



摘 要
随着网络技术的更新迭代,基于HTTP的视频流已经成为不同视频流服务中视频内容传输的事实标准。这使得更多的视频服务提供商通过互联网传输的方式,将各个用户所拍摄的生活视频进行包装整理,并通过互联网平台的方式呈现给用户。然而,这些视频内容在获取过程中很容易受到不同网络环境的影响,比如带宽不足以及不同视频源服务器。这将对当前的网站视频服务平台造成一定的影响。究其根本,则是由于当前的服务平台都采用较为单一的数据提取的方式,难以适应当前多元化数据传输的环境。
因此,基于上述挑战,本文将基于python框架设计一款具有多任务协同异步视频获取的客户端,我们称为Multitasking Asynchronous Video Client(MAV)。本文首先在python语言下设计编写同时支持命令行模式与GUI方式的Http客户端;通过加入多种不同视频网站的视频获取方法,来增加客户端对不同网络源的鲁棒性,以应对来自不同设备传输过程中所产生的各种问题。最后,再利用Python的多线程技术以及异步技术复合式地获取视频的各种元素信息,从而提高视频抓取的效率,并将上述操作利用python实现相应的GUI操作界面。
关键词:http;多线程;视频流;客户端;多平台
Design and Implementation of Python-Based HTTP Client
Abstract:With the newer iterations of network technology, HTTP-based video streaming has become the de facto standard for video content delivery in different video streaming services. This has led to more video service providers to package and organize the life videos taken by individual users by means of Internet transmission and present them to users by means of Internet platforms. However, these video contents are easily affected by different network environments during the access process, such as insufficient bandwidth and different video source servers. This will have an impact on the current website video service platform. The root cause is that the current service platforms are using a single data extraction method, which is difficult to adapt to the current environment of diversified data transmission.
Therefore, based on the above challenges, this paper will design a client with multi-tasking collaborative asynchronous video acquisition based on python framework, which we call Multitasking Asynchronous Video Client (MAV). Specifically, in this paper, we first design and write an Http client in python language that supports both command line mode and GUI mode; based on the above client, we increase the robustness of the client to different network sources by adding a variety of video acquisition methods from different video sites to cope with various problems arising from the transmission process of different devices. Finally, then use Python's multi-threading technology and asynchronous technology to obtain various elements of video information in a composite manner, so as to improve the efficiency of video crawling, and the above operations using python to achieve the corresponding GUI operation interface.
