




目录
没有列头
首先导入我们需要处理的数据
import pandas as pd
df=pd.read_csv('../data/patient_rate.csv')
df第一个问题就是我们没有列头,所以这里读取数据的时候,需要手动添加列的索引
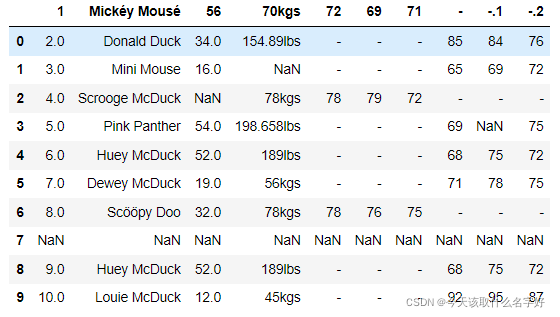
#为了释放第一行的数据,我们需要自己传入索引
column_names=['id','name','age','weight','m0006','m0612','m1218','f0006','f0612','f1218']
#重新读取数据文件
df = pd.read_csv('../data/patient_heart_rate.csv', names = column_names)
df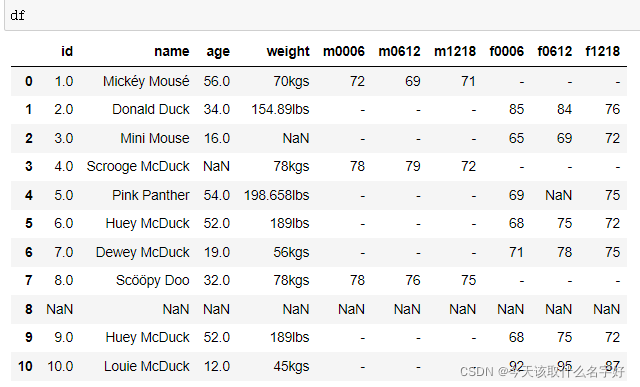
一个列有多个参数
name这一列数据2个参数,我们可以给他拆开作为2个参数
df['name'].str.split()我们可以通过split方法切分开,但是这样传出来是一个列表
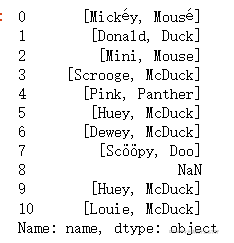
但是split函数中还有个参数可以把这个返回的列表直接拆成多列返回
split_name=df['name'].str.split(expand=True)
split_name 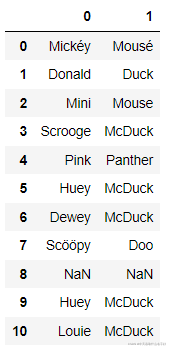
我们在原来的dataframe上直接创建两个新的列接受上面那2个列的数据
df[['first_name','last_name']]=split_name
df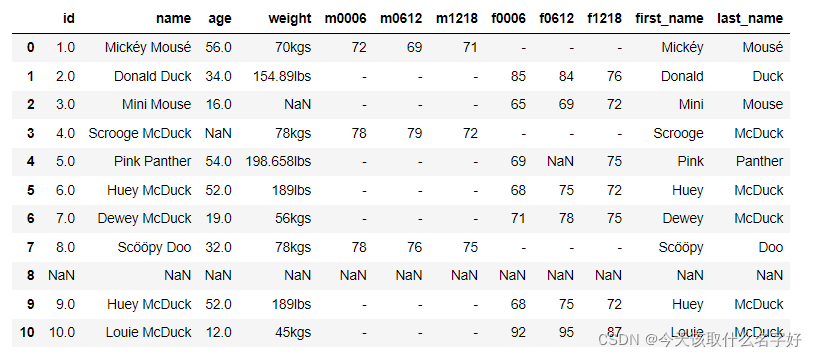
现在来看, 切分出来的数据和name列的数据重复了,我们可以删掉name列的数据
删除列的数据,必须要指定:axis(轴)为1,说明我们要处理的是列的数据
因为默认是设置axis=0,也就是说他里面处理的是行的索引
df=df.drop('name',axis=1)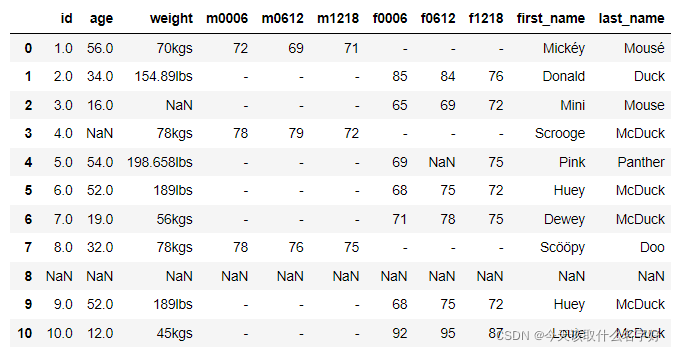
处理一列多个参数问题解决了
单位不统一
可以看到我这里weight数据有的是NaN,有的是kgs,有的是lbs,这里就设计2个操作,一个是单位转换,还有个是空值填充
kg是千克(复数就加了s),lb是磅
百度一下:1 千克=2.20462262185 磅,我为了方便计算就取2.2了
首先,找出单位是lbs的数据,这返回的是一个布尔索引,我们可以通过这个带回dataframe中,看出哪些行是单位不一样的
