



 本文详细介绍了链表作为动态数组的概念,通过对比传统数组的局限性,阐述了链表如何利用节点间的引用关系实现数据存储。文中通过Java代码展示了Node类的定义,以及如何在链表中添加元素、统计元素个数和判断是否为空的方法。链表的实现包括内部Node类的封装,以及ILink接口的定义,确保了数据操作的便捷性和安全性。
本文详细介绍了链表作为动态数组的概念,通过对比传统数组的局限性,阐述了链表如何利用节点间的引用关系实现数据存储。文中通过Java代码展示了Node类的定义,以及如何在链表中添加元素、统计元素个数和判断是否为空的方法。链表的实现包括内部Node类的封装,以及ILink接口的定义,确保了数据操作的便捷性和安全性。
在项目开发中数组是一个重要的逻辑组成,在项目中可以用于描述“多”的概念,例如,一个人有多本书,一个国家有多个省份等。传统数组中最大的缺陷在于其一旦声明则长度固定,不便于程序开发,而想要解决这一缺陷,就可以利用链表数据结构实现。
链表(动态数组)的本质是利用对象引用的逻辑关系来实现类似于数组的数据存储逻辑,一个链表上由若干个节点(Node)所组成,每一个节点依靠对上一个节点的引用形成一个“链”的形式,如图:

数组本身是需要进行多个数据的信息保存,但是数据本身并不能描述出彼此间的先后顺序,所以就需要将数据包装在节点(Node)中。每一个节点除了要保存数据信息外,一定还要保存有下一个节点(Node)的引用,而在链表中会保存一系列的节点对象,基本结构如图:
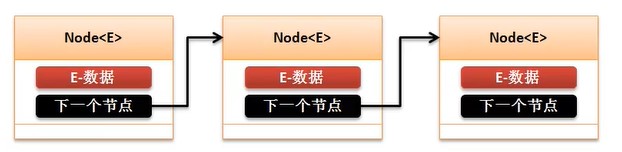
在进行Node类设计时,为了避免程序开发中可能出现的ClassCastException(Java强制类型转换异常)安全隐患,对于保存的数据类型都可以用泛型进行定义,这样就可以保证在下一个链表中的数据类型统一。而对于链表中的Node类的使用可以参考以下形式。
范例:直接使用Node类存放多个数据
package cn.kuiba.util;
class Node<E>{ //定义节点类保存数据和节点引用
private E data; //节点保存数据
private Node<E> next; //保存节点引用
public Node(E data){ //创建节点时保存数据
this.data=data;
}
public E getData(){ //获取数据信息
return this.data;
}
public void setNext(Node<E> next){ //设置节点引用
this.next=next;
}
public Node<E> getNext(){ //返回节点
return this.next;
}
}
public class Main {
public static void main(String args[]){
Node<String> n1=new Node<String>("火车头"); //定义节点对象
Node<String> n2=new Node<String>("车厢一");
Node<String> n3=new Node<String>("车厢二");
Node<String> n4=new Node<String>("车厢三");
Node<String> n5=new Node<String>("车厢四");
n1.setNext(n2); //设置节点引用
n2.setNext(n3);
n3.setNext(n4);
n4.setNext(n5);
printNode(n1); //输出节点信息
}
public static void printNode(Node<?> node){ //从头输出全部节点
if (node !=null){ //当前节点存在
System.out.println(node.getData()+"、"); //输出节点数据
printNode(node.getNext()); //递归调用,输出后续节点内容
}
}
}
程序执行结果:
火车头、
车厢一、
车厢二、
车厢三、
车厢四、
本程序直接利用节点的引用关系,将若干个Node类对象串连在一起,这样进行数据获取时只需根据引用逻辑,从第一个节点开始利用递归逻辑向后一直输出即可。
但如果所有的Node类对象的创建以及引用关系都由调用者来处理的话,这样的实现是没有意义的。因为Node类的设计是为了链表而服务的,链表是一个动态数组,既然是动态数组,那么开发者不需要关注内部如何存储,开发者只关注数据的保存和获取,所以在实际使用过程中,链表需要对外部封装Node的实现与操作细节。如图:
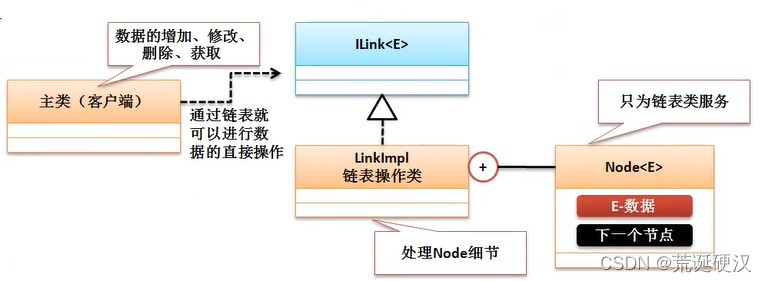
如图,为了方便链表类中对于数据的保存,将Node类设计为了一个内部类的形式,目的是让Node类只为LinkImpl一个类服务,这样就可以形成以下的链表基本模型。
