






从模型角度进行总结的话,我觉得有些过于庞杂,所以我决定从具体应用领域的角度简单总结一下。
目前深度学习模型应用比较广泛的领域主要包括:计算机视觉、自然语言处理、音频处理、时间序列分析、购物和娱乐、自动化与机器人技术、金融技术等。
计算机视觉可谓是深度学习最早获得显著成功和广泛应用的领域之一,2012年AlexNet在ImageNet挑战赛中获得的突破性成功,推动了深度学习在该领域中的发展。
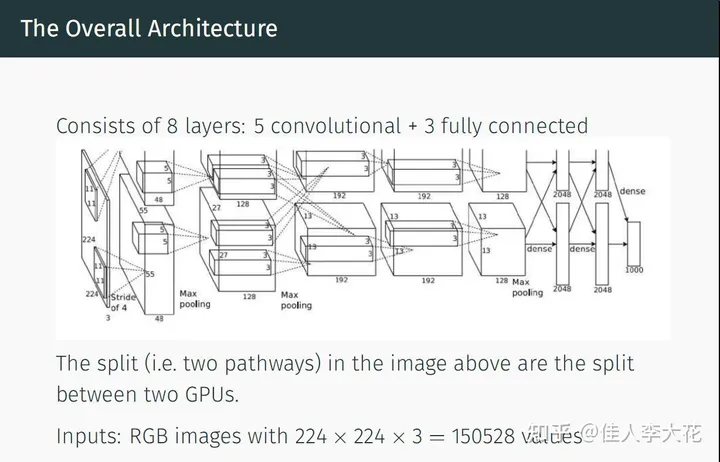
其实AlexNet的结构现在看起来并不算复杂,但是在当年的挑战赛中,却是取得了错误率比第二名低10.8个百分点的优异成绩,更是得到了“模型的深度对于提高性能至关重要”的关键结论,指导了未来几年的深度模型“越来越深”的发展趋势。
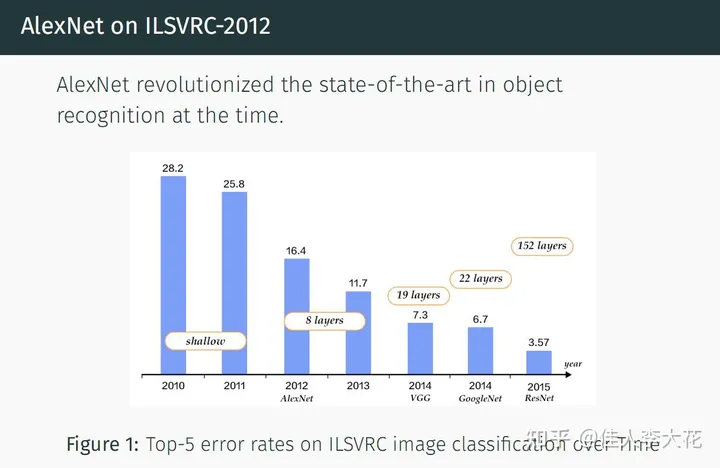
随着硬件的发展,深度学习模型的能力不断提升,在计算机视觉的各个领域均得到了广泛的应用。
图像分类——
应用目标:用于识别图像中的对象类别,给整个图像打上标签。比如用于自动分类和标记社交媒体平台上的图片内容,过滤违规内容、识别版权问题等。
常用模型:卷积神经网络(CNN)及相关变形是最常用的模型,例如AlexNet、VGGNet、ResNet等。
目标检测——
应用目标:识别图像中的特定对象,同时确定它们的位置和大小。例如现在用来保护我们安全的天眼系统,有了深度学习模型的加持后,可以更加准确的进行目标跟踪、异常行为检测等,减少大海捞针式的工作量。
常用模型:区域卷积神经网络(R-CNN)、快速R-CNN(Fast R-CNN)、更快R-CNN(Faster R-CNN)和单次多框检测(SSD)等。
图像分割——
应用目标:将数字图像划分为多个区域或对象,以便更好的理解和分析图像内容。例如在医学诊断中,图像分割用于从医学扫描图像(如CT、MRI)中提取特定的解剖结构、病灶或疾病迹象,协助医生进行更精确的诊断和治疗规划;在遥感领域,可以用于从卫星或航拍图像中提取地表特征,如土地利用、植被覆盖、水体检测等,降低监测成本;在图像编辑和图像合成中,用于提取图像的特定内容,以便于进行背景替换、特效制作等(比如可以用抠图骗小孩,让小孩以为自己去乐园玩了)。
