 pdfHTML常见问题解答:HTML转PDF、Base64图像与交互式表单
pdfHTML常见问题解答:HTML转PDF、Base64图像与交互式表单





 本文详细解答了关于pdfHTML的常见问题,包括能否将HTML表单转换为PDF、直接从URL生成PDF、处理Base64图像,以及HTML是否必须是有效XML等。同时,讨论了在将HTML转换为PDF时,如何处理交互式表单、页面尺寸、内联图像以及不完整的HTML等问题。
本文详细解答了关于pdfHTML的常见问题,包括能否将HTML表单转换为PDF、直接从URL生成PDF、处理Base64图像,以及HTML是否必须是有效XML等。同时,讨论了在将HTML转换为PDF时,如何处理交互式表单、页面尺寸、内联图像以及不完整的HTML等问题。
多年来,我们收到了许多关于将PDF转换为HTML的问题。
在本章中,我们将回答那些被问得最多的问题。
-
我可以将HTML表单转换为PDF吗?
-
我可以从URL而不是从磁盘上的文件生成PDF吗?
-
pdfHTML可以将Base64图像渲染为PDF吗?
-
我的HTML必须是有效的XML吗?
-
我们需要一个浏览器引擎来将HTML+CSS呈现为PDF吗?
-
HTML中的测量系统与PDF中的测量系统有何关系?
-
如何将ASP或JSP页面转换为PDF?
-
如何将包含阿拉伯语/希伯来语字符的HTML转换为PDF?
-
在将HTML转换为PDF时,如何将特定的子字符串加粗?
-
如何将多个HTML文件解析为一个PDF?
