



前言
智商这东西,上去了就下不来了。
Question1 MLP,FCN,DNN,BP究竟有什么差别?
在学习神经网络的前期,时常搞不懂这些名词的区别。在此之前需要说明,笔者个人认为,机器学习和深度学习是完全不同的两个学派。机器学习基于严谨的数学推理,而深度学习发展至今仍然存在许多不可解释的现象。
多层感知机(Multilayer perceptron,MLP)的结构基于单层感知机,单层感知机便是只有输入和输出层。
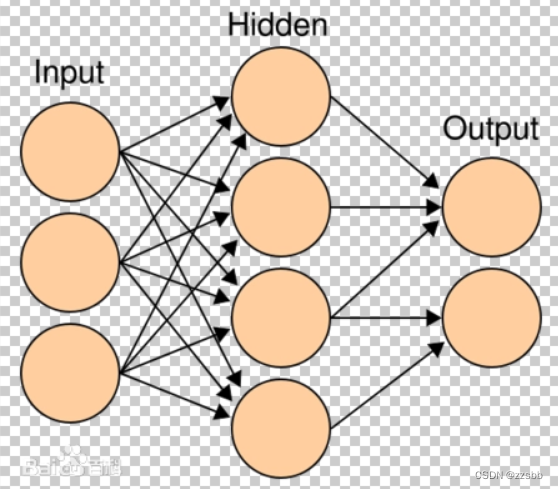
图1(此图来源于百度百科)
如图1所示为感知机的基本结构,由输入层,中间层(隐藏层),输出层组成。
从神经网络的角度来看,同于图1结构,每个神经元之间互补联系,并于下一层的每个神经元都存在联系,因此可称之为全连接。满足这个结构的神经网络称为全连接神经网络(Fully connected neural network,FCNN)。这种网络的传播过程是从前一层到后一层,整体从左至右,从数据的传播方向上看,称之为前馈神经网络(Feedforward neural network,FNN)。隐藏层的层数是可以随着任务需求来调节,层数越多,模型越复杂,计算量越大。深度神经网络(Deep neural network,DNN)正是一种对大模型的描述,与之对应的便是浅层神经网络(Shallow neural network,SNN)。不过,对于如何才算是一个深度神经网络并没有明确的定义,是一个相对的说法。
至于说BP,这是一种训练算法。在全链接网络的训练中,最终目标就是确定每一层的权重参数,使得预测结果与实际结果(Ground truth,GT)之间的损失最小。从数据输入到输出层的数据传播过程称之为前向传播(Forward propagation,FP),而对损失函数使用梯度下降算法(Gradient descent),通过迭代更新权重的数据传播过程称之为反向传播(Back propagation,BP)。使用反向传播算法对网络进行训练的神经网络都可以称之为BP神经网络。
在一些论文或者代码中,常见的描述。
Linear:线性层,单层神经网络,即无隐层。
Dense:密集层,既可以指单层linear, 也可以指多层堆叠 (可无隐层, 也可有); 但大多数情况下,指代多层堆叠。
MLP:多层感知机,多层linear的堆叠,有隐层。
FC:全连接层,单层、多层均可。
Question2 如何理解一个卷积神经网络?
受限于全连接网络的计算复杂,参数过多,数据容易过拟合等问题,卷积神经网络(Convolutional Neural Networks,CNN)闪亮登场。它是一种具有局部连接(Locally connected)和权值共享(weight sharing)的深层前馈神经网络。
1.局部连接(Locally connected)
局部连接又叫稀疏连接,就是卷积层的节点不与前一层的全部节点进行连接,仅与部分节点进行连接。这样做的目的也非常好理解,减少参数量,加快学习速率,减少过拟合。如图2,是局部连接的示意图,读者可以自行计算与全链接相比,减少了多少计算量。
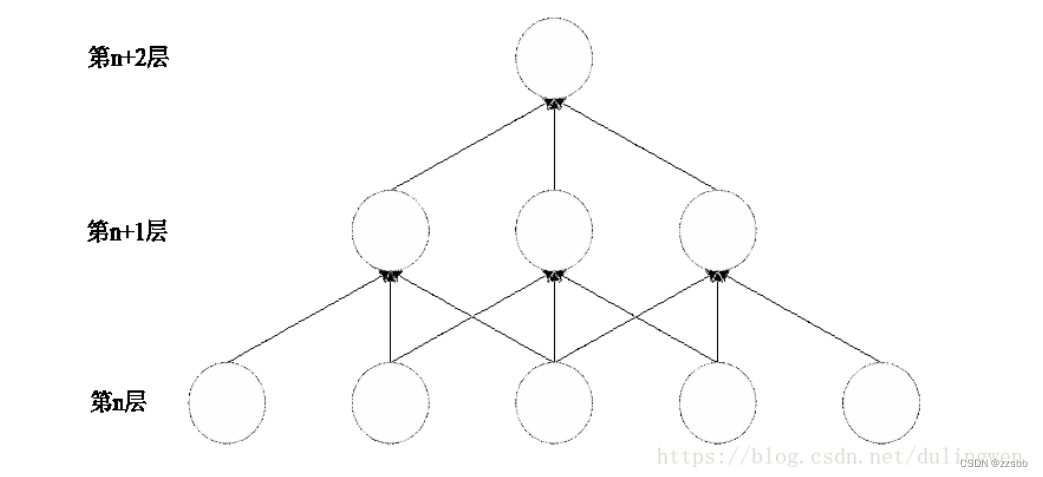
图2 局部连接(此图来源于优快云)
2.权值共享(weight sharing)
权值共享则更好理解,卷积过程中最终目的便是要确定卷积核中的权重参数,不同的卷积核需要计算不同的权重参数。权重共享则是使卷积拥有共同的权重参数,这一举动可以使得参数数量进一步减少。