常用模型:全卷积网络(FCN)和基于区域的卷积神经网络(如Mask R-CNN)。

人脸识别——
应用目标:这个算是我们普通人目前接触最多的技术之一,比如手机的人脸解锁;智能防盗门的人脸开启;各种app的人脸支付;学校和企事业单位的刷脸打卡等等。
常用模型:使用深度学习的人脸识别技术包括深度残差网络 (ResNet),Siamese网络,Inception网络以及基于卷积神经网络的FaceNet等。
视觉跟踪——
应用目标:通过计算机视觉技术对视频中的对象进行实时定位和跟踪,应用于视频监控、运动分析、交互式媒体等。比如现在我们经常在宾馆中看到的送餐机器人,视觉跟踪技术可以帮助它在复杂环境中导航,识别和避开障碍物;利用视觉跟踪技术跟踪用户的眼动或手势,可以增强现实和虚拟现实系统中的用户交互体验。
常用模型:用卷积神经网络提取视频帧中的特征;用长短期记忆网络处理视频序列中的时间信息,辅助理解对象在视频中的动态变化;用Siamese网络比较目标对象与视频帧中的候选对象,处理很多实时任务。
虽然针对不同处理目标可能存在相对常用的深度学习模型,但是其实更多的情况下,模型之间并不存在应用壁垒。比如卷积神经网络擅长图像特征提取,在图像和视频领域有着无可取代的重要作用。更多的情况下,研究人员针对不同的任务目标,将CNN进行改进和调整,以期使其更加适用于特定任务。
学习后,再遇到有关深度学习的类似问题时,可以第一时间求助大模型,或许可以有效节省学习时间,提高工作效率。比如可以直接询问大模型,如果想给一款APP增加人脸识别登录的功能,应该选择哪种算法?甚至还可以直接要求它给出一些示例代码:
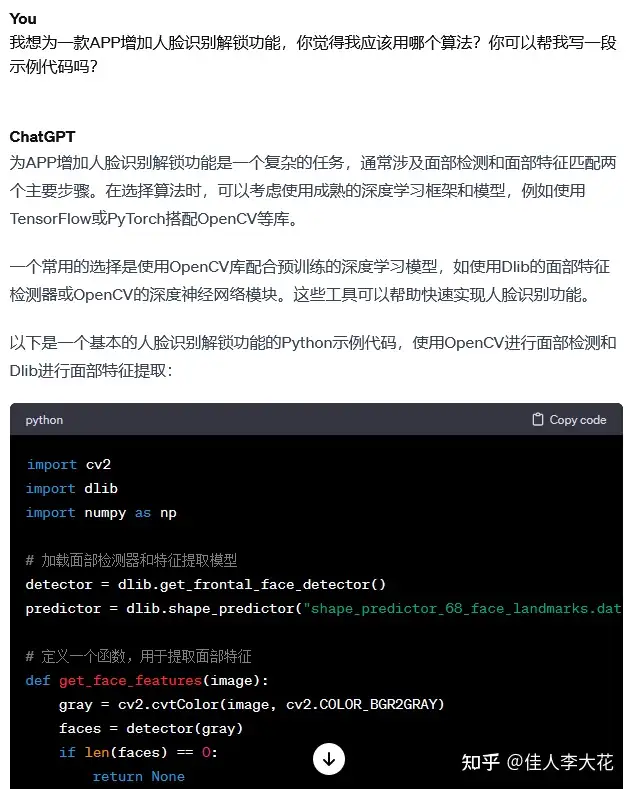
继续说回不同领域常用的深度学习模型。计算机视觉领域主要依靠以卷积神经网络为代表的一系列擅长图像特征提取的算法,而目前最流行的自然语言处理领域,由于处理对象的差异,常用算法也是截然不同的。
循环神经网络 (RNN):特别适合处理序列数据,比如文本。RNN擅长处理不同长度的输入序列,捕捉序列中的动态信息。
长短期记忆网络 (LSTM):一种特殊类型的RNN,能够更有效的学习长距离依赖,也就是“记忆变长”,常用于文本生成、机器翻译、语音识别等任务。
