






 文章描述了一个fy-core项目频繁发生FullGC的问题,通过监控和分析工具定位到问题可能由内存设置不合理、耗时接口和CMS/G1配置错误引起。通过对新生代、Eden区、Survivor区的调整以及启用CMS垃圾回收器,成功降低了FullGC频率并减少了GC时间。
文章描述了一个fy-core项目频繁发生FullGC的问题,通过监控和分析工具定位到问题可能由内存设置不合理、耗时接口和CMS/G1配置错误引起。通过对新生代、Eden区、Survivor区的调整以及启用CMS垃圾回收器,成功降低了FullGC频率并减少了GC时间。
问题描述
运维一直说 fy-core 项目这个项目每天都会发生多次full gc,full gc 会停顿600ms左右,理论上生产环境不允许发生full gc,所以决定把full gc都优化掉。
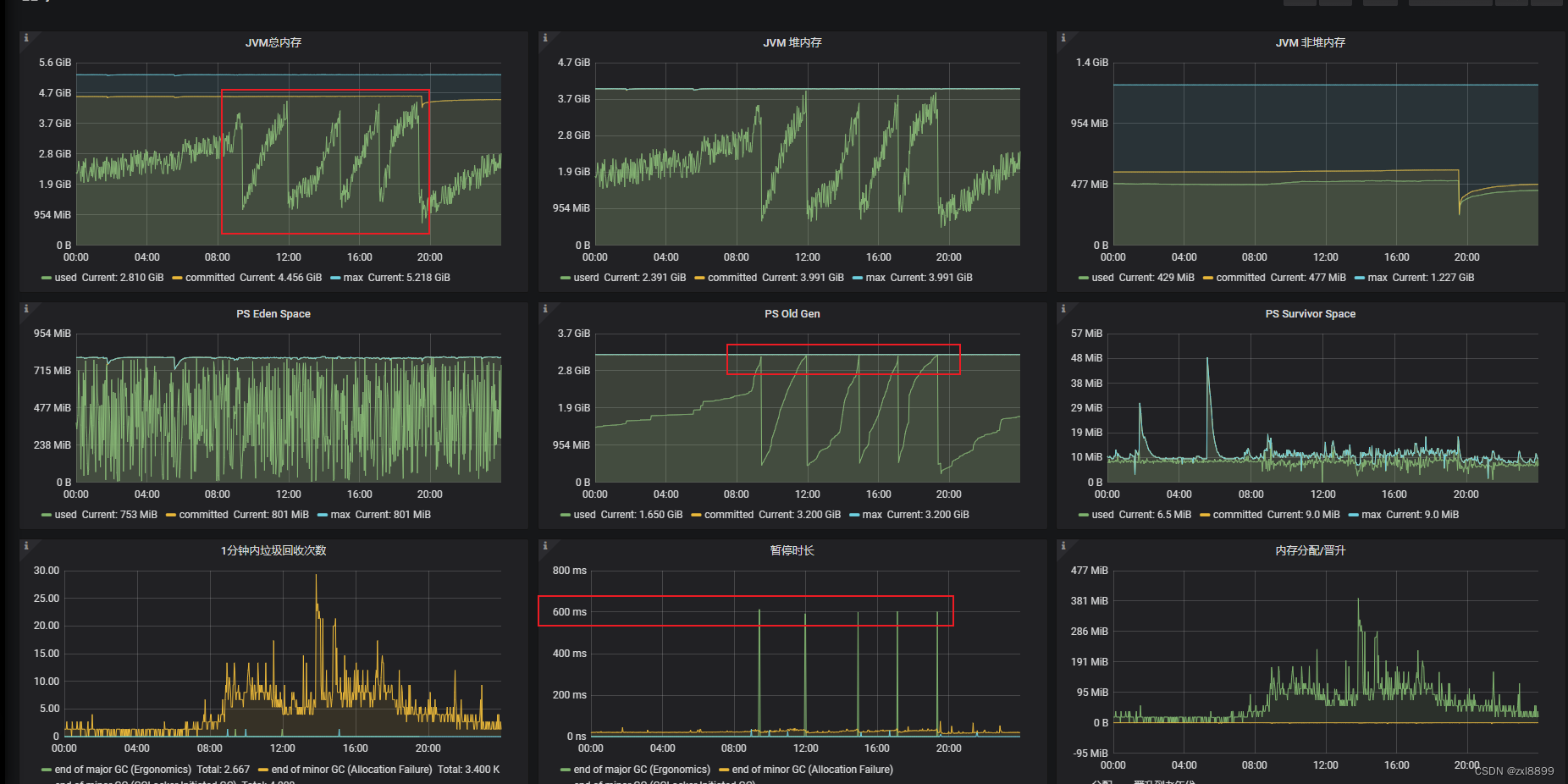
以下是该grafana对应的资源表现,可以看出每隔一段时间就会出现full gc
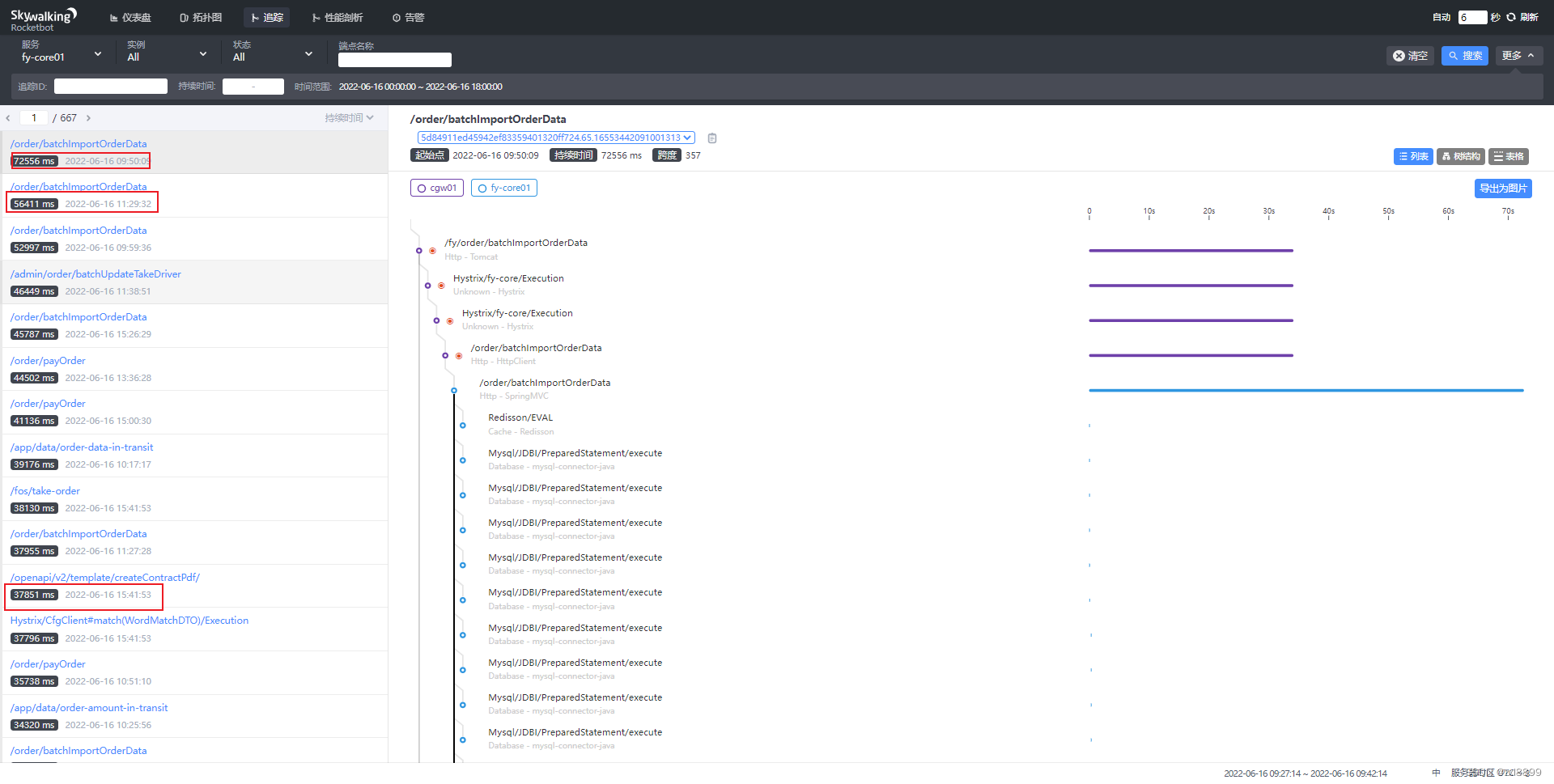
1. 通过skyworking 链路查询某次full gc 过程中的调用,找到一些响应时间过长的接口
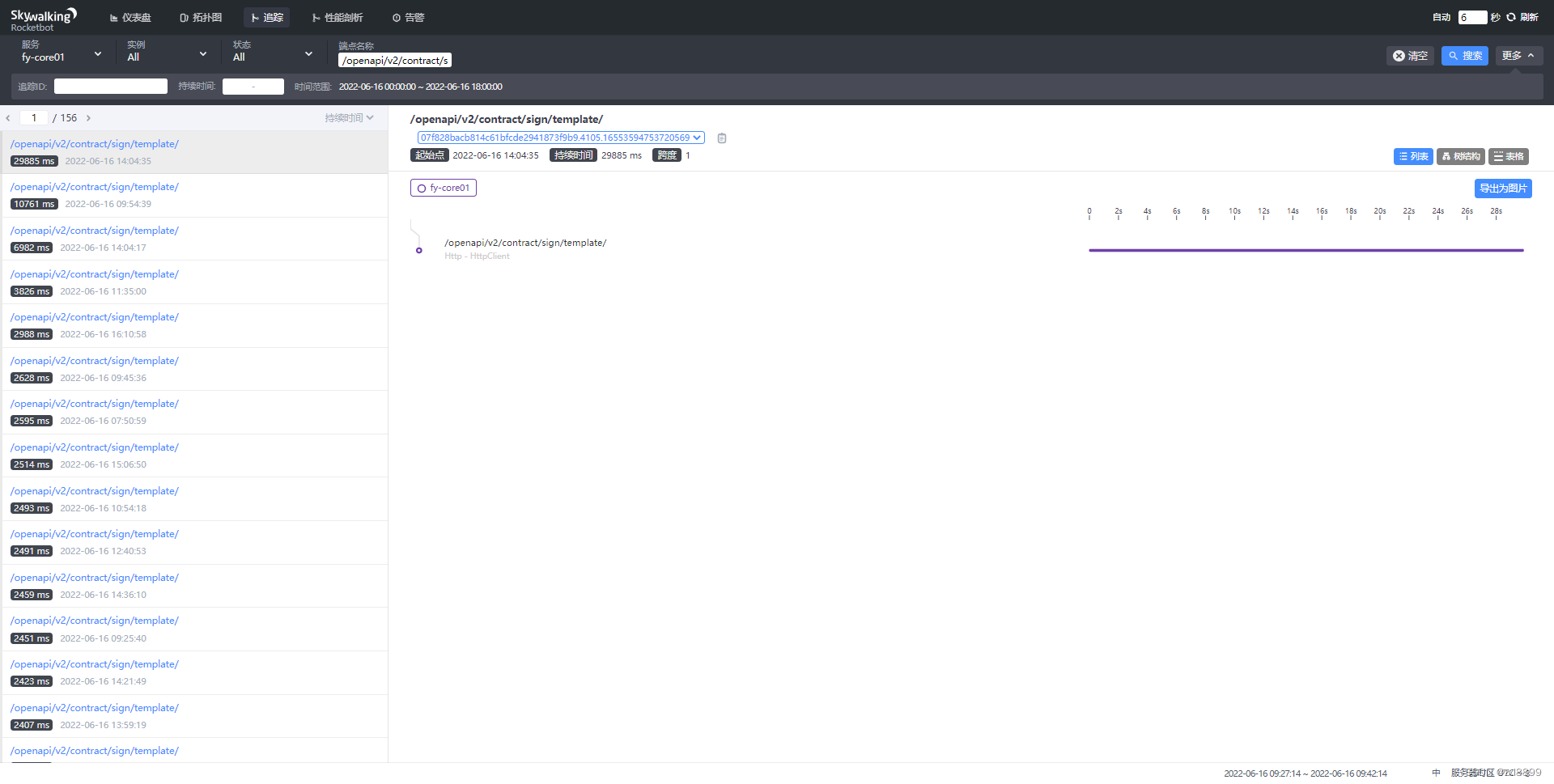
2.挨个查找某些耗时接口,发现并没有大并发,大多一小时只有几百次请求,而且大部分耗时接口只有一两次特别耗时的操作,其他都是正常耗时
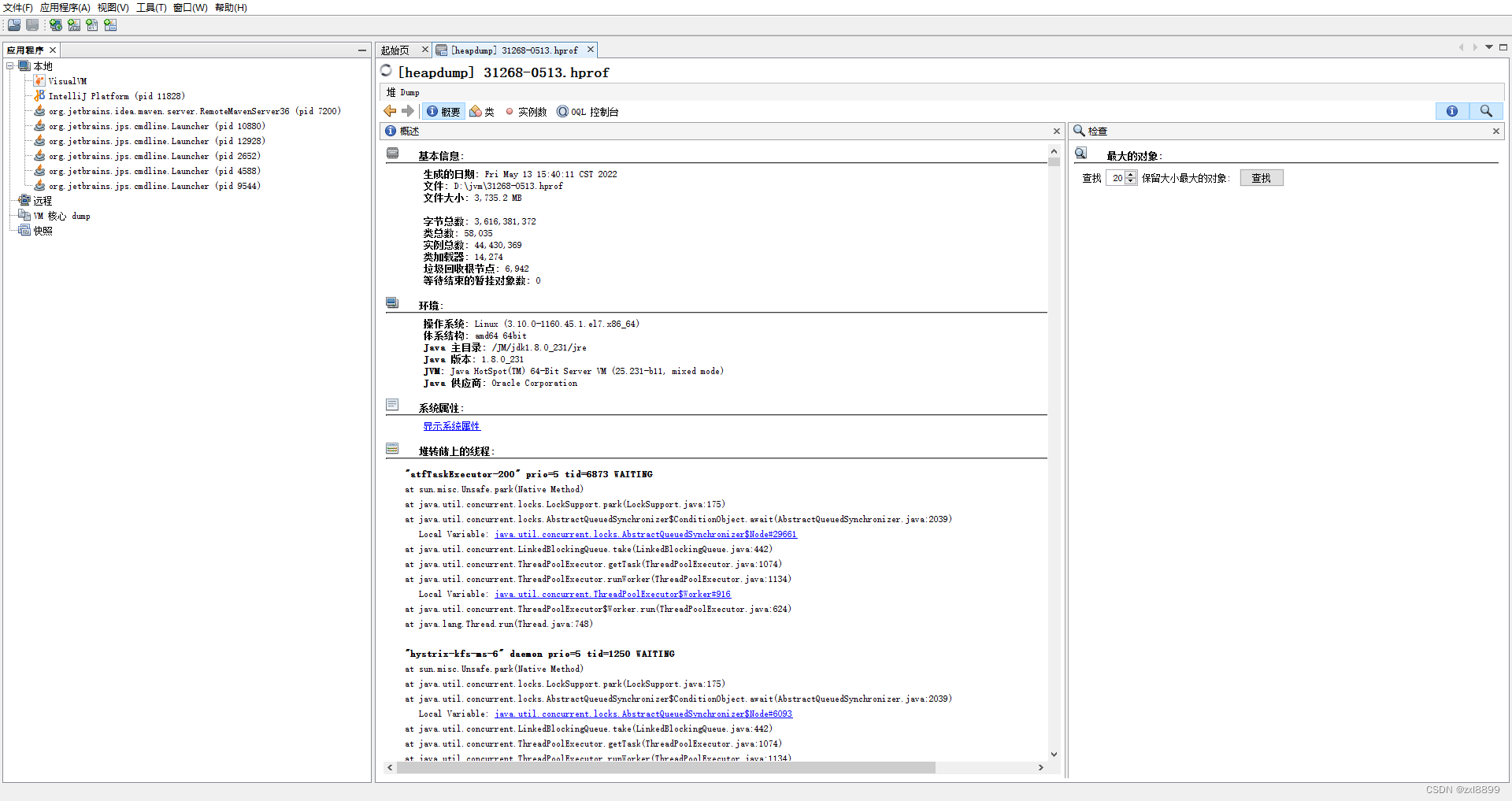