范例:定义链表基本模型
interface ILink<E>{ //链表公共标准
//在此处定义若干链表操作方法
}
class LinkImpl<E> implements ILink<E>{
//使用内部类的结构进行定义,这样外部类与内部类可以直接进行私有成员访问
private class Node<E>{ //内部类封装,对外部不可用
private E data; //节点保存数据
private Node<E> next; //保存节点引用
public Node(E data){ //创建节点时保存数据
this.data=data;
}
}
//-----------以下为Link类中定义的结构----------
}
本程序在LinkImpl子类中定义了Node内部类,为了防止其他程序类使用Node类,所以采用private关键字进行封装,并利用Node类实现引用关系的处理。在链表的整体实现中会依据ILink接口的定义对Node类的功能进行扩充,在链表的整体实现中,ILink接口中定义的主要方法如表:
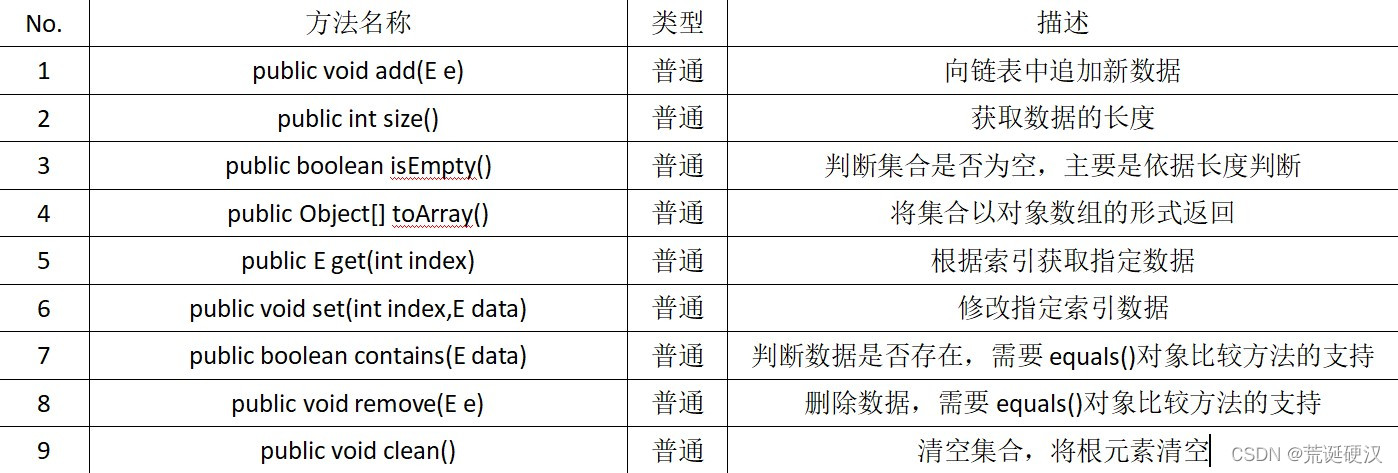
1.链表数据增加
链表在进行定义时使用了泛型,这样就可以保证每个链表中所保存的相同类型的数据,这样既可以避免ClassCastException安全隐患,又可以保证在进行对象比较时的数据类型统一。
链表是多个节点的集合,为了方便地进行所有节点的保存,则需要进行根节点的保存,每一次新增的节点都要按序保存在最后一个节点后进行存储。
(1)【ILink】在ILink接口中定义数据增加方法。
/**
* 向链表中进行数据的存储,每个链表所保存的数据类型相同,不允许保存null数据
* @param e 要保存的数据
*/
public void add(E e);
(2)【Link.Node】每当进行链表数据增加时,都需要创建新的Node类对象,并且需要依据引用关系保存Node类对象,此操作可以交由Node类完成,所以在Node类中追加节点保存方法。
/**
*保存新创建的节点,保存的依据是判断当前节点的next属性是否为空
*@param newNode要保存的新节点
*/
public void addNode(Node<E> newNode){ //保存新的Node数据
if(this.next == null){ //当前节点的下一个节点为null
this.next=newNode; //保存当前节点
}else{
this.next.addNode(newNode); //递归到合适的位置保存数据
}
}
(3)【LinkImpl】链表实现子类中定义根节点对象
private Node<E> root;
(4)【LinkImpl】在LinkImpl子类中覆写ILink接口中定义的add()方法。
@Override
public void add(E e){ //方法覆写
if(e == null){ //保存的数据为null时
return; //方法调用直接结束
}
//数据本身并不具有节点先后的关联特性,要想实现关联处理就必须将数据包装在Node类中
Node<E>newNode=new Node<E>(e); //创建一个新的节点
if(this.root == null){ //现在没有根节点
this.root=newNode; //第1个节点作为根节点
}else{ //根节点存在
this.root.addNote(newNode); //由Node类保存新节点
}
}
在LinkImpl子类中主要功能是将要保存在链表中的数据包装在Node类对象中,这样就可以利用Node类中所提供的next属性来定义不同Node类对象间的先后关系。在链表实现中最重要的就是根节点的保存。
(5)【测试类】在主类中进行链表数据的保存。
public class Main{
public static void main(String args[]){
ILink<String>link=new LinkImpl<String>(); //实例化链表对象
link.add("浩汉"); //链表中保存数据
link.add("浩渺");
link.add("JOE");
}
}
在客户端使用时可以利用子类对象向上转型为ILink父接口对象实例化,可以直接调用add()方法进行链表数据存储,由于链表实现了所有节点的创建与引用处理,所以客户端不必再关心Node类的操作。
2.获取链表元素个数
链表中往往会保存大量的数据内容,同时链表的本质又相当于一个数组,那么为了可以准确地获取数据的个数,就需要在链表中进行数据的统计操作。
(1)【ILink】在ILink接口中定义一个size()方法用于返回数据保存个数。