Key words: http; multi-threaded; video streaming; client; multi-platform
目 录第1章 前 言11.1 研究背景及意义11.2 国内外研究现状21.2.1 视频数据获取现状21.2.2 网络带宽的局限性41.3 主要研究内容51.4论文组织结构5第2章 相关理论72.1 http协议概述72.2 多线程相关技术概要72.3 传输过程8第3章 总体设计框架103.1 多任务协同结构103.2 异步数据传输103.3 web客户端113.4 服务器11第4章 主要技术134.1 解决高并发技术134.1.1 多进程技术134.1.2 多线程技术13第5章 多任务视频抓取客户端设计与实现155.1 总体设计方案155.2 具体功能实现155.3 界面设计以及各个子功能说明165.4 对客户端进行功能测试19结论22致谢23参考文献24
第1章 前 言
1.1 研究背景及意义
视频内容在全球IP流量中占主导地位,预计到2020年将达到82%。另外,今天的大部分视讯信息内容都是由一种基于HTTP流媒介业务的视讯流媒介服务所提供的,如DASH、微软的平滑流媒介、Adobe的HTTP动态流媒介,还有苹果的HTTP即时流媒介。流媒体,是指苹果的HTTP实时流媒体服务。在采用HTTP的流媒体中,每一条视频文件可以被划分为几个录像段并保存到服务器上,每个片段在适当的时间被请求,并通过HTTP传输。在HTTP流媒体上,一条视频文件会划分为几个片断并存放在客户端上,每个片段在适当的时间被请求,并使用HTTP传输。目前,由于带宽不足和高度可变,使得网络平台在保证其令人满意的服务质量传输视频内容方面存在着巨大的挑战。因此,为了减少最后一跳广播网络的带宽使用,一些研究人员开始关注信息理论的方法,即服务器同时向多个客户端广播索引编码信息到多个客户。这种广播信息同时被多个客户端接收,他们通过使用侧面信息(以前下载的信息)解码他们需要的信息。编码传输中内容的编码和解码是通过简单的XOR操作实现的。据我们所知,目前还没有在本地部署使用多任务异步传输方式来改善基于HTTP的视频内容传输。 为了保证文件的可靠传输,我们使用制定一种规则来约束传输过程,也就是协议。常见的应用层传输协议有FTP,HTTP,TFTP,SMTP等等。本文开发的是基于http协议的异步多任务协同视频传输服务器。 Http,是一项使用分布式、协作型和超媒体信息系统的应用层协定(虞卫东,2018)。简单而言是一种发表和接收HTML网页的方式,被用来在网页浏览器与网络服务器中间传送信息。也正是由于这种特性,目前这种协议可别用于娱乐性视频的传输服务。随着短视频的业务场景越来越火热,越来越多人开始从PC端传输转为使用手机端进行拍摄上传,这种改变打破了以往网络传输架构,由于手机本身网络传输稳定性各异,视频数据的传输速度出现不同,使得以往视频服务网站的对各个服务器请求的速度出现落差,有时候会出现视频请求流阻塞的情况,这给当前的视频服务平台提供商带来一定的影响。因此本文将开始研究如何解决这种由于传输速度落差而造成视频请求流阻塞的问题,并将更新后的软件通过GUI的方式呈现出一个基础的软件原型。其中,该客户涉及到一些异步传输的技术。这种异步传输技术在目前已经相当普遍了,其主要应用场合就是一个面对面相连的高速分组交换技术,构建在异步时分多路基础之上,并使用一定宽度的信元,实现了包含信息、话音、图象等内容的所有业务的传送。ATM也是一个高速公路联网信息技术,主要系统设计于LAN、WAN、开发者和业务供应商网络系统和因特网的核心网络系统。相比于无连接方法(如IP)来说,这是基于网络连接的数据交换技术。利用光缆线路ATM在源和目标中间建立虚电路(专用通道)。这种线路可以使数据传输的速度和质量都得以提高。
1.2 国内外研究现状
当前,在视频播放平台领域,用户数据自动分析和数字模型的预测很常见。在工作流程中整合来自分布式系统的连续任务,使用户无需传输数据并在适当的时候调用应用程序。在过去的十年中,网格项目中开发了Globus Toolkit, Unicore以及gLite等中间件。这些工具主要侧重于面向服务的网格基础设施,为没有网格计算经验的用户提供无缝和安全的数据源访问。有经验的用户无缝安全地访问数据源。中间件通过网络服务向Taverna工作平台等工作流程管理器暴露应用程序,使用户能够在图形界面中设计和执行复杂的工作流程并远程监控操作。因为抽象数据库界面和众多之间件层的内在复杂度,因此急需专家来设计。配备并测试这些工具。缺乏应用程序经验的使用者无法在图形界面中部署数据流,除非对数据和应用程序的访问被特定的服务包装器所封装。像这样的场景,一般的开发人员都需要花了大部分时间来设置和调试各种工具。然而,通过图形用户界面构建工作流程并不灵活,也没有足够的效率来节省合理的时间。目前,Python是各种应用领域中使用最广泛的语言之一。网络爬虫技术被广泛应用于互联网搜索引擎当中,可以按照预先设定好的规则自动地抓取特定网站信息(Li,2021)。通过Requests数据库可以对按关键词检索的结果或商品信息进行了下载,然后通过正则表达式中的Beautiful Soup对信息进行了初步处理,然后再把信息保存在MongoDB数据库中,实现了预想的目标。