-
如何将某些HTML实体(如箭头)呈现为PDF?
-
由于许可限制,为什么我不能嵌入字体?
-
为什么我的PDF缺少几个字符?
我可以将HTML表单转换为PDF吗?
将 HTML 表单转换为 PDF 文档的支持有限。如果您有一个HTML文件,其中包含要转换为PDF的文本字段,您还必须指出是否希望生成的PDF为交互式表单。
让我们看看form.html文件:
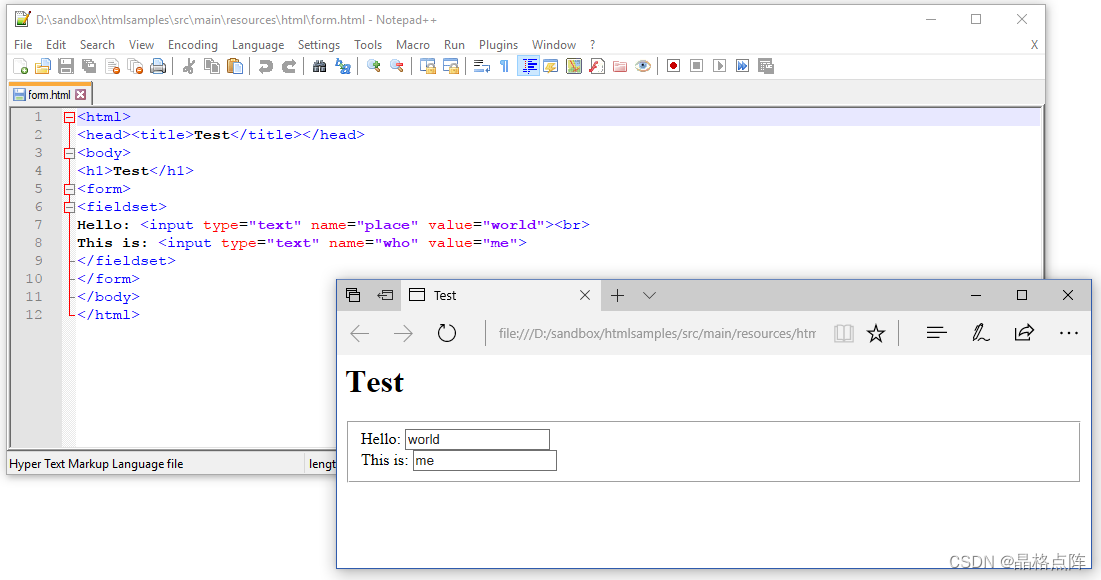
一个简单的HTML表单
如果我们想将此HTML表单转换为PDF表单(基于AcroForm技术),我们需要在ConverterProperty(Java/.NET)中明确提及这一点。请参阅 C07E10_HelloAcroForm.Java 示例:
public void createPdf(String src, String dest) throws IOException {
ConverterProperties properties = new ConverterProperties();
properties.setCreateAcroForm(true);
HtmlConverter.convertToPdf(new File(src), new File(dest), properties);
}
由于行 properties.setCreateAcroForm(true)/properties.setCreateAcroForm(true),创建了一个交互式PDF表单。我们可以手动更改蓝色背景字段中的文本:
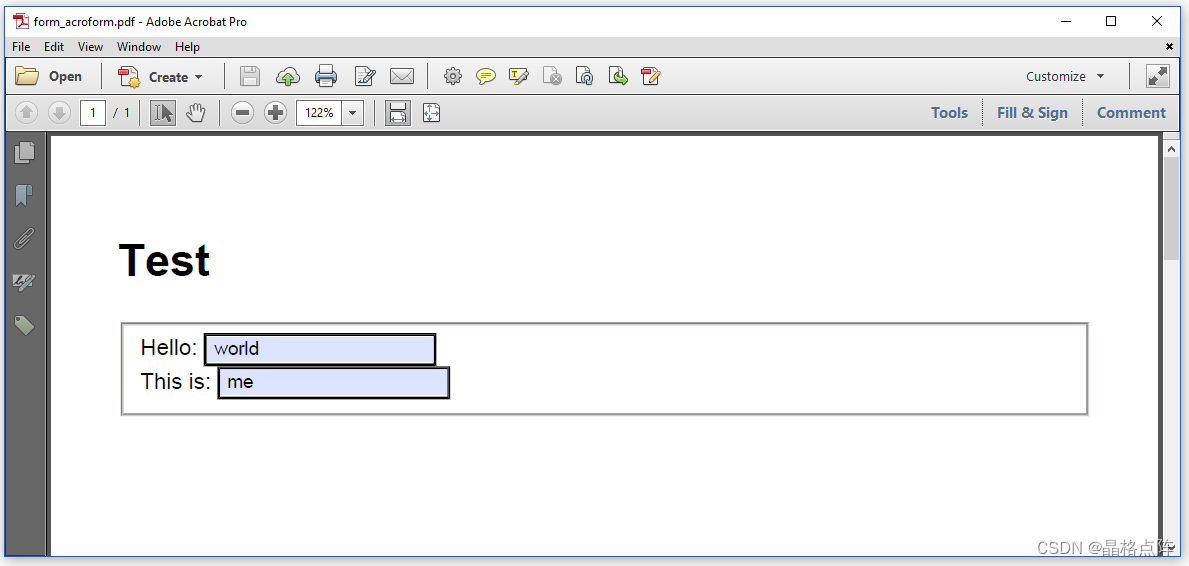
一个简单的PDF表单
如果我们不更改 ConverterProperty(Java/.NET),例如 C07E11_HelloformFlatted 示例,我们将得到一个“扁平”PDF:
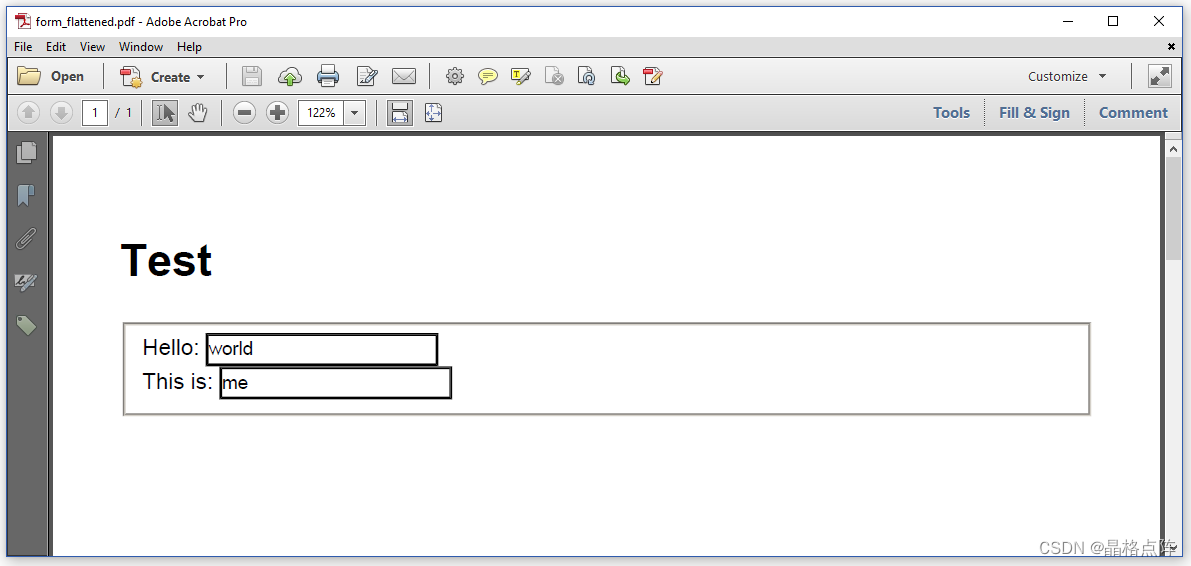
一个扁平的表单
字段的内容在那里,但文件中没有交互。在PDF查看器中无法更改曾经是 HTML 字段的内容。
使用交互式 PDF 表单进行手动数据输入有些过时。当需要手动填写表单时,通常首选 HTML 5。
我可以从URL而不是从磁盘上的文件生成PDF吗?
您可以从任何HTML输入流生成PDF。在大多数示例中,我们使用了 FileOutputStream,但在第4章中,我们创建了仅以 byte[] 形式存在于内存中的报告。在这种情况下,我们使用了 ByteArrayInputStream。我们还可以使用从URL对象创建的InputStream。
假设我们使用这个URL:
public static final String ADDRESS = "https://stackoverflow.com/help/on-topic";
如果在浏览器中打开此URL,我们会看到以下页面:
浏览器中的IMDB页面
在C07E04CreateFromURL示例中,我们使用ADDRESS创建Java URL对象:
new C07E04_CreateFromURL().createPdf(new URL(ADDRESS), DEST);
我们使用下面的 createPdf() 方法:
public void createPdf(URL url, String dest) throws IOException {HtmlConverter.convertToPdf(url.openStream(), new FileOutputStream(dest));}
openStream() 方法为我们提供了一个 InputStream,iText将使用它来获取HTML——显然,这只适用于可以访问 Internet 的机器。
对于包含大量图片的页面,iText可能需要一段时间才能下载所有资源,但此 Stack Overflow 页面中的常见FAQ 页面应该加载的比较快,结果如下所示:
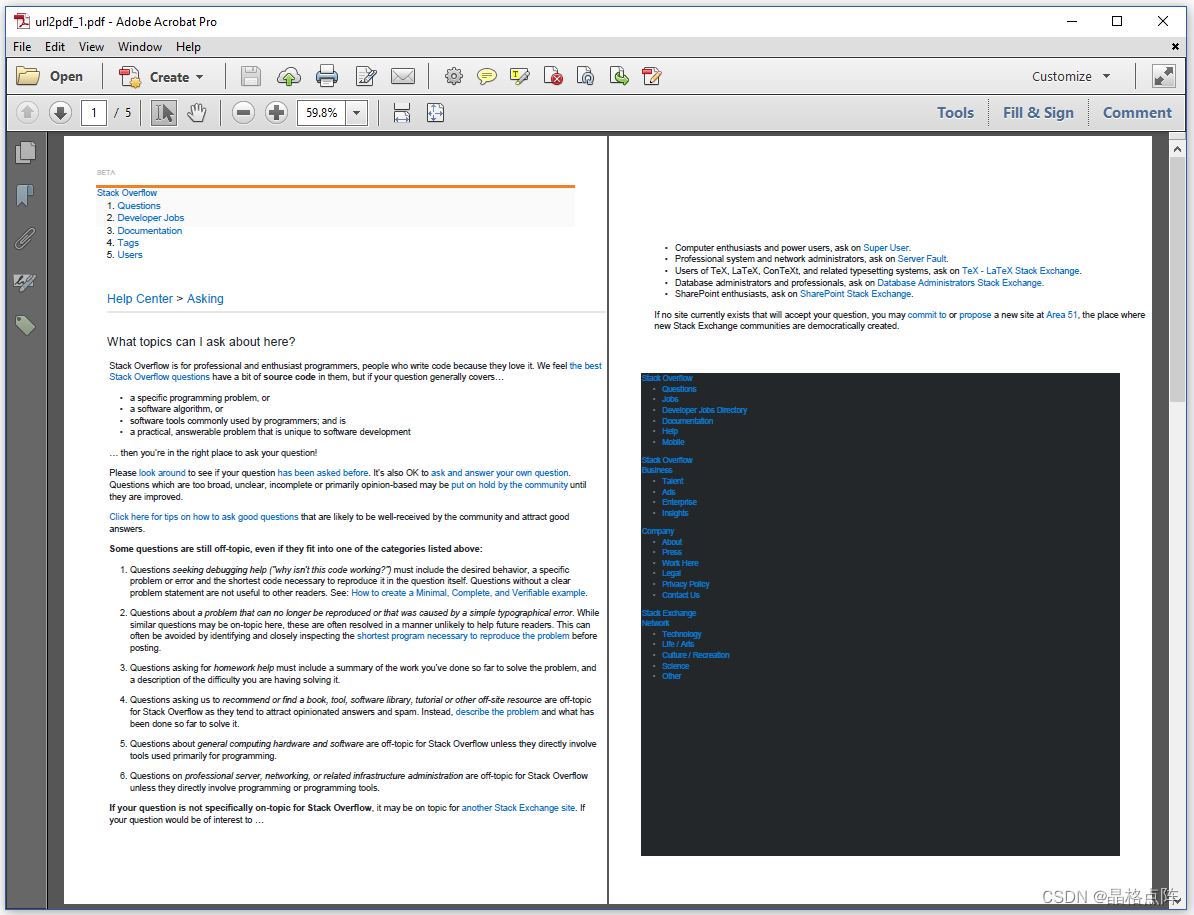
IMDB页面以PDF格式呈现为A4页面
可能A4页面不是网页的理想页面大小,因为缺少完整的边栏。让我们修改下这个例子,并介绍一个媒体查询。
C07E05_CreateFromURL2.java 示例中的 createPdf() 方法如下所示:
public void createPdf(URL url, String dest) throws IOException {
PdfWriter writer = new PdfWriter(dest);