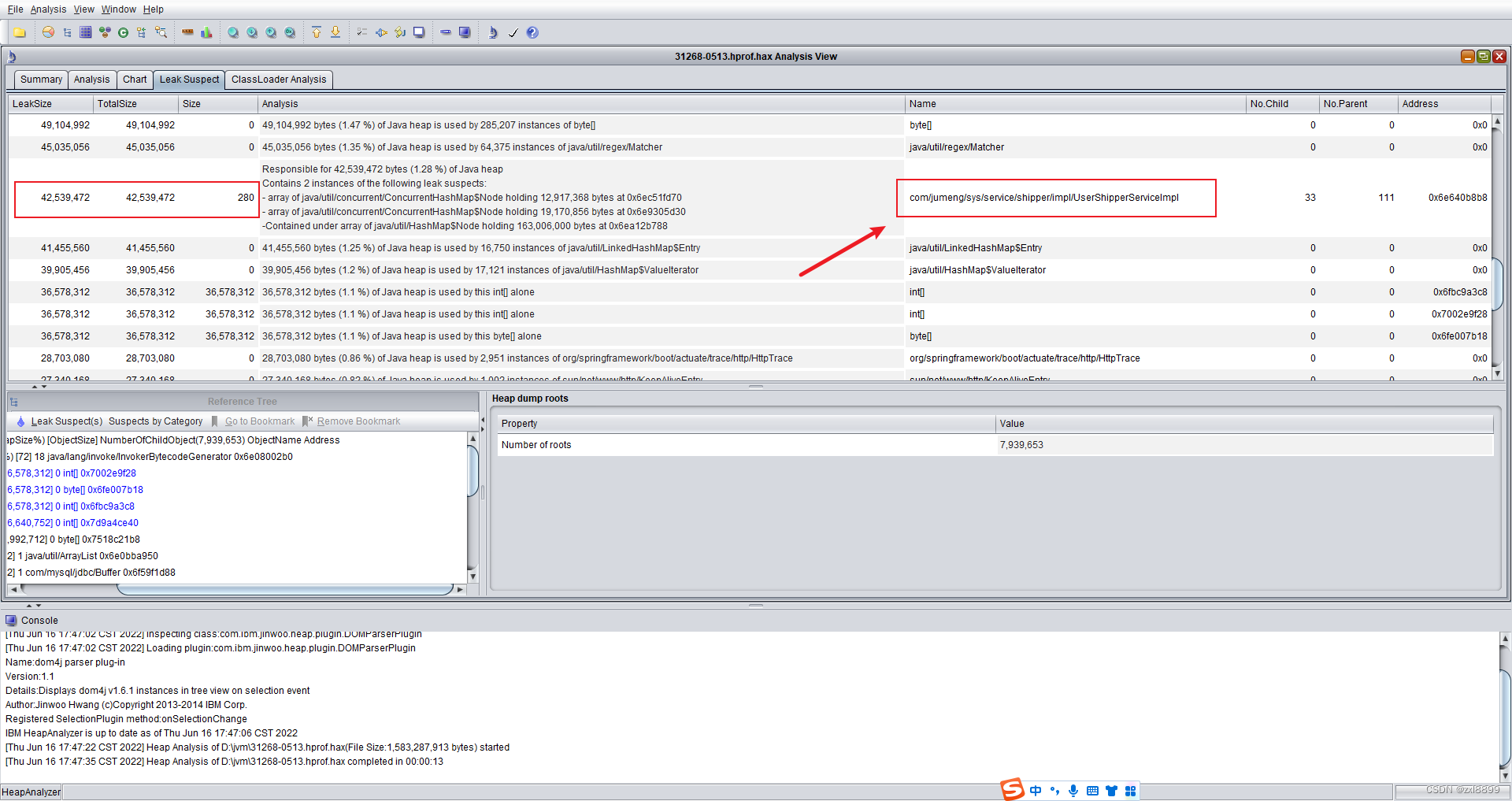
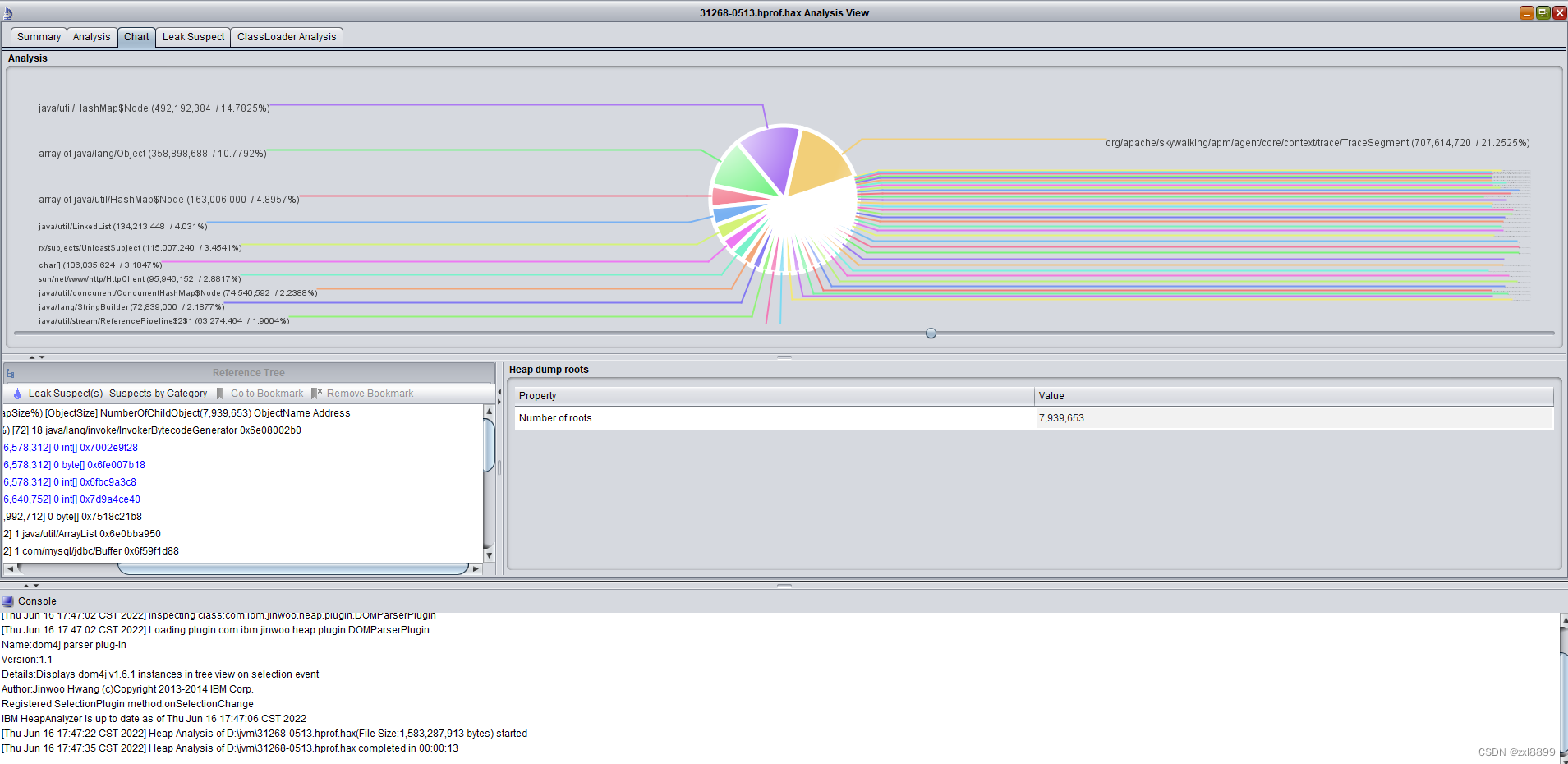
3. 通过jvisualvm 和 IBM heapanlyse 堆栈分析工具分析full gc 时的堆栈信息得到的结果,其中发现UserShipperServiceImpl上榜了,通过查找对应的代码,但是没有查到太有价值的信息
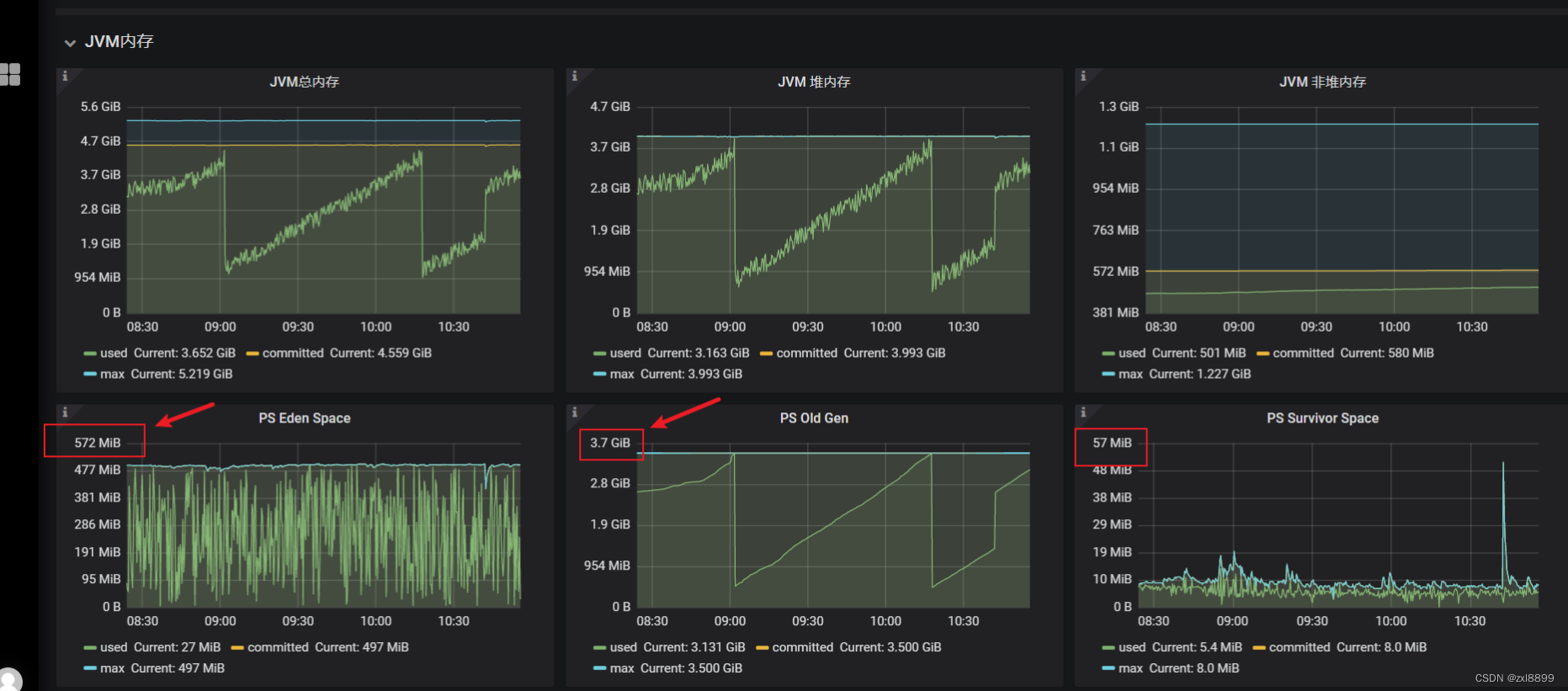
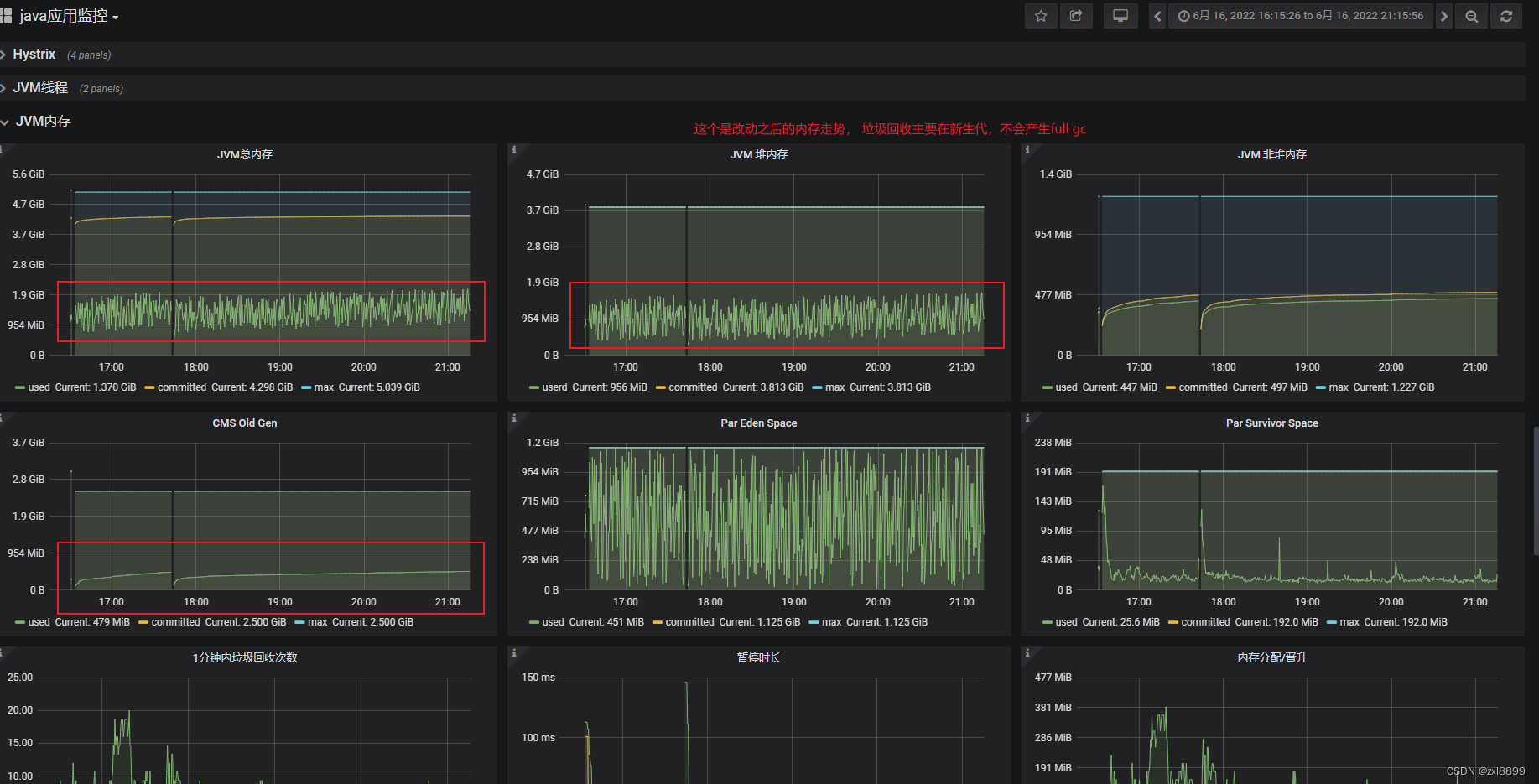