门控循环单元 (GRU):与LSTM类似,在RNN的基础上改进得到,用于解决RNN中的梯度消失问题,功能与LSTM相似。
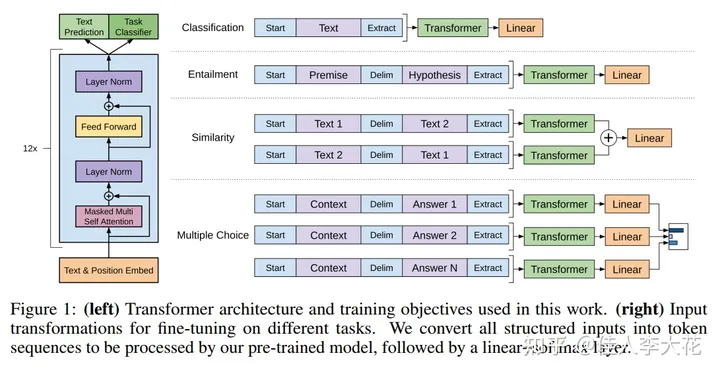
Transformer模型:Transformer完全基于注意力机制,摒弃了传统的RNN结构。它在效率和性能上都优于RNN和LSTM,特别适用于处理大规模文本数据,是目前各种大模型的基本依托结构。比如GPT的初代原理说明中,就曾明确过模型架构。
对于购物平台,为了能够更加“精确”的从我们的钱包里掏出钱来,通常会使用卷积神经网络用于商品图像的分类和识别,帮助自动标记产品、进行视觉搜索或推荐相似商品;使用循环神经网络处理用户的购物历史和搜索历史,用于个性化推荐和预测未来购买行为;使用自编码器用于用户喜好的特征学习和降维,以提高推荐系统的效率。
游戏领域流行使用强化学习模型,用于开发游戏AI,如开发自动玩家和游戏测试机器人,以及进行动态游戏环境的调整;卷积神经网络用于游戏中的图像识别和处理,例如在实时策略游戏中分析地图和单位;生成对抗网络,用于生成逼真的游戏图像和环境,增强游戏的视觉效果。
目前另一个已经快被大家玩坏了的领域,音频领域,其实用到的深度学习模型同样不外乎这几种:卷积神经网络用于音频分类、音乐风格识别、环境声音识别等;循环神经网络用于处理音频数据中的时间序列信息,进行语音识别、音乐生成和音频事件检测;生成对抗网络用于音频和音乐生成,通过学习真实音频样本的分布来生成新的音频内容;变分自编码器,在音乐创作和音频合成中用于生成新的音频样本,可以控制生成音频的不同属性;Transformer模型用于改进语音识别系统等。
前两天有个小朋友询问我非科班出身,应该怎么学习大模型和各种算法?我的回答是,尽量学习各种一手资料,比如阅读顶会的原版会议论文以及经典著作,如果读不懂怎么办?求助大模型啊!大模型不仅可以实现简单的文献翻译功能,而且已经可以结合提问者的自身水平,进行意译,有效帮助提问者进行知识理解。
学好用好大模型,你会发现它是你身边最有效的学习助手!
免费资料包
另外还有免费的AI大模型学习资料包,供你学习。点击下面的卡片就可以免费领,具体有:
👉AI大模型学习路线汇总👈
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