PdfDocument pdf = new PdfDocument(writer);
PageSize pageSize = new PageSize(850, 1700);
pdf.setDefaultPageSize(pageSize);
ConverterProperties properties = new ConverterProperties();
MediaDeviceDescription mediaDeviceDescription =
new MediaDeviceDescription(MediaType.SCREEN);
mediaDeviceDescription.setWidth(pageSize.getWidth());
properties.setMediaDeviceDescription(mediaDeviceDescription);
HtmlConverter.convertToPdf(url.openStream(), pdf, properties);
}
我们使用 850×1700 个用户单元的自定义页面大小,并使用第2章中所述的屏幕媒体类型。现在,内容适合页面,我们得到了更好的结果:
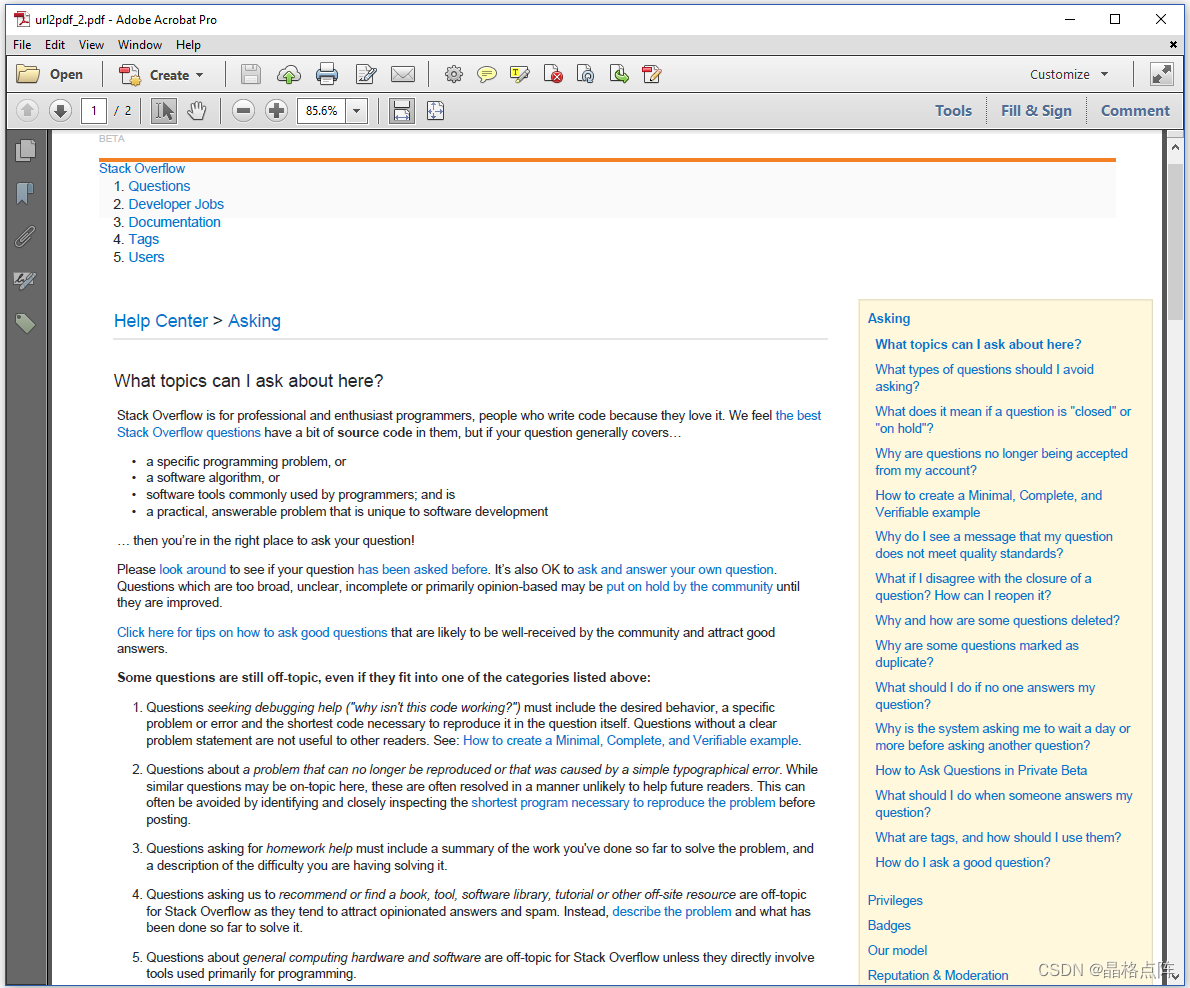
当然,还有一些不完善之处。例如:标题栏中的项目显示为列表,而不是菜单栏中的项目,但我们计划在pdfHTML的未来版本中解决这些问题。
我们也可以使用 PRINT 代替 SCREEN 媒体类型。见 C07E06_CreateFromURL3 示例:
public void createPdf(URL url, String dest) throws IOException {ConverterProperties properties = new ConverterProperties();MediaDeviceDescription mediaDeviceDescription =new MediaDeviceDescription(MediaType.PRINT);properties.setMediaDeviceDescription(mediaDeviceDescription);HtmlConverter.convertToPdf(url.openStream(), new FileOutputStream(dest), properties);}
由于 Stack Overflow 使用的 print.css ,我们现在有两个基本页面,其中故意省略了侧边栏。也许这正是我们想要的:
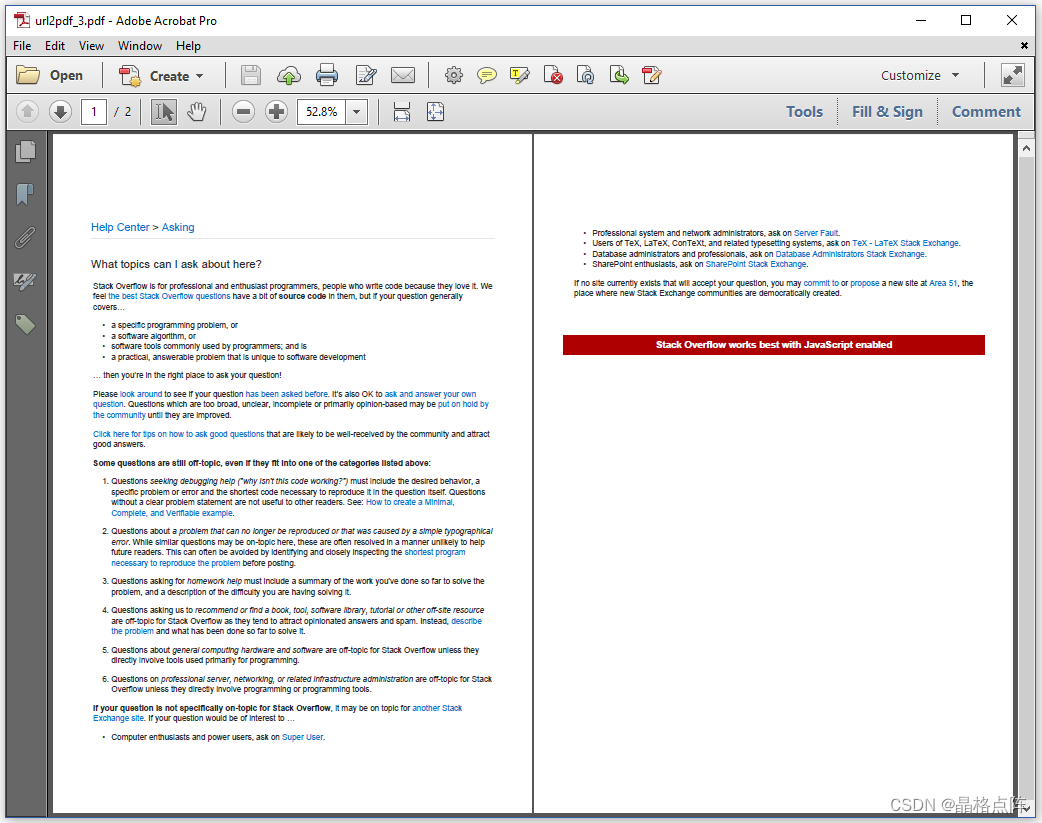
IMDB页面以PDF格式呈现为A4页面
重要提示:pdfHTML 是一项正在进行的工作。如果您尝试从浏览器将网页打印到纸页,您会注意到结果并不总是像您希望的那样好。当使用 pdfHTML 作为URL2PDF 工具时,情况也是如此。大多数HTML页面都不打算打印,但有了 pdfHTML,我们正在不断努力改进转换过程。
pdfHTML 可以将 Base64 图像渲染为 PDF 吗?
