0 ; i<s.length()-9 ; i++){
String sub = s.substring(i,i+10);
int tmp = s.indexOf(sub,i+1);
if(tmp != -1 && ret.indexOf(sub)==-1){
ret.add(sub);
}
}
return ret;
}
第三题:猜猜这个单词
这个问题是 LeetCode 平台新增的交互式问题 。
我们给出了一个由一些独特的单词组成的单词列表,每个单词都是 6 个字母长,并且这个列表中的一个单词将被选作秘密。
你可以调用 master.guess(word) 来猜单词。你所猜的单词应当是存在于原列表并且由 6 个小写字母组成的类型字符串。
此函数将会返回一个整型数字,表示你的猜测与秘密单词的准确匹配(值和位置同时匹配)的数目。此外,如果你的猜测不在给定的单词列表中,它将返回 -1。
对于每个测试用例,你有 10 次机会来猜出这个单词。当所有调用都结束时,如果您对 master.guess 的调用不超过 10 次,并且至少有一次猜到秘密,那么您将通过该测试用例。
除了下面示例给出的测试用例外,还会有 5 个额外的测试用例,每个单词列表中将会有 100 个单词。这些测试用例中的每个单词的字母都是从 'a' 到 'z' 中随机选取的,并且保证给定单词列表中的每个单词都是唯一的。
示例 1: 输入: secret = "acckzz", wordlist = ["acckzz","ccbazz","eiowzz","abcczz"] 解释:master.guess("aaaaaa")返回 -1, 因为"aaaaaa"不在 wordlist 中.master.guess("acckzz") 返回6, 因为"acckzz"就是秘密,6个字母完全匹配。master.guess("ccbazz")返回 3, 因为"ccbazz"有 3 个匹配项。master.guess("eiowzz")返回 2, 因为"eiowzz"有 2 个匹配项。master.guess("abcczz")返回 4, 因为"abcczz"有 4 个匹配项。 我们调用了 5 次master.guess,其中一次猜到了秘密,所以我们通过了这个测试用例。
题解:
这题真的6,感觉有点眉目,但是做着就是一头雾水,时间太短想不出来,我猜关键是怎么整合每次搜索的结果到一个结果集,在结果集中判断需要查询哪些string,每次更逼近答案或剔除多一点的错误答案。我这里是想剔除多余答案的,但是逻辑貌似有问题
2019/08/14 05:15
/**
* // This is the Master's API interface.
* // You should not implement it, or speculate about its implementation
* interface Master {
* public int guess(String word) {}
* }
*/
class Solution {
public void findSecretWord(String[] wordlist, Master master) {
Arrays.sort(wordlist);
int ret = 0;
String last = null;
for(int i=0 ; i<wordlist.length ; i++){
boolean flag = false;
String cur = wordlist[i];
//命中ret个字符,重合度高于ret的去除
//逼近随缘...
int cnt = -1;
for(int j=0 ; i!=0 && j<6 ; j++){
if(cur.indexOf(last.charAt(j)) != -1){
cnt++;
}
if(cnt > ret){
flag = true;
}
}
if(flag){
continue;
}
last = cur;
ret = master.guess(last);
}
}
}

















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









