






近年来,Transformer 模型已成为自然语言处理任务中最流行的深度学习架构之一。该模型由 Vaswani 等人于 2017 年推出,在各种 NLP 基准测试中取得了最先进的性能,并已成为该领域的基石。
Transformer 模型的关键创新之一是它对注意力机制的使用。注意力允许模型在进行预测时有选择地关注输入序列的不同部分,而不是将整个序列视为固定长度的向量。这是变压器成功的关键因素,并激发了广泛的后续研究和新模型。
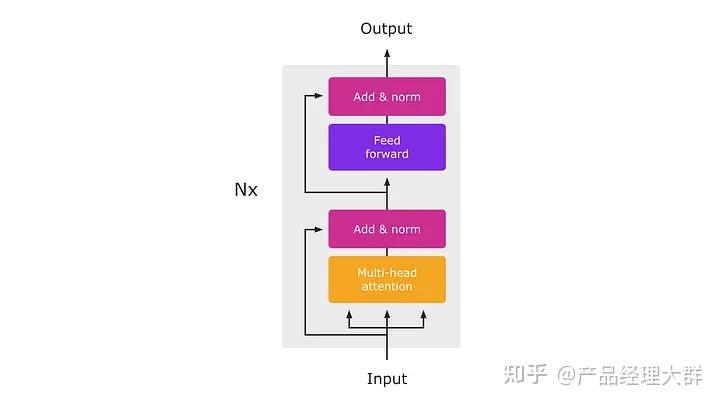
那么什么是注意力,它是如何工作的呢?
从本质上讲,注意力是一种机制,它允许模型动态权衡其输入中不同部分的重要性。在 transformer 模型的情况下,输入是一系列词嵌入,模型使用注意力来决定在进行预测时要关注哪些词。
注意力机制的运作方式是首先为输入序列中的每个单词计算一组注意力分数。这些分数反映了输入中每个单词的重要性,并用于计算单词嵌入的加权总和,从而形成输入的注意力加权表示。
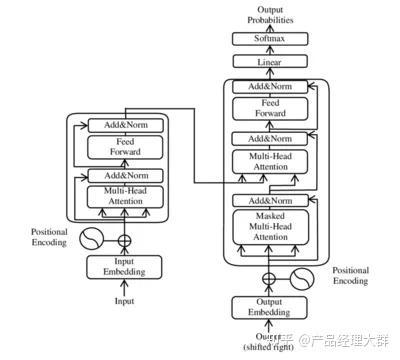
注意力分数是使用模型的当前状态(由一组隐藏状态表示)和当前词嵌入的组合来计算的。这种计算的确切形式在很大程度上取决于所使用的特定注意力机制,但在 Transformer 模型中,它是使用多头注意力机制完成的。
这种多头注意力机制是变压器的一项关键创新,使其能够有效地捕获输入序列中的长期依赖关系。它通过在多个注意力头上并行计算注意力分数来运行,每个注意力头都关注输入序列的不同部分。然后,这些多个头的输出被连接起来,并通过前馈神经网络馈送,以产生输入的最终注意力加权表示。
然后,输入的注意力加权表示被输入到模型的其余部分,该模型利用它来生成预测。模型其余部分的确切架构将取决于要解决的特定任务,但它通常由一个或多个完全连接的层组成,然后是 softmax 层以产生最终预测。
总之,注意力机制是 Transformer 模型的关键组成部分,也是其在各种 NLP 任务上取得显着成功的原因。通过允许模型动态权衡其输入不同部分的重要性,注意力使模型能够捕获输入序列中的长期依赖关系并做出更准确的预测。
Transformer 模型和递归神经网络 (RNN) 都广泛用于自然语言处理任务,但它们在几个重要方面有所不同。
RNN 和 transformer 之间的主要区别之一是它们的架构。RNN 具有顺序结构,其中来自一个时间步的隐藏状态作为输入传递到下一个时间步。这使他们能够有效地对顺序数据中的时间依赖关系进行建模,例如句子中单词的顺序。
相比之下,变压器模型没有顺序结构。相反,它使用注意力机制在进行预测时有选择地关注输入序列的不同部分,而不是将输入作为隐藏状态序列进行处理。这使得变压器非常适合并行计算,并使其能够有效地捕获输入序列中的长期依赖关系。
RNN 和变压器之间的另一个区别是它们如何处理可变长度的输入。RNN 可以处理可变长度的输入,但它们通常需要填充才能使所有序列的长度相同,这可能会造成浪费并导致计算时间增加。另一方面,变压器可以在没有填充的情况下处理可变长度的输入,这使其更加高效和灵活。
最后,在长序列上训练时,RNN 容易出现梯度消失或爆炸,这可能使得难以针对特定任务有效地微调模型。Transformer 模型没有这个问题,因为它没有顺序结构,而是依靠注意力机制来处理输入。
综上所述,transformer 模型和 RNN 都是 NLP 任务的强大模型,但它们具有不同的架构和优势。Transformer 非常适合并行计算和处理输入序列中的长程依赖关系,而 RNN 非常适合对顺序数据中的时间依赖关系进行建模。
Transformer 模型已广泛用于自然语言处理任务和应用。一些最新的用例包括:
- 文本分类:Transformer 模型已应用于文本分类任务,例如情感分析和主题分类,在许多基准测试中取得了最先进的结果。
- 机器翻译:Transformer 模型已应用于机器翻译任务,在翻译质量和效率方面优于以前的方法。
- 问答:Transformer 模型已被用于问答任务,其目标是从给定自然语言问题的大型文本语料库中提取答案。
- 摘要:Transformer 模型已被用于生成长文档的摘要,将文本压缩成更简洁的形式,同时保留其关键信息。
- 对话生成:Transformer 模型已用于对话生成任务,其目标是在对话环境中生成连贯和自然的语言响应。
- 文本到语音合成:Transformer 模型已用于从文本生成语音,为支持语音的虚拟助手等应用生成高质量的合成语音。
这些只是 Transformer 模型在 NLP 中众多用途的几个例子。随着该领域的不断发展,Transformer 模型很可能会继续以新的和令人兴奋的方式使用,从而突破 NLP 技术的可能性。

















 2125
2125

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