#首先我们通过str下面的contains方法将单位是lbs(磅)的找出来
#这里必须将空值填充了,不然带回df中会提示报错
df['weight'].str.contains('lbs')
但是这个返回的索引中是有NaN的,带回去肯定是报错的,我们需要填充个False,不让他被检测到,后续在处理
#筛选出weight列数据单位是lbs的数据
lbs_ds=df[df['weight'].str.contains('lbs').fillna(False)]
lbs_ds成功检测到了这些单位是lbs的数据,我们找到这些数据的目的是获取他们的行索引,为我们替换这些数据做准备
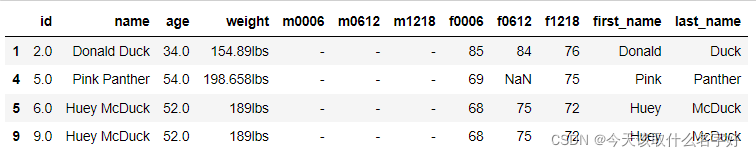
#行的索引为后面的替换工作服务,通过clo方法我们可以通过行索引得到一行数据,因为可以通过索引来替换一行的数据
lbs_ds.index![]()
接下来这是替换数据的步骤了,写定义函数将磅的数据转换成单位是kgs
#利用map或者是apply方法,将里面的数据替换了,单位是kgs,数值也是通过转换比例得到的
lbs_to_kgs=lbs_ds['weight'].map(lambda x:"%.2fkgs" %(float(x[:-3])/2.2))
lbs_to_kgs
我们上面那么多准备工作就是为了现在的替换
#向loc中传行的索引,以及列索引‘weight’,我们就给对应坐标上的数据替换了
df.loc[lbs_to_kgs.index,'weight']=lbs_to_kgs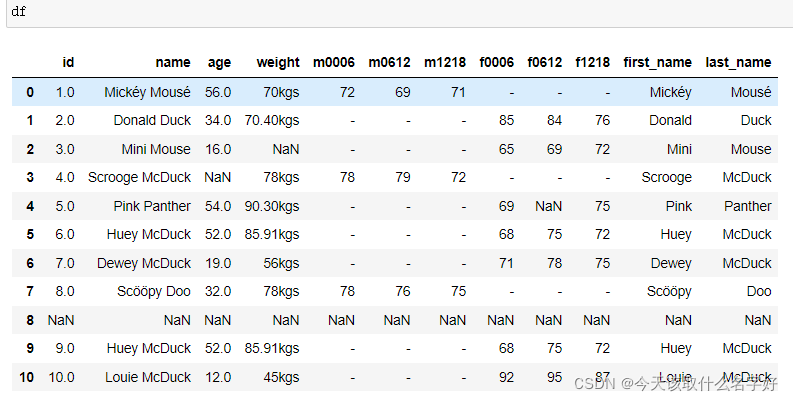
loc方法,通常是传入行索引,我们就能查看这行的数据
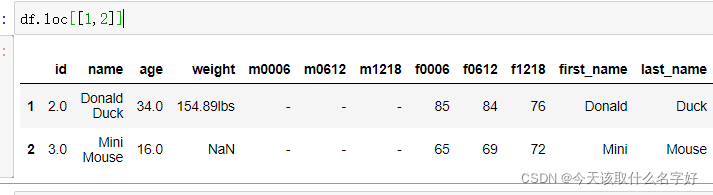
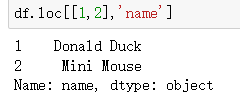
逗号分割后,再传入列索引,这样就可以精确锁定一个坐标了
缺失值处理
一般处理确实值从这几个角度出发
删:删除数据缺失的记录
赝品:使用合法的初始值替换,数值类型可以使用 0,字符串可以使用空字符串“”
均值:使用当前列的均值
高频:使用当前列出现频率最高的数据
先说删除:
从上面处理的结果出发
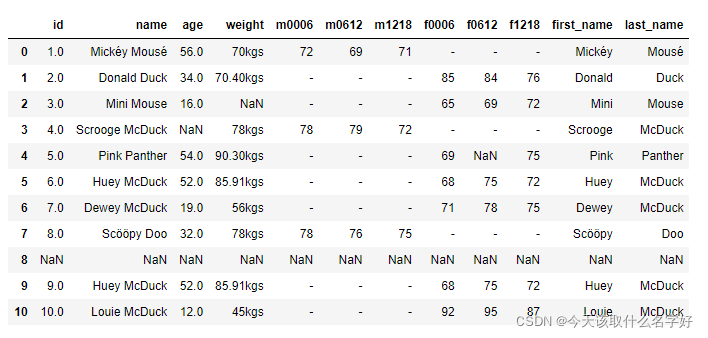
首先第一眼就可以看见行索引是8的都是空值,直接删除掉
#删除掉一行中都是空的数据
df.dropna(how='all',inplace=True)关于dropna方法还有2个常见的用法
data.dropna() 什么参数都不传,一行数据中只要有空的就删除这行
