







 本文详细分析了kubelet的内存驱逐过程,包括关键调用链路、初始化模块、evictionManager的工作原理。重点讲解了如何通过cadvisor获取节点和Pod的资源统计,如何判断驱逐条件,并根据阈值驱逐Pod。同时,指出了官方文档关于memory.available的误解,建议合理设置阈值以避免OOM。
本文详细分析了kubelet的内存驱逐过程,包括关键调用链路、初始化模块、evictionManager的工作原理。重点讲解了如何通过cadvisor获取节点和Pod的资源统计,如何判断驱逐条件,并根据阈值驱逐Pod。同时,指出了官方文档关于memory.available的误解,建议合理设置阈值以避免OOM。
k8s版本信息:v1.17.4
1. 关键调用链路
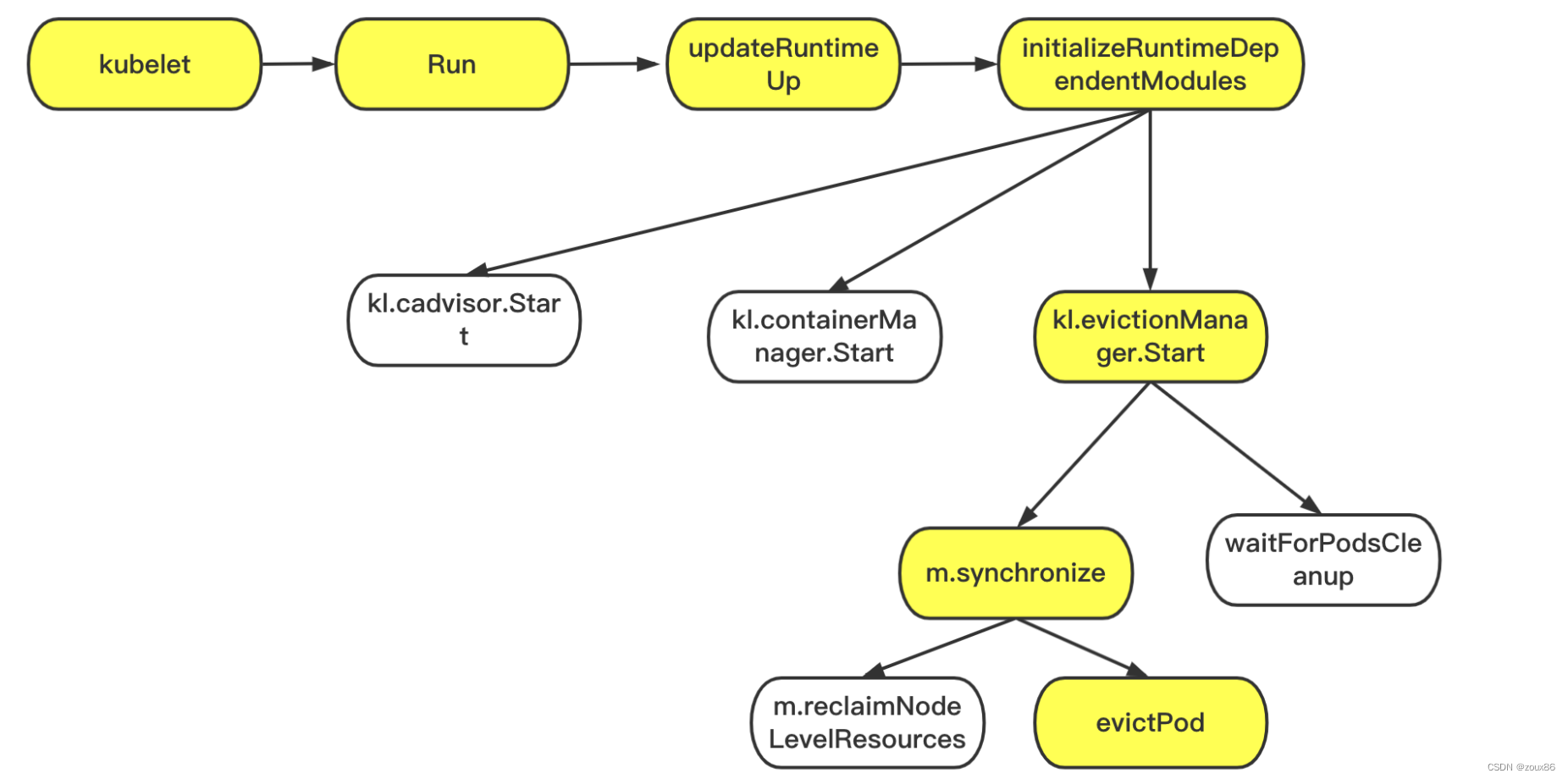
2. initializeRuntimeDependentModules
省略kubelet->run->updateRuntimeUp,直接从initializeRuntimeDependentModules开发分析。
initializeRuntimeDependentModules的核心逻辑就是启动evictionManager和其他相关的组件。该函数只在kubelet运行时启动一次。
这里关注的核心函数:
(1)启动cadvisor
(2)启动containerManager
(3)启动evictionManager
因为evictionManager需要的数据是来源于,cadvisor的,所以必须等cadvisor启动完后在启动evictionManager
// initializeRuntimeDependentModules will initialize internal modules that require the container runtime to be up.