1.2.1 视频数据获取现状
中小型企业依靠详细的网络分析来了解其市场和竞争情况。专注的爬虫通过爬行和索引网络的特定部分来满足这一需求。最关键的是,一个专注的爬虫必须迅速找到尚未被索引的新页面。由于只有通过跟踪一个新的外链才能发现一个新的页面,预测新的外链在实践中是非常重要的。中小型企业使用网络分析来获得有关其市场、潜在客户和竞争的信息。这种分析可以从重点爬虫的索引中提取出来,这些索引包含关于网络特定部分的详细信息。因此,对于一个专注的爬虫来说,让他们的本地索引网页集合与快速增长和变化的网络保持同步是至关重要的。为了实现这一目标,爬虫定期重访并下载网页(肖佳,2018)。由于这个过程在时间和流量上都很昂贵,因此有大量关于高效爬行策略的研究。设计抓取策略的一个关键输入是网页的变化率。在一个更详细的层面上,网页的变化可以分为内容的变化(即发生在文本、图像等方面的变化)和结构的变化(即增加或删除索引网页之间的超链接,或增加未索引网页的超链接网页。重点爬虫的目的是为其客户提供网络特定部分的详细内容分析,接近客户的兴趣。
针对上述情况,若干的研究人员对此进行了深入的研究。其中,ZouWei等人(ZouWei,2020)分析了55,000个网页的抓取情况。数据是从612,000名使用实时搜索工具条的英语用户那里收集的,为期5周(所以偏向于那些确实有变化的网页,因为它们是由人类选择的)。他们考虑了4种类型的时间间隔:基于工具栏用户的浏览行为的时间间隔、5周内的每小时爬行、4天内对每小时爬行中变化较大的网页进行的次小时爬行,以及用2个时钟同步爬行器对变化较大的网页进行的同时爬行。 2分钟内有很大变化的网页。他们表明,页面变化频率和数量与顶级域名、页面主题、URL 深度和页面流行度相关。总的来说,在他们的抓取中,34%的网页在间隔时间内没有变化,而其余66%的网页平均每123小时变化一次。ZhaoRui等人(ZhaoRui, 2014)研究了网络的衰变(死链接)。他们发现,一些网页和网络的大型子图可以快速衰减。他们提出了一个衡量衰变的方法,并假设这可以用于更有效的爬行。他们提到了返回包含错误信息的200状态代码的网页的问题,他们称之为软404网页。衰减措施需要在抓取后计算,但可以在未来的抓取中作为一项功能使用。Zeng等人(Zeng,2019)研究了网络在特定主题方面的时间动态。他们对两个不同主题(埃博拉和电影)的网页进行了为期30天的日常数据收集,他们认为每个主题每天有相同的22200个和27353个 每个主题每天分别有22200和27353个网页。他们发现,页面主题是变化频率和新链接预期数量的一个重要预测因素。他们还发现,重新访问已经下载的页面会导致新的页面,但这些页面不一定有相同的主题。对于这两个主题来说,几乎所有的页面要么变化频率在0到0.1之间,要么在0.9到1.0之间,所以要么非常频繁,要么根本没有。这项工作的局限性在于,他们只研究了两个主题,而且他们对页面变化的定义可能有些松散,因为它没有考虑到动态的html内容,比如广告。 后续,他们还在一整年的时间里对154个网站的每周快照进行了抓取,他们每周对每个网站的下载量高达200,000页。他们发现,网页的周转率很高(出生和死亡),链接的周转率甚至更高。内容变化的范围也可能会随着日期的推移而保持一致:一周内变化的页面可能会在下一个月内出现类似程度的变动,但变化范围不大的页面将继续经历很少的变动;这种相关性在不同的网站之间会有很大的不同(这些观察与我们的观察一致)。页面按每天百分之八的效率生成,他们估计20%的页面在一年后将不再被访问。事实上,新连接的动态性已经明显超过正常内容,他们已经测量了平均每天百分之二十五的更新连接,而一年后大约百分之八十的旧连接被新链接所替换。一旦页面被创建,它们通常只经历轻微的或没有变化。一年后仍可使用的页面中,有一半没有变化。Zhao等人(Zhao,2020)对23,200个页面做了500个小时的抓取,其中变化间隔小于48小时的页面被降维处理。他们发现,很少有案例与泊松模型一致,但只有一小部分有明显差异。他们通过查看顶级域名,按地区对网页进行了汇总,并显示变化发生在 在夜间和周末发生的频率较低。
1.2.2 网络带宽的局限性
在局域网中,由于同时进行的程序较少,所以可用带宽是非常充足的。然而,在广域网中,汇聚着来自各个局域网的流量。这导致每个应用程序分得的可用带宽并不多。并且,随着广域网中应用程序的增加,特定应用程序可用的带宽量将迅速降低(童麟,2018),这可能对应用程序的性能产生重大影响。除了网络会影响应用程序的可用带宽之外,网络管理员也可以通过设置网络 QoS 来限制程序的可用带宽。例如 IP 语音 (VoIP) 的可用带宽一般会比其他的应用程序要高。其中的原理是通过 QoS 提升了 IP语音程序的优先级。因此,当我们开发的程序与这些优先级高的程序同时在广域网中竞争带宽时,我们的程序的可用带宽会变得比较低。除了有限的带宽之外,网络中还存在着 延迟、丢包、抖动、误码等损伤。它们对应用程序的影响不像有限的带宽那样可以让我们直观的观测到。但是它们对产品性能有非常重要的影响。大多数的广域网都使用基于 TCP 和 UDP 的连接传输数据。