







结论写在前面
sizeof返回的是以字节(byte)为单位的大小,char的大小永远都是1字节。
字节通常情况下为8位,但是不是必然,也可能是别的大小,比如TI的28x系列DSP里 一个字节的大小为16位。
事情经给
前段时间,发现一个没见过的事情,TI的28x系列DSP中,一个char占据的空间是16位的,但是sizeof(char)的返回值是1。
一开始没注意,后来在程序里读文件,发现读到的值和预期的效果有差异,调试看内存发现从文件读进的一个连续的char的数组,竟然是16位16位占空间的。给char的变量赋值0xFFFF也可以正常的赋值,内存里显示的变量内容就是0xFFFF。于是我认为这个char大小就是16位。
就把这个现象微信群里和朋友说了下,朋友死活不信,认为char就是八位。只不过编译器为了运算效率,内存存储优化成了16字节。哪怕内存监视的时候显示是16位,但用的时候只能按照8位用。
双方僵持不下,当时DSP这块板子也不在身边,没办法talk is less, show me the code。
于是开始翻C89的规范。

里面很明确的提到了sizeof返回的是以byte为单位的大小,而且sizeof(char)的返回值必然为1,也就是1byte。
当时我的认知一直认为一个byte就是8位,所以感觉,这里的c标准在自相矛盾,怀疑是这句子里存在着我不懂的语法,导致我的理解问题有问题(后来证明我想太多)。
后来接着搜各种关键词,搜到了一份28x系列的编译器用户指南,
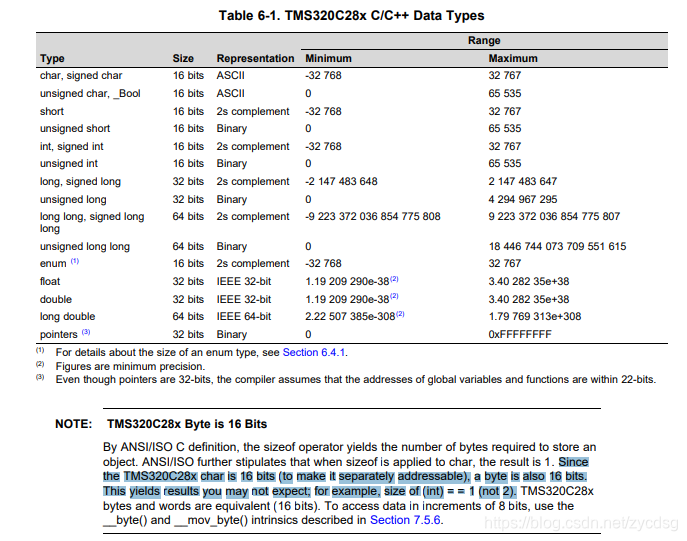
Note这一段讲的非常清楚。这个系列的Byte大小是16位的。又去搜了下Byte这个词条,发现Wiki上也没有说Byte一定是八位的。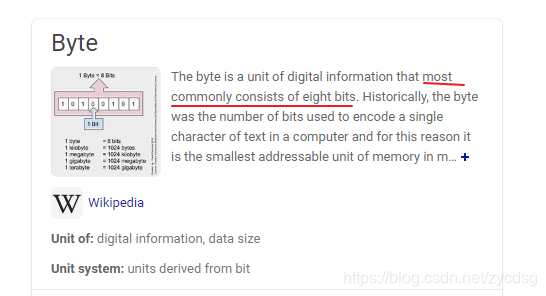
所以问题解决,结论见上。

















 1851
1851

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









