







 本文详细介绍了Java中synchronized的优化机制,包括模板解释器、monitorenter执行逻辑、偏向锁、轻量级锁和重量级锁的工作原理。通过对JVM源码的分析,揭示了从偏向锁到重量级锁的转化过程,以及如何通过锁的状态来提高并发性能。文章还讨论了JDK15中偏向锁的禁用及其对现有应用的影响。
本文详细介绍了Java中synchronized的优化机制,包括模板解释器、monitorenter执行逻辑、偏向锁、轻量级锁和重量级锁的工作原理。通过对JVM源码的分析,揭示了从偏向锁到重量级锁的转化过程,以及如何通过锁的状态来提高并发性能。文章还讨论了JDK15中偏向锁的禁用及其对现有应用的影响。
模板解释器
我们都知道Java之所以可以一次编译到处运行,完全是因为字节码的原因,字节码就相当于中间层屏蔽了底层细节。但是想要在机器执行,最终还是要翻译成机器指令。
而JVM是通过C/C++来编写的,Java程序编译后,会产生很多字节码指令,每一个字节码指令在JVM底层执行的时候又会编程一堆C代码,这一堆C代码在编译之后又会编程很多的机器指令,这样我们的java代码到最终执行的机器指令那一层,所产生的机器指令时指数级的,这也就导致了Java执行效率低下。
早期的JVM是因为解释执行慢而被人诟病,那么有没有办法优化这个问题呢?我们发现之所以慢是因为java和机器指令之间隔了一层C/C++,而GCC之类的编译器又不能做到绝对的智能编译,所产生的机器码效率就不是很高。因此我们只要跳过C/C++这个层次,直接将Java字节码和本地机器码进行一个对应就可以了。
因此HotSpot的工程师们废弃了早期的解释执行器,而采用了模板执行器。所谓的模板就是将一个 java 字节码通过人工手动的方式编写为固定模式的机器指令,这部分不在需要 GCC 的帮助,这样就可以大大减少最终需要执行的机器指令,所以才能提高效率。
在OpenJdk12源码中,JVM所有的解释器都在src/hotspot/share/interpreter目录下,templateInterpreter.cpp就是模板解释器的代码位置。分析这里的initialize方法,我们可以在templateTable.cpp中找到和synchronized相关的两个指令(monitorenter,monitorexit)的实现方式,当然这里面还有其他我们熟悉的指令,比如invokedynamic,newarray等指令
def(Bytecodes::_monitorenter, ____|disp|clvm|____, atos, vtos, monitorenter, _);
def(Bytecodes::_monitorexit, ____|____|clvm|____, atos, vtos, monitorexit, _ );
monitorenter执行逻辑
这里倒数第二个参数的monitorenter函数和monitorexit函数是对应字节码的机器码模板的位置,这里我们看下monitorenter的实现,因为机器码的实现和CPU相关的,这里我们看下x86的实现(templateTable_x86.cpp),当然也可以在src/hotspot/cpu下看到其他的实现,比如ppc,arm,s390等
void TemplateTable::monitorenter() {
...
// 将要锁的对象指针放到BasicObjectLock的obj变量中
__ movptr(Address(rmon, BasicObjectLock::obj_offset_in_bytes()), rax);
// 跳转执行 lock_object 函数
__ lock_object(rmon);
...
}
void InterpreterMacroAssembler::lock_object(Register lock_reg) {
// 如果使用重量级锁,则直接进入monitorenter()执行
if (UseHeavyMonitors) {
call_VM(noreg,
CAST_FROM_FN_PTR(address, InterpreterRuntime::monitorenter),
lock_reg);
} else {
...
// Load object pointer into obj_reg
movptr(obj_reg, Address(lock_reg, obj_offset));
// 关于偏向锁的处理
if (UseBiasedLocking) {
// lock_reg : 存储指向BasicObjectLock的指针
// obj_reg : 存储锁对象的指针
// slow_case : 标记,类似于goto,这里指的是InterpreterRuntime::monitorenter()
// done: 标记,标志着获取锁成功。
// slow_case 和 done 也被传入,这样在biased_locking_enter()中,就可以根据情况跳到这两处了。
biased_locking_enter(lock_reg, obj_reg, swap_reg, tmp_reg, false, done, &slow_case);
}
...