这两种连接方式对损伤有着不一样的反应。在不考虑带宽限制的情况下,随着延迟和丢包的增加,基于 TCP 连接的应用程序的传输速率会放缓,确保所有数据可以成功传输(米沃奇,2018)。而基于 UDP 的报文因为无连接的特性,依旧会保持高速的发送速率,但是报文可能会丢失或者无法按顺序到达接收端。基于 TCP 的应用程序在传输数据之前,会先确认是否建立了 TCP 连接。 HTTP(www)流量、FTP、 microsoft网络和大多数通用流量以及一些自定义应用协议都是基于 TCP 连接传输。它们对延迟和损伤非常敏感。 假设,我们在北京和广州之间运行一个基于 TCP 的应用程序。在发送数据时,数据不会一次全部发送,而是会被分成一个个的小包分批次发送。它会在确认包(ACK)从接收端返回之前发送尽可能多的数据(在确认包(ACK)从接收端返回之前可以发送的最大数据量由TCP Windows Size参数控制)。并且,它同时会确认数据是否成功到达接收端。在所有数据发送完之前,TCP会重复上述动作。所以,数据的传输是呈锯齿状的。如今,许多公司都在使用VoIP 和video over IP等实时流媒体应用程序。这些应用程序基于UDP协议。就像上文介绍的,UDP 报文对延迟不敏感,但会受到抖动、丢包和误码的影响。这些损伤都会导致语音中断、图片传输受到阻塞等等(李英华,2022)。这是因为,当数据包在网络上传输时,它们受到的时延不一样,这导致它们到达接收端的时间不一致,出现乱序。UDP没有错误重传机制,即使数据包丢失或者乱序,它也不会重新传送。这就像上个世纪我们寄包裹。寄件人不知道它到达的时间,它能否顺利到达,也不知道它在途中有没有损坏。 在良好的局域网中,丢包、抖动、误码、乱序基本上是不存在的。然而,在无线网络、卫星网络和移动网络中,这些损伤则是时有发生。如果我们仅仅是在局域网上进行程序测试,毫无疑问是不够的。而且,随着人们对移动设备的依赖加深,大家会更多的使用WIFI、4G等无线网络来接收数据。这意味着应用程序需要应对这些潜在的丢包、抖动、乱序和误码等损伤。
1.3 主要研究内容
实现http的客户端与http服务器通信以及提供多个用户同时访问服务器的功能,具体实现下面几个功能:
-
编写的服务器同时支持命令行模式和GUI 方式
-
支持客户端使用不同参数来兼容不同视频网站数据获取方法
-
建立对丢包视频数据的重传启动机制
-
建立异步以及多线程技术提高视频数据获取效率
1.4论文组织结构
本文主要分为五个章节:
-
前言。主要介绍了研究本课题的背景与意义、国内外的研究现状以及本课题需要完成的任务。
-
相关理论。主要介绍了http协议以及多线程,包括协议的有什么特点、具体的实现以及多线程的基本概念。
-
总体框架。主要介绍了客户端的设计模式,以及服务器的设计模式。
-
主要实现技术。此处简要介绍了实现过程中所用到的技术,包括视频数据获取框架、异步编程技术。
-
基于http的多任务视频抓取客户端设计与实现。阐述了该软件的主要设计的原理及背后的核心思想,接着介绍了测试的主要平台硬件设备情况,以及相关的准备工作以及测试结果。
第2章 相关理论
2.1 http协议概述
HTTP是一个用来传递互联网数据信息的一种协商方法。这个协定使用的是请求以及结合响应模式的方法来申请数据信息。通常情形下,服务器端采用网络传输的方法向部署在云端的服务器发出互联网申请加入消息,而服务器在接收服务器端的申请加入消息以后,会把相关的内容包括消息协议的版本,以及成功的将错误编码加入到包含服务器端的消息。而通常HTTP消息可以分为用户向服务器的申请加入消息和服务器向用户的应答消息。
一般来说,在http网络上请求消息的一般表示格式:"请求头名称:请求值"。在请求值的表达方法中,就包括了OPTIONS、GET、HEAD、POST、PUT。其中方式GET和HEAD是最常用和最常见的WEB服务器支持方式,其余任何方式的执行都是可选的。方式GET方式取回以Request-URI标记的数据。HEAD方式就是能够取回以Request-URI标记的消息,但仅仅可能在应答中,不回收消息体。而POST方式就是能够利用请求系统来收到申请中的消息,这种方法通常是用于web服务器中的提交登录表单等情况。
2.2 多线程相关技术概要
线程,其实就是一个子任务堆栈区,它是主工作线程拷贝主线程的子任务栈区,然后几个子线程共享一个主线程的任务堆栈空间。其中,线程ID是在用堆栈的编码进行表述的。其中,线程ID是在用堆栈的编码进行描述的。其中整体的主线程与工作线程的流程图如下所示,其中mm_struct表示共用线程区,task_struct表示子线程区。
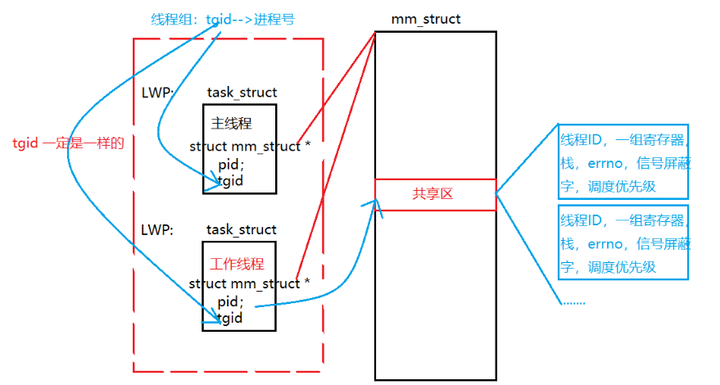
添加图片注释,不超过 140 字(可选)
图1 线程调用方式,其中LWP表示进程,tgid表示线程组的ID。
说起Python的多线程,就不得不提起Python的GIL锁机制(王常衡,2019)。总之,这种全局解译器锁或GIL是一种互斥锁,它只允许一种独有的线程可以拥有全局解译器的权力。所以设计这种GIL锁,就意味着当CPU能够在一个时钟节点上只能有一种线程在运行工作时,这似乎使得多线程加速变得不可能。事实上,对于受CPU限制的程序,多线程与单线程程序的运行时间几乎一样,而对于受I/O限制的程序(比如爬虫程序),线程会在I/O阻塞时(等待网站响应时)释放GIL锁,这时其他线程可以获取GIL锁并继续执行。通过各个线程之间的交替运行,从而实现多线程加速。
