




 本文介绍了在使用Selenium + Chromedriver进行爬虫时,前端JavaScript如何识别模拟浏览器,并提供了解决方案。通过设置navigator.webdriver的getter返回undefined,以及通过添加Chrome启动参数excludeSwitches来避免被识别为自动化工具。
本文介绍了在使用Selenium + Chromedriver进行爬虫时,前端JavaScript如何识别模拟浏览器,并提供了解决方案。通过设置navigator.webdriver的getter返回undefined,以及通过添加Chrome启动参数excludeSwitches来避免被识别为自动化工具。
前端js对模拟浏览器爬虫的解决方案
- 我们在开发爬虫的过程中喜欢使用Selenium + Chromedriver,然后在前端中一行Javascript代码就可以识别出来,从而把你干掉
首先我们用一下代码启动模拟浏览器
from selenium.webdriver import Chrome
driver = Chrome()
如下图:
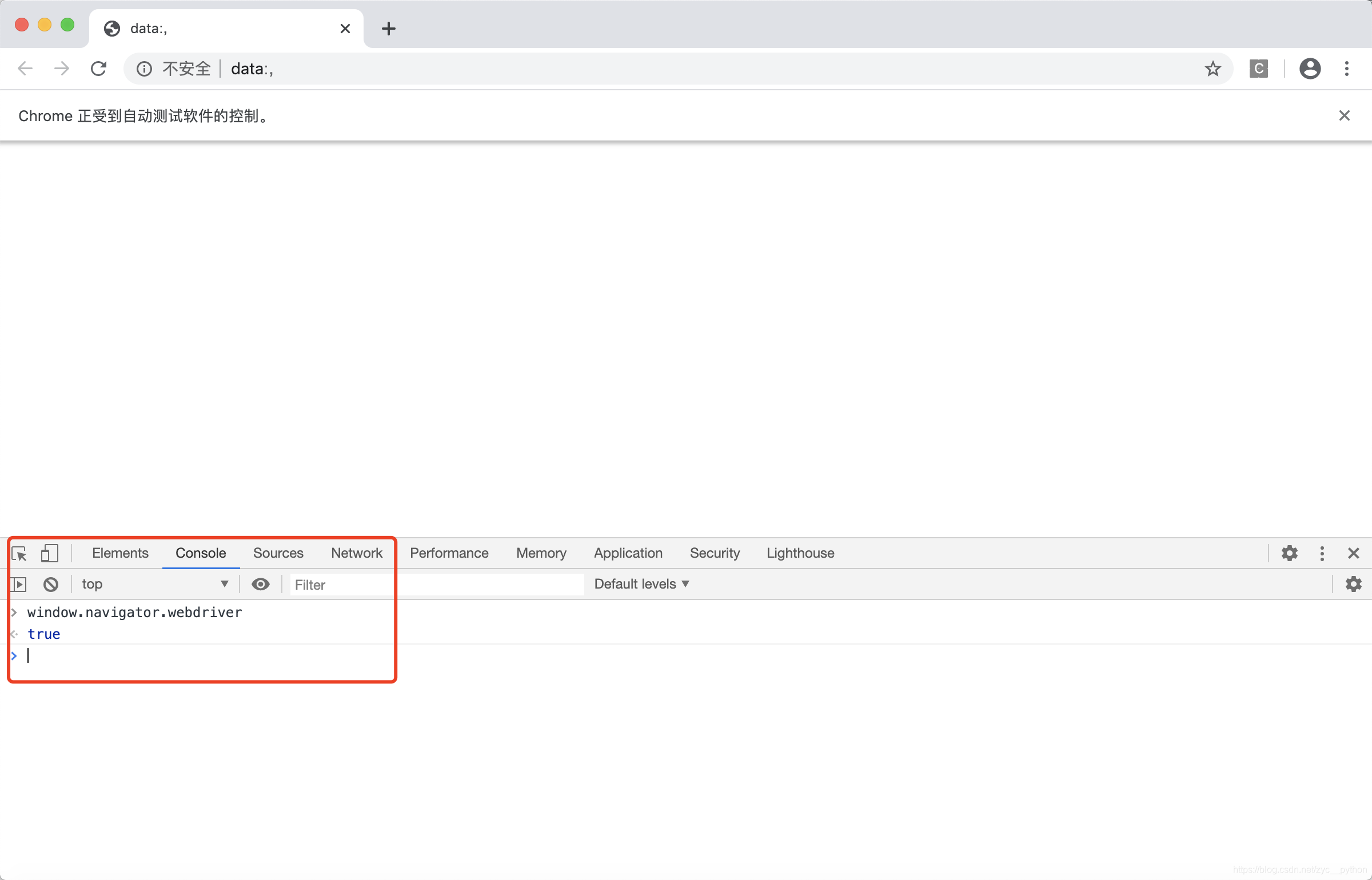
接下来我们用一行js代码来调试window.navigator.webdriver
返回的结果为ture
 接下来咱们返回正常的浏览器进行查看,运行相同的代码,如下图所示
接下来咱们返回正常的浏览器进行查看,运行相同的代码,如下图所示
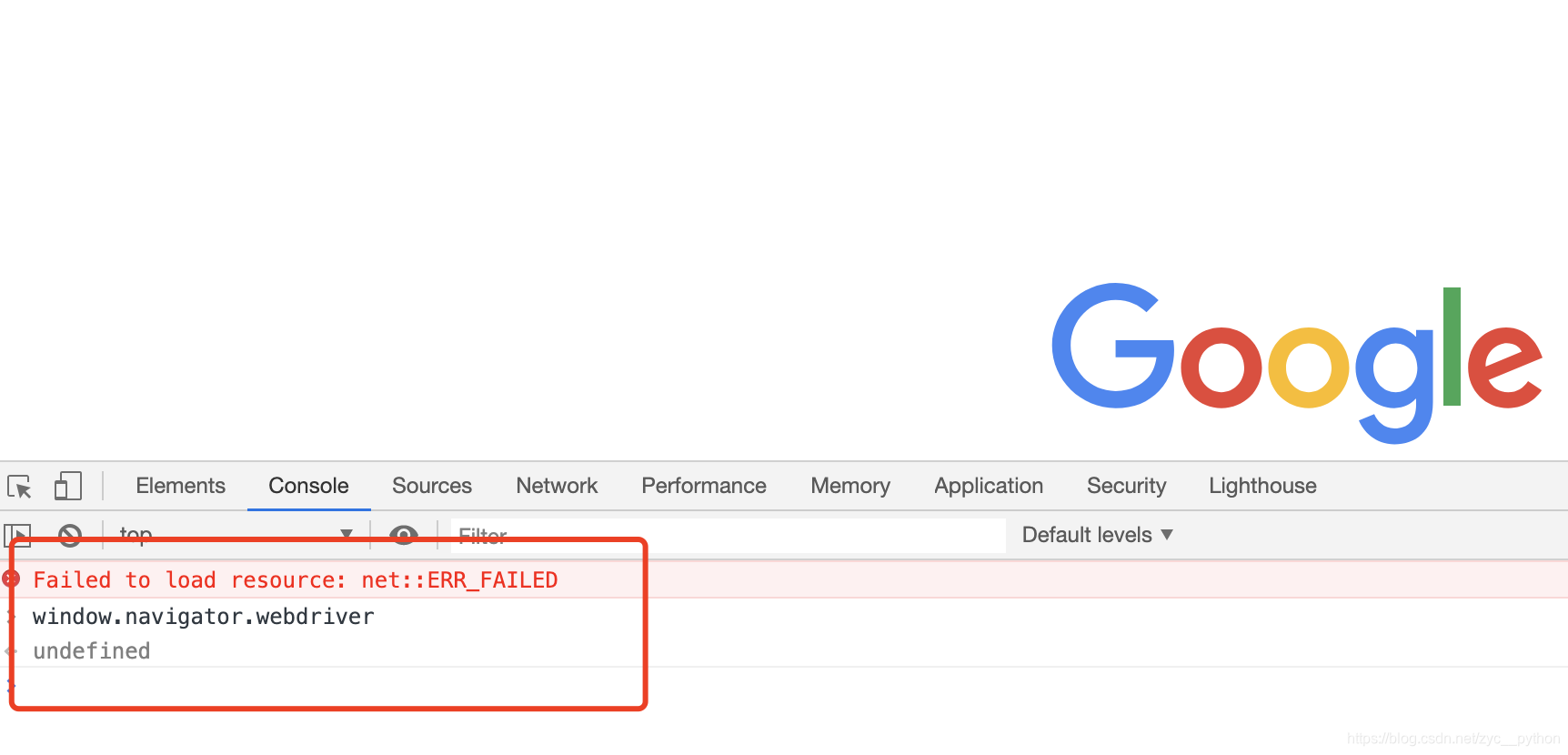 可以看到正常
可以看到正常
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2626
2626

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