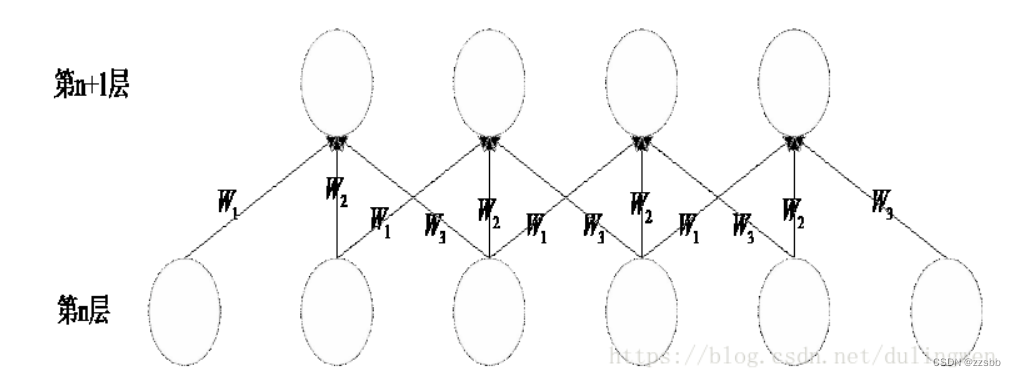
图3权值共享(此图来源于优快云)
这张动图可以方便更好的理解权值共享的过程。对于一张H*W的图片,相当于用同一组Filter去过滤F*F的特征图。

为什么权值共享是有效可行的呢?笔者进行了一点思考,基于两点假设,一是某些特征具有相似的空间位置和统计特性,他们在局部上是有关联的,因此可以采用局部连接;二是这些特征峰的表述是跟位置无关的,因此可以采用权值共享,此外,使用权重共享还可以助于模型对平移、旋转和尺度变换等空间变化具有一定的不变性,从而提高模型的泛化能力。
3.感受野(Field-of-view)
感受野指的是输出的特征图上的一个像素点映射回原图所对应的区域的大小。
让我们回顾一下普通卷积的输出特征图公式:
![]()
其中,[]是取整符号,输入特征图尺寸为a*a,卷积大小为b*b,步幅stride=c,填充padding=d。
如图4,蓝色map视为F1,大小为5*5,经过一个3*3大小的卷积,输出橙色map,命名为F2。根据公式(1),F2大小为3*3,一个F2的像素点对应F1的感受野是3*3。再次经过一个3*3大小的卷积,输出荧光蓝map,命名为F3。根据公式(1),F3大小为1*1,一个F3的像素点对应F1的感受野是5*5。
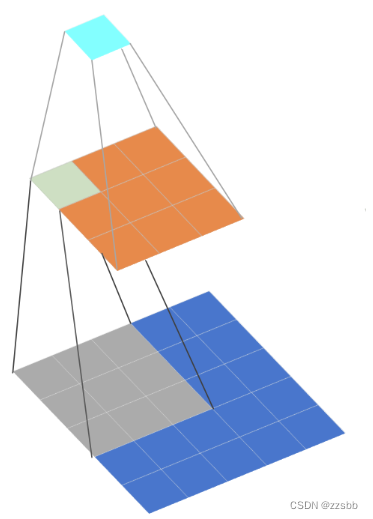
图4 感受野
计算某一层的感受野的公式为:
![]()
其中,Fi表示第i层的感受野,Fi-1表示第i-1层的感受野,注意:原图的感受野为1。
从更为抽象的角度来看,感受野代表了什么呢?笔者认为,感受野可以理解为一只在特征图上的眼,从这只眼中可以看到不同的原图上的碎片,能看到的碎片越大,感受野越大,看到的碎片越小,感受野越小。那么很好理解,在卷积神经网络中,在越深的层提取的到的特征图,感受野更大,代表的意义更加抽象,得到的应该是一些高级语义信息;反之,在浅层的感受野越小,能看见原图一些更为细节的东西,例如边缘,纹理等信息。
4.分辨率(Resolution)
说完了感受野,让我们来谈谈分辨率。分辨率可以理解为一张图片的尺寸大小,即长宽。在神经网络模型中,随着下采样次数的增加,特征图(feature map)的大小下降,而通道数变多。这意味着,网络学到的信息从低级信息转变为高级语义信息。这个地方稍微提一下卷积的参数的选择,即选择卷积核的个数和大小。卷积核大小若选择过大,容易抽取不到高级的语义信息,如果选择过小,那么会造成信息丢失。卷积核的个数越多,得到的数据维度越高,蕴含的信息就更丰富,但是过高的维度也会造成计算的复杂程度大大增加。
5.网络模型的深度(Depth)
此处的深度指的是,整个网络模型的深度,可以理解为层数。对于网络的深度的理解主要有以下三点。
(a)更深的模型,可以拟合更复杂的特征。
(b)每一层要做的事情会更简单,比如第一层学习形状,第二层学习颜色,第三层学习更加复杂的特征。
(c)但是加深带来的梯度爆炸,网络退化等问题依然不可避免。还有一定的饱和问题。还有带来浅层学习能力下降的问题。
6.网络模型的宽度(Width)
网络宽度可以理解为抽取的特征图的维度,也就是与卷积核的个数决定的。
通道里的信息,可以理解为学习到目标不同模式下的特征。比如不同方向,不同频率下,有的是灰色的,有的是彩色的特征。提高通道的利用率,通道信息之间的相互补偿是利用好宽度信息的关键。