// slow_case逻辑,需要进入InterpreterRuntime::monitorenter()中获取锁。
bind(slow_case);
// Call the runtime routine for slow case
call_VM(noreg,
CAST_FROM_FN_PTR(address, InterpreterRuntime::monitorenter),
lock_reg);
// 这里的done和上面传入到偏向锁的done是一样的。直接跳到这表明获取锁成功,接下来就会返回进行字节码的执行了。
bind(done);
}
}
从代码可以看出如果启用了重量级锁,那么就直接走重量级锁的逻辑(monitorenter),不然会先处理偏向锁的逻辑,然后不满足会再回到monitorenter中
偏向锁: -XX:+UseBiasedLocking , JDK1.6之后默认启用
重量级锁: -XX:+UseHeavyMonitors
偏向锁,轻量级锁以及重量级锁
我们提到了重量级锁和偏向锁,这两个是什么意思呢?
我们都知道Java的线程是映射到操作系统的原生线程之上的,无论是是阻塞还是唤醒一个线程,都需要操作系统的帮助,这就需要从用户态转换到核心态中。而很多人说synchronized慢也正是由于这个原因。之前的文章也说过synchronized实际上是通过操作系统的互斥量来实现的,而这也被称为重量级锁。
相对于重量级锁,还有一个叫做轻量级锁。它的加锁不是通过操作系统来实现的,而是通过CAS配合Mark Word一起实现的,后面我会通过源码来展示它的实现方式。
而偏向锁相对于轻量级锁更加轻量,这里的偏向指的是偏向某一个线程。如果只有一个线程来获取锁,那么锁对象就会偏向这个线程,如果在接下来的执行过程中,该锁没有被其他的线程获取,则持有偏向锁的线程将永远不需要再进行同步。
接下来我们沿着源码从 偏向锁–>轻量级锁–>重量级锁这样来分析下JVM是如何进行优化的。
内存布局
在分析锁实现之前,你可能要先去看看上一篇文章,看看对象在内存中的布局,这里我贴一张图让你在重温下
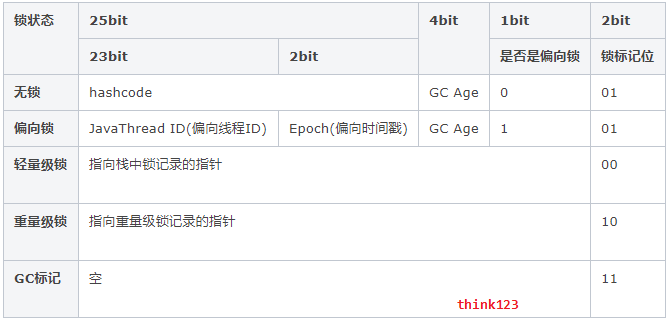
锁状态转化及对象Mark Word的关系
实际上锁的优化逻辑,在JDK中的wiki中已经有一个提纲挈领的图了,这里我先贴出来。后面的代码分析也会跟着这张图走。
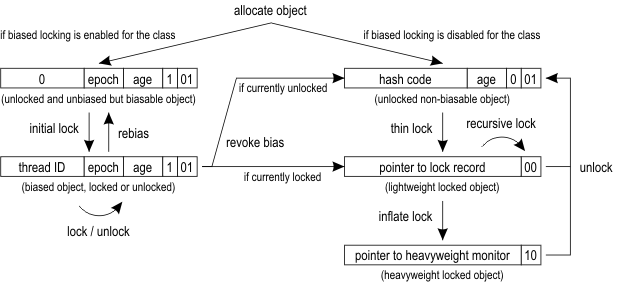
偏向锁
偏向锁的启动
偏向锁会在虚拟机启动后的4秒之后才会生效,我们可以从hotspot/share/runtime/biasedLocking.cpp看到
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1028
1028

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