func (kl *Kubelet) initializeRuntimeDependentModules() {
// 1. 启动cadvisor
if err := kl.cadvisor.Start(); err != nil {
// Fail kubelet and rely on the babysitter to retry starting kubelet.
// TODO(random-liu): Add backoff logic in the babysitter
klog.Fatalf("Failed to start cAdvisor %v", err)
}
// trigger on-demand stats collection once so that we have capacity information for ephemeral storage.
// ignore any errors, since if stats collection is not successful, the container manager will fail to start below.
kl.StatsProvider.GetCgroupStats("/", true)
// Start container manager.
node, err := kl.getNodeAnyWay()
if err != nil {
// Fail kubelet and rely on the babysitter to retry starting kubelet.
klog.Fatalf("Kubelet failed to get node info: %v", err)
}
// 2.启动containerManager
// containerManager must start after cAdvisor because it needs filesystem capacity information
if err := kl.containerManager.Start(node, kl.GetActivePods, kl.sourcesReady, kl.statusManager, kl.runtimeService); err != nil {
// Fail kubelet and rely on the babysitter to retry starting kubelet.
klog.Fatalf("Failed to start ContainerManager %v", err)
}
// 3.启动evictionManager
// eviction manager must start after cadvisor because it needs to know if the container runtime has a dedicated imagefs
kl.evictionManager.Start(kl.StatsProvider, kl.GetActivePods, kl.podResourcesAreReclaimed, evictionMonitoringPeriod)
...
}
3. evictionManager.Start
核心逻辑如下 (1)是否利用kernel memcg notification机制。默认是否,可以通过--kernel-memcg-notification参数开启
kubelet 定期通过 cadvisor 接口采集节点内存使用数据,当节点短时间内内存使用率突增,此时 kubelet 无法感知到也不会有 MemoryPressure 相关事件,但依然会调用 OOMKiller 停止容器。可以通过为 kubelet 配置 --kernel-memcg-notification 参数启用 memcg api,当触发 memory 使用率阈值时 memcg 会主动进行通知;
memcg 主动通知的功能是 cgroup 中已有的,kubelet 会在 /sys/fs/cgroup/memory/cgroup.event_control 文件中写入 memory.available 的阈值,而阈值与 inactive_file 文件的大小有关系,kubelet 也会定期更新阈值,当 memcg 使用率达到配置的阈值后会主动通知 kubelet,kubelet 通过 epoll 机制来接收通知。
这个暂时先了解一下,不做深入。
(2)循环调用synchronize,waitForPodsCleanup来驱逐清理pod。循环间隔是10s,monitoringInterval默认10s
kl.evictionManager.Start(kl.StatsProvider, kl.GetActivePods, kl.podResourcesAreReclaimed, evictionMonitoringPeriod)
// Start starts the control loop to observe and response to low compute resources.
func (m *managerImpl) Start(diskInfoProvider DiskInfoProvider, podFunc ActivePodsFunc, podCleanedUpFunc PodCleanedUpFunc, monitoringInterval time.Duration) {
thresholdHandler := func(message string) {
klog.Infof(message)
m.synchronize(diskInfoProvider, podFunc)
}
// 1.是否利用kernel memcg notification机制。默认是否,可以通过--kernel-memcg-notification参数开启
if m.config.KernelMemcgNotification {
for _, threshold := range m.config.Thresholds {
if threshold.Signal == evictionapi.SignalMemoryAvailable || threshold.Signal =
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 530
530

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