/**
* 获取链表中集合元素的保存个数
* @return 元素个数
*/
public int size();
(2)【LinkImpl】在LinkImpl子类中定义一个新的成员属性用于进行元素个数的统计。
private int count;
(3)【LinkImpl】在元素保存成功时可以进行count属性的自增处理,修改add()方法。
@Override
public void add(E e){
//其他重复代码略...
this.count ++; //保存元素个数自增
}
(4)【LinkImpl】在LinkImpl子类中覆写size()方法,返回count成员属性
@Override
public int size(){
return this.count; //返回元素个数
}
(5)【测试类】在主类方法中调用size()方法。
public class Main{
public static void main(String args[]){
ILink<String>link=new LinkImpl<String>(); //实例化链表对象
System.out.println("数据保存前链表元素个数:"+link.size());
link.add("浩汉"); //链表中保存数据
link.add("浩渺");
link.add("JOE");
System.out.println("数据保存后链表元素个数:"+link.size());
}
}
完整程序如下:
package cn.kuiba.util;
interface ILink<E>{
public void add(E e);
public int size();
}
class LinkImpl<E> implements ILink<E>{
private int count;
private class Node<E>{
private E data;
private Node<E> next;
public Node(E data){
this.data=data;
}
public void addNode(Node<E> newNode){
if (this.next == null){
this.next=newNode;
}else {
this.next.addNode(newNode);
}
}
}
private Node<E> root;
@Override
public void add(E e){
if (e == null){
return;
}
Node<E> newNode=new Node<E>(e);
if (this.root == null){
this.root=newNode;
}else {
this.root.addNode(newNode);
}
this.count++;
}
@Override
public int size(){
return this.count;
}
}
public class Main {
public static void main(String args[]){
ILink<String>link=new LinkImpl<String>();
System.out.println("数据保存前链表元素个数:"+link.size());
link.add("浩汉");
link.add("浩渺");
link.add("JOE");
System.out.println("数据保存后链表元素个数:"+link.size());
}
}
程序执行结果:
数据保存前链表元素个数:0
数据保存后链表元素个数:3
本程序在进行链表数据保存的前后分别进行了数据个数的统计。
3.空集合判断
链表中可以进行若干数据的保存,在链表对象实例化完毕但还未进行数据保存时,该链表就属于一个空集合,那么就可以在链表中追加一个空集合的判断。
(1)【ILink】在ILink接口中定义一个新的方法,用于判断当前集合是否为空集合。
/**
* 判断当前是否为空链表
* @return 如果是空链表返回true,否则返回false
*/
public boolean isEmpty();
(2)【LinkImpl】在LinkImpl子类中覆写isEmpty()方法。
@Override
public boolean isEmpty(){
return this.count == 0; //判断集合长度是否为0
}
本程序通过判断集合长度是否为0的方式检测当前集合是否为空集合,实际上也可以通过判断根元素是否为空的形式来验证。


















 249
249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