4. 然后再次查看grafana监控的一些内存指标,发现新生代和老年代内存设置的有点不太合理,新生代分配太小,对应的survivor区空间也小,再加上有些耗时的操作会导致一些耗时操作产生的对象经过多轮的miniorgc,直接到了老年代。甚至surivor区设置过小,会导致触发过半机制,直接把某次minorgc的对象全部移入老年代,导致老年代的对象越来越多,最终发生fullgc。 ps:以下是未调整之前的内存走势图
5.后来运维老师发了关于xxx项目 的jvm启动参数,以下是之前xxx项目的jvm启动参数,发现启动参数配置了很多cms和g1垃圾收集器的相关参数,但是实际上并没有开启cms和g1任何一个收集器,还是采用的jdk1.8默认的parallel收集器新生代和老年代的比例是1:4,eden区和survivor区的比例是 8:1:1,元空间大小是512m。针对这种情况,对启动参数作出了以下的调整 1. 修改了新生代的大小(1.5g=1536m) 2.调整了eden区和survivor区的比例 6:2:2 3. 启用了cms垃圾回收器 4.删除了g1相关的启动参数
原启动参数:
== -Xms4g -Xmx4g -XX:NewRatio=4 -XX:SurvivorRatio=8 -XX:MetaspaceSize=512m -XX:MaxMetaspaceSize=512m -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=70 -XX:+ExplicitGCInvokesConcurre