2.3 传输过程
基于Http的视频传输过程主要分三步完成传输任务:连接;数据传输;连接中断。
连接建立:
Http本身就是一种协议,其自身并不保留请求与应答双方的通讯状态,即是一种无态协议。这种设置的优点是:可以更快地处理更多的请求事件,并保证了协议的可扩展性。因此也就不存在建立连接与终止连接。一般在传输http时候,都必须设置TCP的链接,再传输报文。具体流程如图2所示。

添加图片注释,不超过 140 字(可选)
图2 构建TCP连接流程
数据传输:假设你每次想传递http消息时都会经历这个步骤,那么很多时间都将会耗费到创建或者断开连接上。所以,http使用连接属性来确定创建链接的方法。当设置为keep-alive时,http创建了一个更持久的链接,而不需要每天都创建链接然后断开连接。这么做的优点是降低了对客户端的负荷,也减少了那部分时间的费用,从而使得http请求和应答都可以更快地完成。而相应地,页面的显示速率也会相应增加。而对于视频数据来说,为了使得http请求速度比持久连接更快,就必须结合流水线技术;而流水线技术的优点则是,请求的数量更大,时间差就越明显。还有GET和HEAD都可能实行管线化,而POST则有所限制。批量提供HTTP请求的用户能够大大减少网站载入时间,尤其是在发送时间(滞后/延迟)很大的条件下(如卫星连接)。这项技术的关键在于,多个HTTP请求信息可以同时塞进一个TCP数据包,因此只需提交一个数据包就可以同时发送多个请求,从而减少网络上的冗余数据包,降低线路负荷。
数据中断:由于在发起网络数据请求是阻塞的,因此编程中通常是由单个线程去申请数据,这将导致这些线程一直处在阻塞状态,即便后续重连成功,所接受到的数据都会作为丢包数据处理。此时,我们要通过在当出现申请超时状态的时侯将这些阻塞的请求异步结束它,但目前仍未实现。但是,面对这个情况,一般的做法都是会在后面接收数据的时候中断掉,其步骤如下所示。首先,我们使用一个定时器来包裹HTTP请求的线程。然后在接收数据时候,避免用大的字节块来读,而是使用while循环来读一个固定大小的块。最后,当同时读取数据时,可以增加一个判断超时时间的要求。就这样,假设数据已超时,尽管我们已经接受了相应的请求,但我们却不能再接受其它数据,这样一来可以节约资源,二来也可为应用节约流量。
-
总体设计框架
3.1 多任务协同结构
针对本文所实现的应用场景,即通过Http网络请求的方式,将基于python框架设计一款具有多任务协同异步视频获取的客户端。这款客户端中比较重要的技术是其多任务协同的功能。可同时获取不同类型的数据的同时,不会造成线程阻塞。此处为了实现这一功能,我们会在数据传输架构中加入协程结构。利用协程的结构动态调整不同任务的资源调度需求。并将合理地且完整的数据获取到客户端中。
利用协程的方式,在有限的CPU资源的情况下,得到最有效的IO流输出,并将这些数据拉取到客户端进行存储。此处用协程的原因是,过去,当你在获取数据时,操作系统会中断当前线程,从而在该线程等待IO的时间内转换到其他线程,这样,在当前线程等待IO时,其他线程可以继续执行。在系统执行绪很小的时候不是问题,可是在执行绪的量特别多的时候,就会出现问题。一个是系统执行绪会浪费大量的内存空间,另外一个是太多的执行绪切换会浪费大量的工作资源。同时执行绪能够处理这二种任务。并发线程执行在一个执行绪上面,在某个并发线程的执行完成之后,它能够通过主动让路,让下一个并发执行绪在当前线程上面执行。线程的数量虽然不会增多,但是多个执行绪以分时的形式线程上执行。
3.2 异步数据传输
对于同步和异步,往往是函数调用后是否直接返回数据,如果函数挂起,直到获得结果,这就是同步;如果函数立即返回,等待数据到达后再通知函数,那么这就是异步历程。对于这种情况,如果采用同步的方式进行数据传输,在传输到某一视频数据的过程中容易造成阻塞,容易造成整个客户端的进程崩溃阶段。因此,在这种情况下,由于上述的阻塞问题,有必要采用异步的方式。一方面,就一个平台面对巨大视频流的数据而言,设置一定数量的线程,虽然能保证客户端不崩溃,但无疑是限制了平台的性能。另一方面,如果使用多个线程,很容易使客户端的稳定性依赖于数据源的稳定性。事实上,同步和异步是应用程序与内核互动的具体方式,当涉及到流媒体视频数据时。同步过程中进程触发IO操作并等待或者轮询的去查看IO操作是否完成。异步过程中进程触发IO操作以后,直接返回,不需要等待其他线程,IO交给CPU内核来处理,完成后内核通知进程IO完成。
主要异步编程分为回调、事件循环、异步调用。
(1)回调:回调函数可以理解为是IO事件完毕后执行提前注册的回调函数。把I/O事件的等待和监听任务交给了操作系统,操作系统在知道I/O状态发生改变后,通过回调通知调用程序。
(2)事件循环:事件循环 "是一种等待程序分配事件或消息的编程架构"。对于Python来说,用于提供事件循环的asyncio被添加到标准库中。asyncio专注于解决网络服务中的问题,事件循环从准备被读取和/或写入的socket中获取I/O。