是的,iText 支持外部图像,如前几章中的不同示例所示,但它也支持作为Base64字符串存储的内联图像。
例如,请参见 C07E03_Base64Image.java 示例。createPdf()/createPdf() 方法中没有任何特殊之处。
public void createPdf(String html, String dest) throws IOException {HtmlConverter.convertToPdf(html, new FileOutputStream(dest));}
这个示例唯一特别的地方是 base64.html HTML文件(请注意,base64编码的图像被截断以适合此页面):
<html>
<head>
<title>Test</title>
</head>
<body>
<h1>Test</h1>
<p>Hello World</p>
<img alt="Embedded Image" src="data:image/png;base64,iVBORw0...ErkJggg==" />
</body>
</html>
结果与我们在第一章中使用外部图像时得到的结果相同。
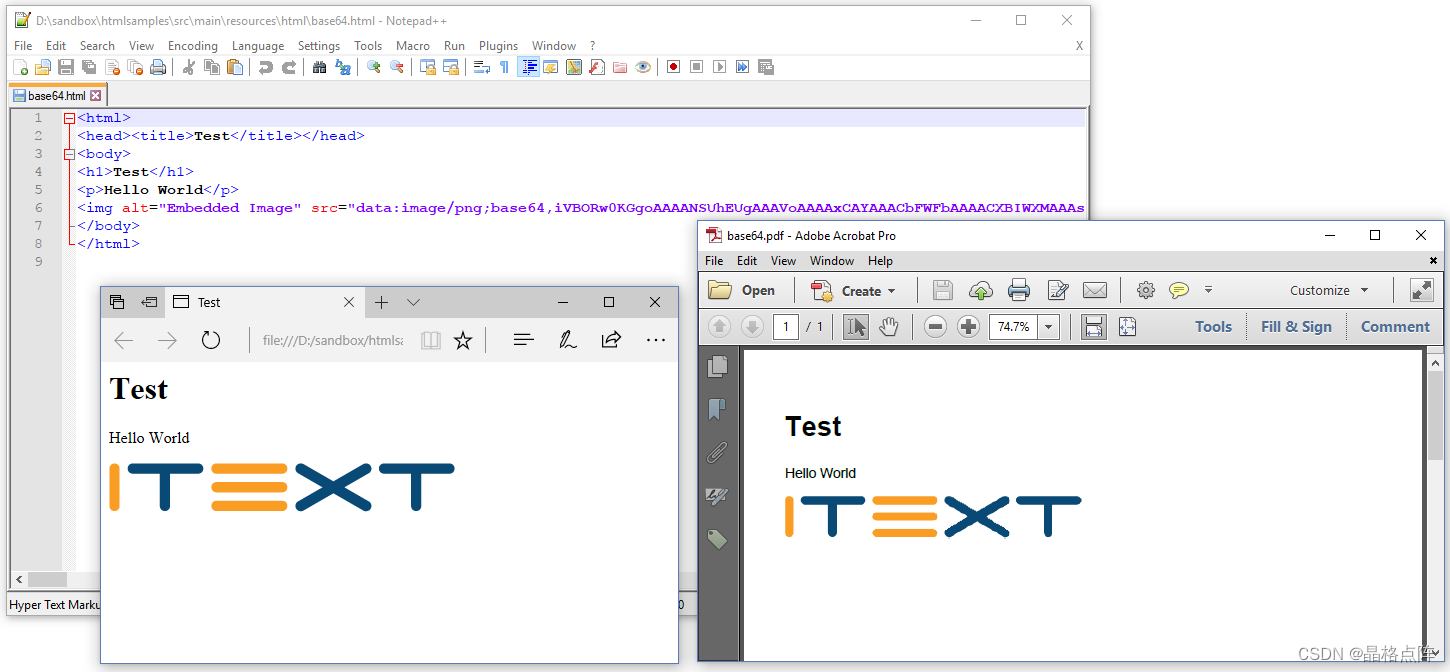
带有base64编码图像的文件的源代码、浏览器视图和生成的PDF
我的HTML必须是有效的XML吗?