data.dropna(thresh=5) 增加制,设置好在一行中有多少非空值的数据是可以保留下来的(在下面的代码中,我写的是指定行数据中至少要有 5 个非空值,否则就被删)
检测一列数据中空值的方法:
df['weight'].isnull().value_counts()如果一列中空的数据太多,也可以考虑这列数据不要了,全部填充反而没有意义

赝品:
通常是空字符串去替换
常用方法:fillna('')
#把dataframe中所有空值都换成空字符串,通常来说不合适
df=df.fillna('')#将一列数据中的空值替换
df['weight']=df['weight'].fillna('')#将一行的数据进行空值填充
df.loc[[4]]=df.loc[[4]].fillna("")
均值:
不难理解就是用一列数据的平均值作为空值的填充对象
#求出weight列的平均数并替换空值
weight_mean = df['weight'].fillna('0kgs').apply(lambda x:float(x[:-3])).mean()
df['weight'].fillna("%.2fkgs" % weight_mean,inplace=True)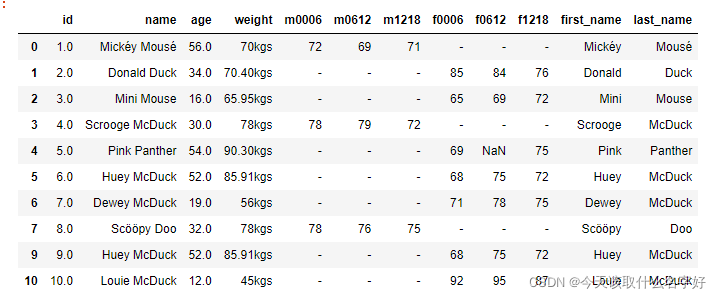
规范化数据
英文单词时大小写的不统一
输入了额外的空格
输入了ascii码表中不存在的符号
#将英文单词改成大写
df['name'].str.upper()
#去除两边的空格
df['name'].str.strip()ascii码表中不存在的符号:
就像这种单词上面还带拼音声调的肯定不是acsii码表中有的,我们最好删掉或者替换
这里演示下删除
![]()
可以利用正则表达式匹配这个acsii码表的内容范围
#在数据中有的是超出了ascii码的范围,所以我们需要把这部分数据给去掉
df['name'].replace({r"[^\x00-\x7f]":""},regex=True,inplace=True)
去除行内容完全重复的数据
根据我们传入的字段决定是不是对数据进行去重
#drop_duplicates,相当于dictinct,根据我们后面传入的参数的笛卡尔积去重复的行数据
df.drop_duplicates(['first_name','last_name','age','weight'],inplace=True)
















 1371
1371

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