(3)异步调用:异步IO模型需要一个消息循环,在这个循环中,主线程一遍又一遍地重复着 "读取消息-处理消息 "的过程。所以Python衍生出了一个基于事件循环+基于并发的回调的解决方案。Python 3.4以后通过标准库asyncio获得了事件循环功能,它主要通过选择器模块实现(Swaroop,2005)。
3.3 web客户端
客户端(Client)或称为用户端,是相对于服务器而言的,为客户提供本地服务的程序。除了一些只在本地运行的应用程序,它们一般都安装在普通客户机上,需要与服务器一起运行。其中,网络客户端的主要功能之一就是用来传输HTTP请求,并接受服务器响应。这就是说,所有可以实现这一目的的工具或程式都能够被视为网络客户端,而不仅仅是一种浏览器。也因此,人们既能够通过CURL工具来管理HTTP申请与应答,也能够通过一种编程语言(任何能够支持网络编程的编程语言都可以)。在这里,我们将介绍如何使用多线程和多处理技术来处理多个网络客户端向服务器发出的不同类型的请求。
3.4 服务器
服务器是一个高性能的机器,在互联网上实现各项业务。作为互联网的节点,可以储存并管理互联网上百分之八十的资料和数据,所以它又被称之为互联网的核心。服务器与客户端的基本性能是相同的。只不过与服务器比较,由于客户端对稳定性、安全等基本性能的要求比较多,从而在CPU、芯片组、存储器、硬件操作系统、网络安全等硬件上都与一般电脑有所不同(杨英,2018)。也因此,服务器与客户端之间的主要不同点是:
-
通讯方式必须是一对多:个人电脑、平板、手机等固定式或移动型的互联网终端,上网、收集信息、与外界交流、娱乐等,都必须要通过服务器,而服务器必须采用"一对多"方式来协调和管理这些设备。
-
信息资源通过互联网资源共享:客户端通过侦听互联网上其它接口使用者(Client)所提出的业务要求,并在互联网控制器的管理下,把与其连接的硬盘文件驱动、开印机、Modem和各种专门信息设备等提交给在互联网上的客户站点共享使用,并可为互联网使用者提供集中计费、消息推送和个性信息服务等业务。
-
硬件性能比较强劲:服务器的高性能,主要表现在高速度的计算能力、较长时间的可靠工作、以及强劲的对外数据吞吐能力等方面。服务器香港中华厂商联合会针对不同的使用场合,对服务器进行了差异化设计,目前最主要的使用场合包含了文件交换、数据保存与检索、应用程序应答与执行等。
。
-
主要技术
4.1 解决高并发技术
4.1.1 多进程技术
操作系统在面对多进程的时候,会根据自身的调度算法来进行执行。所以用户是不知道每个进程执行了多少代码后就被CPU给踢出来了。这都是操作系统自己决定的。进程的资源是独立的,所以程序中的全局变量在多进程中是不共享的。在Windows操作系统下,Process写的多进程程序,主进程会等待子进程结束后再结束。意思就是,如果启动子进程是主线程的最后一个进程,那么这个进程会在等待所有子进程结束然后自己也结束即可。如果开启子进程后主进程还需执行任务,此时主进程和子进程会共同占用CPU,主进程并不会等子进程结束之后再执行自己的代码。通常来说,在构建多进程技术时(Andre,2001),我们会调用multiprocessing类来创建多个进程。其中该类是继承Process类.创建多进程主要由以下步骤:
-
引入进程池Pool,并将既定的进程数赋值给这个进程池。
-
将需要并行的程序写入循环中
-
通过调用进程池的属性方法apply_async()来将需要并行的程序分发下去各个进程。
-
构建进程之间的通信Queue,其中该Queue包含get方法和put方法。在实际应用中,我们会通过使用get方法和put方法来对当前进程进行判空和判满处理。但是二者不能同时存在。
4.1.2 多线程技术
线程是指某个过程中单独的、并发的运行流。过程中的线程比分离的过程更少地将彼此分离,它共用了存储器单位、文件柄以及其他过程所期望的状态。而由于线程的分布规模较过程小,所以也使得多线程程序拥有较高的并发性能。过程通常在运行流程中具有单独的存储器单位,而许多线程共享内存,这就极大地提高了程序执行的效能。又因为同一个过程中的线程具有共性,许多线程都共用了某个过程的虚拟空间,所以线程的效能往往要超过进程。而线程的共用环境中还有过程的编码段、过程的公有信息等。由于使用了这些共有信息,所以线程间的交流也很易于进行。当建立过程后,运行系统就需要给再过程提供一段单独的内存空间,并配置一定量的相关资料,而建立并行也就相对容易多了。所以,利用多线程来进行并发比利用更多过程的有效率得要多。具体多线程的构建步骤如下所示:
-
引入线程组模块threading
-
创建线程组用于装载各种线程
-
设置为默认线程,即非守护线程。在默认情形下,主线程并不是在等待子线程完成任务,而是异步执行程序,把任务交付子线程以后,主线程可以继续往下进行,当出现了新的任务以后,主线程既可以选择自己进行,也可以继续产生出新的子线程去进行,在主线程进行了完成部的程序以后,这个时候主线程并不回退出,也就是不会销毁,直到所有的子线程完成了各自的任务后才自动销毁。
-
对同步线程设置timeout,主线程会等待子线程timeout的时间,然后继续往下执行,主线程执行完后不会退出,而是等待子线程完成任务后再退出。
-
多任务视频抓取客户端设计与实现
5.1 总体设计方案