关于网络的宽度和深度的平衡和抉择,有论文做过实验,假设要达到相同的学习目的,将一个3层的网络减少为2层的网络,那么通道数会大大增加,指数级增加。但是,当深度减少时,宽度并不是指数增加,而是多项式的增长。也许,从某个方面反映了网络的宽度不如深度重要。如果想要深入了解请参考这位博主写的文章,非常明了。(【AI不惑境】网络的宽度如何影响深度学习模型的性能?-优快云博客)
7.池化(pooling)
池化相对于卷积更好理解,主要有两种:
(a)全局池化(Max-pooling ):在感受野(例如:卷积核3*3的视野)下取最大值。
(b)平均池化(Average-pooling):取平均值。
池化的作用:
- 增大感受野。
- 可以快速下采样,但是pooling的下采样和卷积的下采样是不一样的。
- 平移不变性。
我们希望目标的些许位置的移动,能得到相同的结果。因为pooling不断地抽象了区域的特征而不关心位置,所以pooling一定程度上增加了平移不变性。(理论上虽然是这样,但是 Kaudererabrams E. Quantifying Translation-Invariance in Convolutional Neural Networks.[J]. arXiv: Computer Vision and Pattern Recognition, 2018.这篇文章证明了池化对平移不变性作用不大,做好数据增强才是关键)
4.降低优化难度和参数。
我们可以用步长大于1的卷积来替代池化,但是池化每个特征通道单独做降采样,与基于卷积的降采样相比,不需要参数,更容易优化。全局池化更是可以大大降低模型的参数量和优化工作量。
8.下采样(Down-Sample)
下采样就是抽取信息的过程,图像的分辨率依次缩小。
下采样的作用:
- 减少计算量,防止过拟合。
- 增大感受野,使得后面的卷积核能够学到更加全局的信息。
下采样的设计通常有两种:
- 采用步长(stride)为2的池化层,如Max-pooling或Average-pooling,目前通常使用Max-pooling,因为它计算简单且最大响应能更好保留纹理特征。
- 采用步长(stride)为2的卷积层,下采样的过程是一个信息损失的过程,而池化层是不可学习的,用stride为2的可学习卷积层来代替pooling可以得到更好的效果,当然同时也增加了一定的计算量。
9.上采样(Up-Sample)
上采样是将下采样得到的小尺寸的特征图恢复到原图大小,在语义分割领域非常常见。
上采样通常的设计有以下三种:
- 插值,一般使用的是双线性插值,因为效果最好,虽然计算上比其他插值方式复杂,但是相对于卷积计算可以说不值一提。
- 转置卷积又或是说反卷积,通过对输入feature map间隔填充0,再进行标准的卷积计算,可以使得输出feature map的尺寸比输入更大。
- Max Unpooling,在对称的max pooling位置记录最大值的索引位置,然后在unpooling阶段时将对应的值放置到原先最大值位置,其余位置补0。
Reference:深度学习Linear, Dense, MLP, FC区别是啥?_在深度学习中dense是什么含义_Reza.的博客-优快云博客
【综述】一文读懂卷积神经网络(CNN) - 知乎 (zhihu.com)
欢迎同步关注公众号:ZZSnotes


















 3万+
3万+




 到【灌水乐园】发言
到【灌水乐园】发言