ntAndUnloadsClasses -XX:+CMSClassUnloadingEnabled -XX:+ParallelRefProcEnabled -XX:+CMSScavengeBeforeRemark -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/JM/fy-core -XX:MaxGCPauseMillis=400 -Xloggc:/JM/logs/fy-core/gc.log -Djxl.nogc=true ==
改动后的启动参数:
== -Xms4g -Xmx4g -Xmn1536M -XX:SurvivorRatio=6 -XX:MetaspaceSize=512m -XX:MaxMetaspaceSize=512m -XX:+UseConcMarkSweepGC -XX:+CMSParallelInitialMarkEnabled -XX:+CMSParallelRemarkEnabled
-XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=80 -XX:+ExplicitGCInvokesConcurre
ntAndUnloadsClasses -XX:+CMSClassUnloadingEnabled -XX:+CMSScavengeBeforeRemark -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/JM/fy-core -Xloggc:/JM/logs/fy-core/gc.log -Djxl.nogc=true ==
以下是改动前后的内存走势图
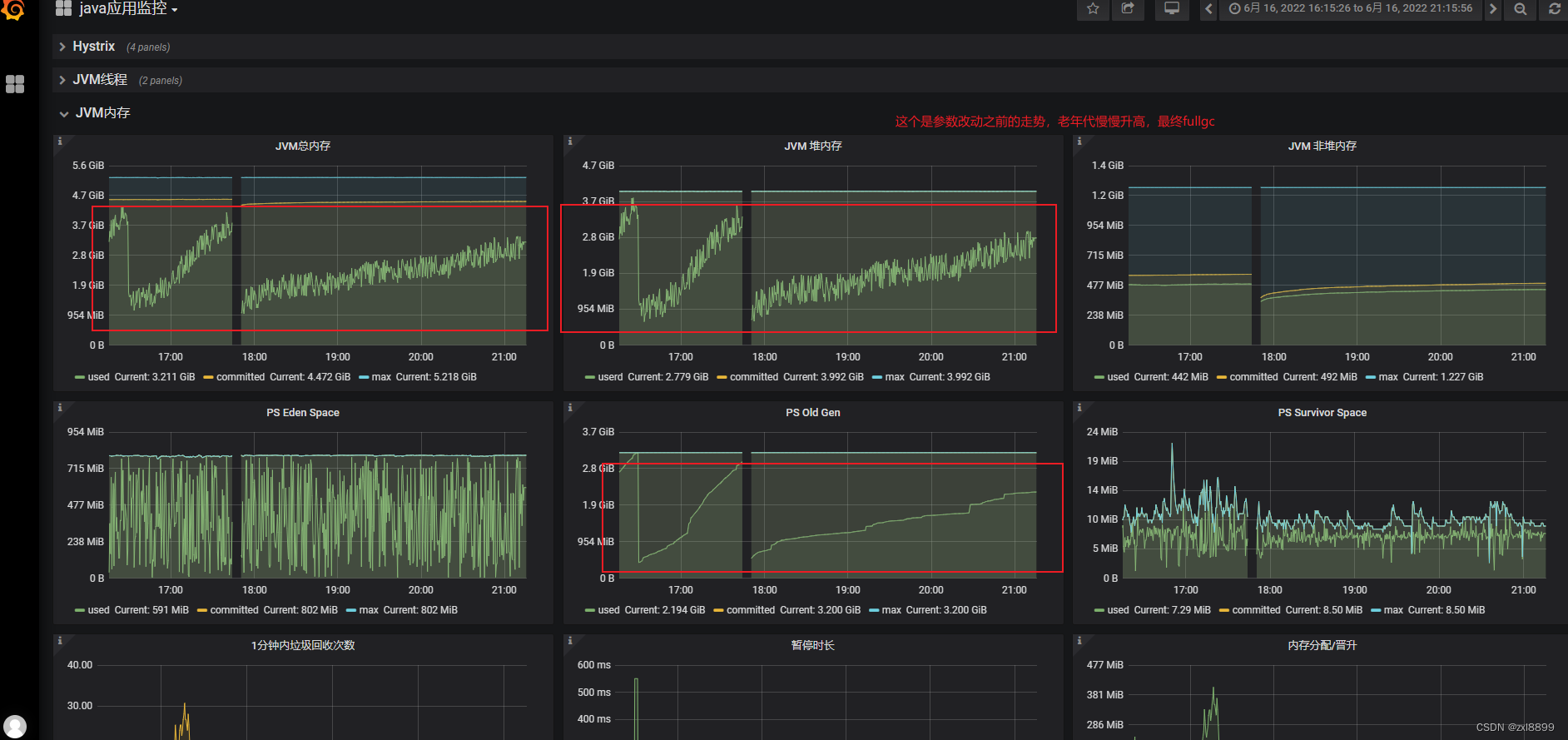
以下是改动后的gc频率以及gc时间
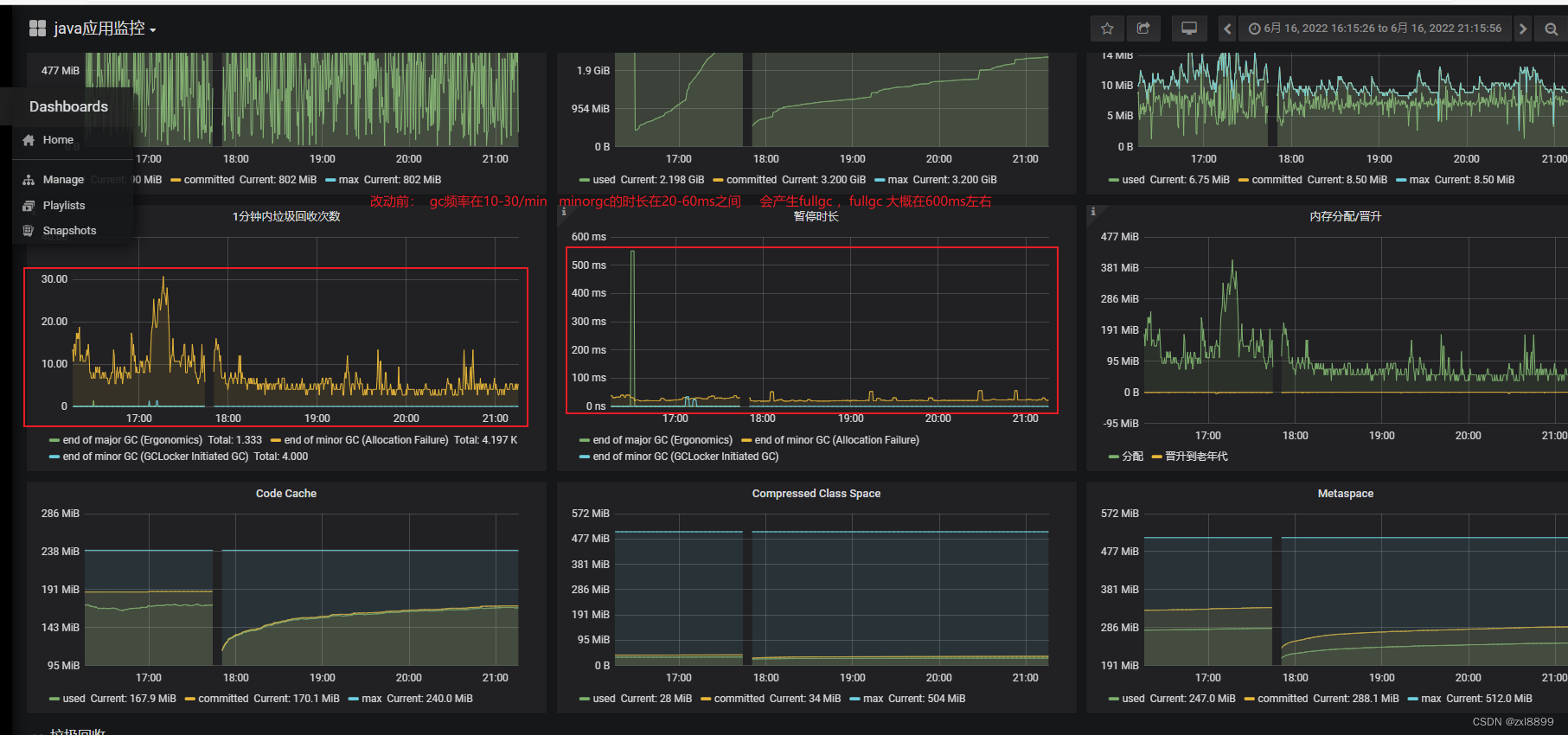
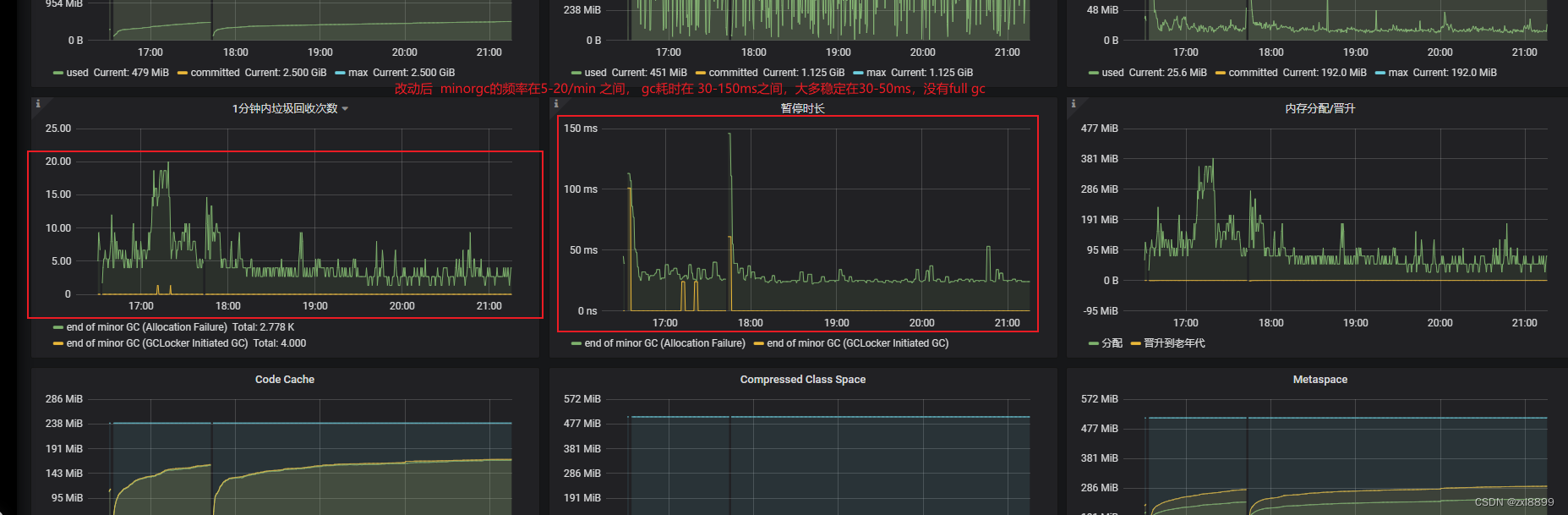
结论: 从监控图标来看,修改参数之后是可以达到清除full gc的目的,minor gc 的频率会变低 ,但是minorgc会略微增加,和之前没有什么偏差。如果之后再产生full gc 的话,cms 收集器也可以大量减少fullgc 的时长


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