本设计准备开发一个客户端的设计开发以http协议为参照,而相关指标进行参数修改配置。同时,收集整理相关资料,完成客户端的调试与运行。利用python实现相应的GUI操作界面,利用Python的多线程技术提高视频抓取的效率以及实现http客户端的多任务操作,同时支持命令行和图形界面操作两种操作方式。
基于上述的设计将由以下几个方面构成设计方案如下:
-
收集数据源:首先是搭建客户端与各个数据源之间的http连接。此处需要构建多个ip池。以模拟多个用户同时向服务器端拉取数据的场景。此处网络通信方式是利用套接字技术进行通信的实现。然后对于ip池的构建,首先使用proxies将已经抓取的若干IP代理向指定的IP发起请求,如果既定时间内,范围成功访问码,说明这个IP是可用的,否则该IP不可用。同时数据源的收集是根据各个视频网站平台的播放流量进行划分。
-
多线程架构搭建:在编写好相应的数据服务请求程序之后,将利用异步架构将该数据服务请求封装起来。
-
超时重传机制:在连接阶段,设置一个超时时间timeout。同时在数据发起POST请求的时候,会设置随机访问时间,以模拟不同时区的用户向服务器发起请求的行为。如果在既定的时间内,数据无法正常返回,则通过异常捕获的方式将这一记录进行捕获,然后再次发起TCP请求,此时通过更好User-Agent来重新封装请求头,向服务器发起请求,如果仍然失败,则判定该数据链路不可用。
-
多任务封装:根据视频源内容对除了视频流数据进行获取的同时,也把相关的新闻数据、视频封面数据也一起获取。
5.2 具体功能实现
下面重点介绍两种功能的实现,分别是兼容不同视频网站的数据获取功能以及多任务线程封装功能。
-
兼容不同的视频网站数据获取 通过收集抓包的方式,先获取不同视频网站中所出现的数据链接,然后将这些数据链接按照前端元素进行划分,排除无效的数据链接。筛选的伪代码如下所示:
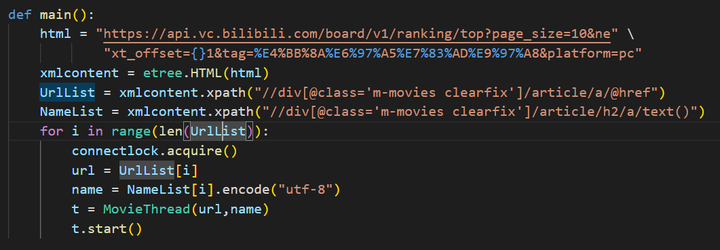
添加图片注释,不超过 140 字(可选)
图5-1 视频源数据解析 然后再对获取后的数据进行链路有效性判断,即这个数据链路是否有资源。我们通过对这些链路发起GET请求,让该资源所在服务器返回相应的响应值回来,以此来判断是否有效。
-
多任务封装功能
首先引入Threading模块,然后将任务放入到线程池中,并将对该任务线程添加相应的功能说明。以下为当前多任务封装的伪代码基础原型。
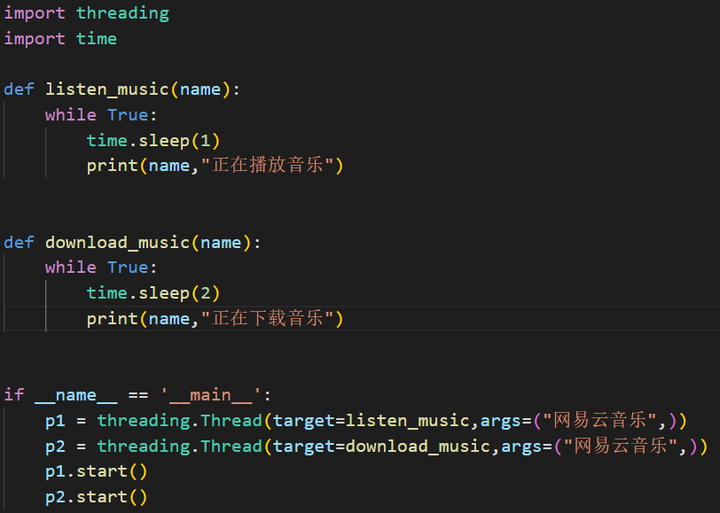
添加图片注释,不超过 140 字(可选)
图5-2 多线程伪代码
5.3 界面设计以及各个子功能说明
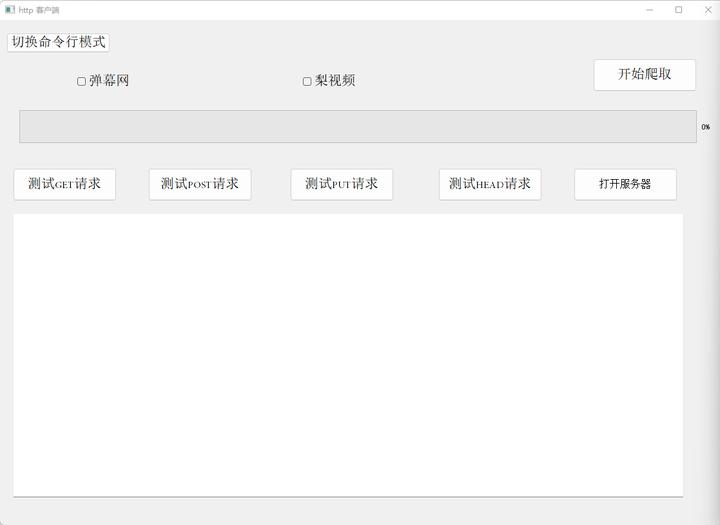
添加图片注释,不超过 140 字(可选)
图5-3 客户端主界面
利用python中的pyqt5框架进行UI设计,根据功能点设置对应的按钮点击事件、文本展示事件等。并最终将上述的功能整合到一个主函数文件中。最终效果如图所示。主要的流程如下所示,对于本文所提出的第一个功能,即实现向服务器发起POST、GET等请求,并接受服务器相应的应答。此处先构建起一个简易的服务器作为容器。具体实现代码如下所示:
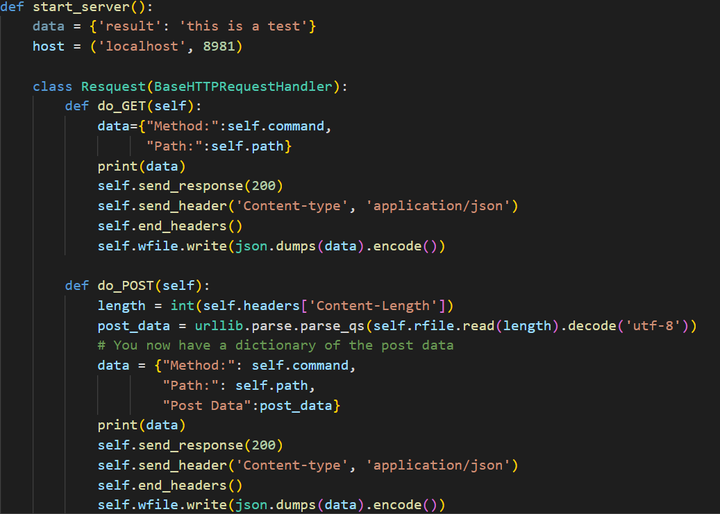
添加图片注释,不超过 140 字(可选)
图5-4 服务器端代码框架
由上述代码所示,我们将服务器接口设计成捕获Get、POST请求。然后将相应的返回结果通过json形式返回到客户端。然后点击“打开服务器”按钮,将从程序中调取一个新的客户端,然后再客户端中输入打开服务器的命令,则服务器的服务就启动,如果客户端出现如下显示,则说明服务已经启动。
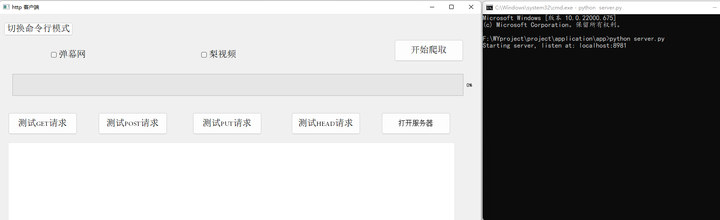
添加图片注释,不超过 140 字(可选)
图5-5 客户端开启服务主界面
接着,就是测试客户端对服务器请求响应的功能。通过点击“测试GET请求”按钮、“测试POST请求”按钮等,分别向服务器发起GET请求、POST请求、PUT请求等。其中GET请求会将返回状态码返回到客户端,返回结果如下图所示。
Get请求测试:
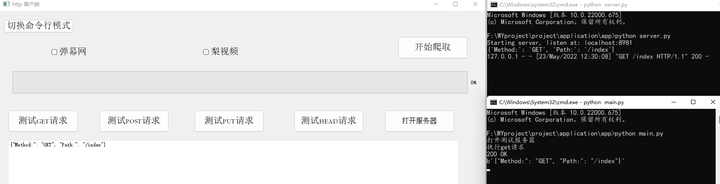
添加图片注释,不超过 140 字(可选)
图5-6 客户端GET请求测试
而POST请求则是返回相应的状态码,以及请求的内容,如此,我向服务器发起了一句请求的话“I am client,hello world”,得到相应的返回信息。具体运行如下图所示。
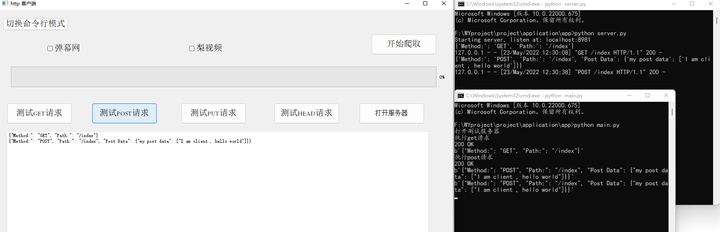
添加图片注释,不超过 140 字(可选)
图5-7 客户端POST请求测试
而put请求的功能与POST请求的功能比较类似,但是唯一不同的是如果连续发起两次PUT请求的话,后一个PUT请求会覆盖前一个PUT请求。具体的PUT请求如下所示。
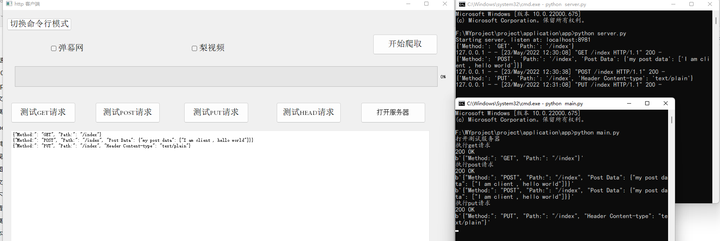
添加图片注释,不超过 140 字(可选)
图5-8 客户端PUT请求测试
最后是Head请求的功能测试。HEAD方法与GET类似,但是HEAD并不返回消息体。在一个HEAD请求的消息响应中,HTTP投中包含的元信息应该和一个GET请求的响应消息相同。这种方法可以用来获取请求中隐含的元信息,而无需传输实体本身。这个方法经常用来测试超链接的有效性,可用性和最近修改。具体的Head请求功能如下图所示。