如果您仍在使用 iText 5 和 XML Worker,则必须提供 XHTML。例如:HTML 中不允许有一个<br>;您需要有一个<br/>。所有标记都需要关闭。标记的嵌套需要正确完成。为了解决HTML语法不完整的问题,我们建议在使用XML Worker将HTML转换为PDF之前使用jsoup整理HTML。
这对于pdfHTML不再是必要的。我们已经将jsoup集成到pdfHTML插件中,因此您不需要单独调用它。所有html在转换为PDF之前都会被清除。 例如 incomplete.html HTML文件
<html>
<head><title>Test incomplete HTML</title></head>
<h1>Test
<p>Hello World
<p>Hello Universe
<br>
<img src="img/logo.png" alt="iText logo">
它没有任何<body>标记,<h1>、<p>、<br>和<img>标记从不闭合。这是一个非常不完整的HTML文件,但浏览器无论如何都会呈现它,pdfHTML也是如此。
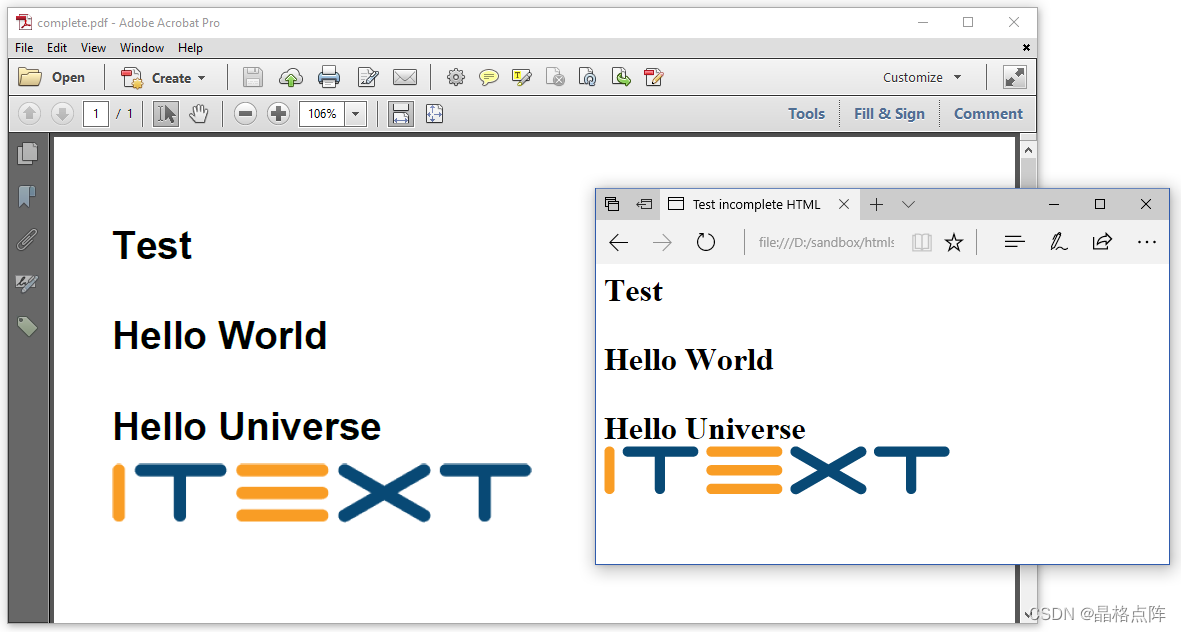
在浏览器中呈现为PDF的不完整HTML
您可以通过运行 C07E07_UncompleteHTML 示例来尝试这一点。
我们需要一个浏览器引擎来将HTML+CSS呈现为PDF吗?
不,pdfHTML负责解析HTML和CSS,并将它们映射到iText对象和样式。然后,iText引擎根据这些对象和样式渲染PDF。
然而,pdfHTML目前不支持SVG,也不评估JavaScript。对SVG的支持已在开发路线图上,您可以通过使用浏览器引擎预处理HTML+CSS+JS来解决JavaScript问题。这种浏览器引擎的例子有WebKit(Chrome、Safari)和Gecko(Firefox)。这些可以解释JavaScript,并提供可以由pdfHTML呈现的HTML。
注:SVG支持于2018年9月添加到 pdfHTML 2.1.0 中,并在后续版本中进行了更新和改进。


















 1405
1405

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