Head 请求
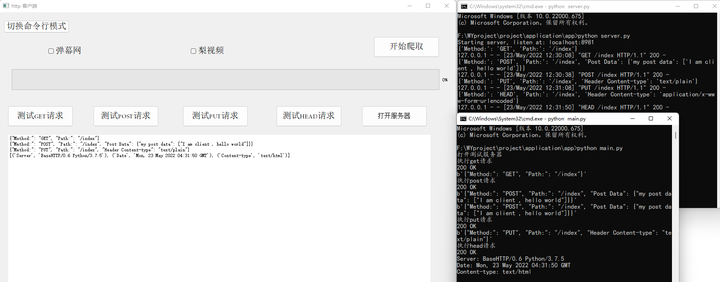
添加图片注释,不超过 140 字(可选)
图5-10 客户端HEAD请求测试
5.4 对客户端进行功能测试
代码编写调试基本完成,进行功能测试验证结果。
测试准备:
实验环境:一台带有Windows系统的电脑,具体版本如下:
使用框架:beautiful soup。
使用语言:python
编译器gcc版本:gcc version 9.3.0。
客户端与服务器端代码编译生成的可执行文件main.py启动客户端GUI与server,测试客户端在获取视频数据时所提交的POST请求是否有效,以及下载视频时的GET请求是否有效。同时也测试利用多任务异步数据的方式,同时获取文本数据。最终数据获取结果如下图所示。

添加图片注释,不超过 140 字(可选)
图5-11 客户端获取视频数据界面
添加图片注释,不超过 140 字(可选)
图5-11 客户端获取文本数据界面
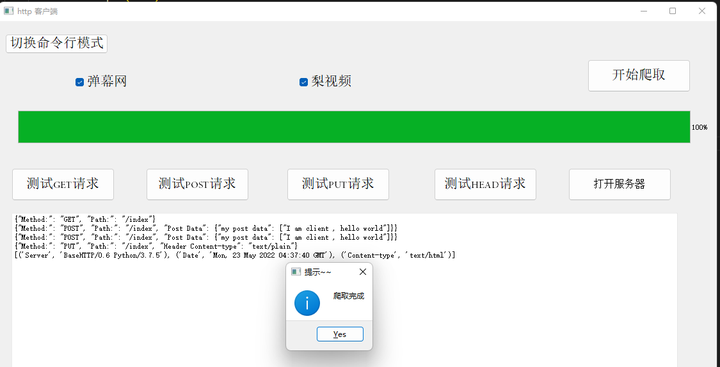
添加图片注释,不超过 140 字(可选)
图5-13 完成爬虫操作时的界面反馈
结论
本篇论文呈现了基于http协议的客户端的设计与开发,论文以http协议为参照,根据预期目的指标进行参数修改配置。同时,收集整理相关资料,完成客户端的调试与运行。利用python实现了相应的GUI操作界面,并且通过Python的多线程技术提高视频抓取的效率以及实现http客户端的多任务操作,同时支持命令行和图形界面操作两种操作方式。
对比现有研究成果,优点是兼容性高,可同时支持两种操作方式会。其次可支持多种任务,可拓展性强;后续可以根据现有的客户端所收集的数据进行数据二次分析,尝试从这些数据中挖掘到更多有用的信息。
参考文献
[1] 虞卫东.深入浅出 HTTPS:从原理到实战[M]:电子工业出版社,2018,6.
[2] [美]David Gourley,Brian Totty,Marjorie Sayer,Sailu Reddy,Aushu Aggarwal .HTTP The Definitive Guide.人民邮电出版社,2012,09
[3] LiWenhua. Design and implementation analysis of Python based web crawler system[J].Neijiang science and technology,2021,42(02):58-59+26
[4] 肖佳.HTTP抓包实战[M]:人民出版社,2018,061
[5] ZouWei,LiTingyuan.Crawling domain website files based on scrapy crawler framework[J].Modern information.technology,2020,4(21):6-9
[6] The Year book is selected from Tibet Statistical Year book(2013).Edited by ZhaoRui,China Local Chronicles Yearbook,2014,2(15),Yearbook [7] ZengXiaoqin.Implementation of Chinese stuttering segmentation technology based on Python[J].Information and computer(theoretical Edition),2019,31(18):38-39+42
[8] ZhaoZhijing,JiangDi.Research on language classification based on editing distance[J].Language research,2020,40(02):43-50
[9] 童麟,郑小盈,李明齐.基于SDN技术的数据中心间可用带宽测量设计与实现[J].工业控制计算机,2018,31(08):34-36.
[10] 米沃奇.影响网络速度的两个重要因素:网络带宽和网络延迟[J].电脑知识与技术(经验技巧),2018(12):93-94.
[11]李英华,崔佳荣.基于丢包和网络测量的TCP拥塞控制算法研究综述[J].数字通信世界,2022(04):9-11.
[12]王常衡,李嘉伟,罗钦,卢曼.浅析Python语言及其应用前景[J].计算机产品与流通,2019,(4).
[13] 杨英.基于客户端/服务器结构的医院信息管理系统的开发与设计[J].电子设计工程,2018,26(09):69-73.
[14] Swaroop.C.H著,沈洁元译. 简明Python教程. 版权 沈洁元 2005.
[15] Andre Lessa 著,张晓晖,王艳斌等译. 深入学习:Python 程序开发.电子工业出版社,2001.


















 627
627

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











