



 本文详细介绍了Flink计算框架,对比了自定义计算框架和Flink的优势,强调了Flink的状态管理和Checkpoint机制,以及流处理与批处理的区别。Flink支持有状态计算,提供丰富的连接器和State Backend,如RocksDB,用于数据的持久化。此外,文章还讨论了Flink的架构、任务调度规则和状态后端的选择,为理解Flink的实时计算能力提供了深入见解。
本文详细介绍了Flink计算框架,对比了自定义计算框架和Flink的优势,强调了Flink的状态管理和Checkpoint机制,以及流处理与批处理的区别。Flink支持有状态计算,提供丰富的连接器和State Backend,如RocksDB,用于数据的持久化。此外,文章还讨论了Flink的架构、任务调度规则和状态后端的选择,为理解Flink的实时计算能力提供了深入见解。
1.1 计算框架对比

1.1.1 自定义计算框架(灵活, 抽象度不够)
- 需要设计数据源的分片拉取策略, 数据计算的mapping shuffle reduce
- 需要选型计算中间结果存储
- 异常情况下的容错处理设计

1.1.2 Flink计算框架的特点和优势
- 有丰富的官方connector, sink; 也可以自定义
- Flink中提供了StateBackend来存储和管理状态数据, 支持有状态计算, 并且支持多种状态(RocksDB支持热数据存放内存, 冷数据存放文件)
- Flink中基于异步轻量级的分布式快照技术提供了Checkpoint容错机制, 状态数据全局统一快照处理, 可以基于保存的快照容错及保证exactly-once语义
- 支持事件时间(Event Time)概念,结合Watermark处理乱序数据
- 支持高度灵活的窗口(Window)操作 time、count、session
- 基于JVM实现独立的内存管理
1.1.3 大数据核心思想
- 分而治之
- 当数据量达到一定程度的规模时,普通的服务器很难短时间内去计算解决问题。所以需要多台廉价服务器分布式存储,并行计算去解决问题。
- 计算向数据移动
- 分布式环境下,网络的I/O是多机处理问题的速度瓶颈。那么数据的移动的时间成本很大。而计算程序基本很小。所以我们需要计算去向数据移动。尽量使用本地数据,减少网络I/O。
问题: 如果有一个1T的文本文件,仅有一台内存为百M的计算机。如何查询出这个文本文件中那条记录出现了两次。
- tips:单机计算机的计算瓶颈为磁盘I/O。假设读取速度为每秒300M。那么读取一次1T的文件为约1个小时。因为内存有限,无法将数据完全读取到1台机器上。
- 方法1:逐条便利对比。需要n次遍历这个文本去逐条比对。时间是指数级别的。
- 方法2:分而治之:先遍历一次文本。将每条数据取hash值模上10000的方法,将每条数据分别存储到不同的10000个文件中。再遍历这10000个文件,相当于遍历一遍源文件。这样只需要两次I/O,2个小时左右就能解决这个问题。
问题: 如果每天产生一个1T的文本文件, 多机器分布式计算真的块吗?
- tips:单台机子不需要分发。假设每秒100MB的网络分发速度分发至10000台机器, 光分发速度就需要3个小时。
- 30天的时候,数据来到了30T。单机遍历两次将近30个小时。而多机器每天需要3个小时去分发数据。
到最后,每台机器上也就将近3000MB的数据。遍历时间10秒(不考虑倾斜)。
1.2 大数据计算框架对比
1.2.1 Storm Spark Flink对比
- Storm
- 仅支持流处理
- 目前活跃度不如spark flink
- Spark
- 设计为批处理大数据计算引擎
- Spark Streaming 把一段时间传输进来的数据合并在一起当做一个微批, 再去交给Spark去处理, 流是批的特例理念
- Spark MLlib 机器学习类库相对成熟
- Flink
- 按照流处理计算设计的大数据计算引擎
- 主要场景就是流数据(DataStream), 即可以逐条处理, 也可以定义数据流的边界(Window)攒微批
- 批数据(DataSet): 批数据是流数据的一个极限特例理念
- 有状态计算
1.2.2 流处理与批处理
- 流处理(流式计算/实时计算): 无界流(动态数据), 实时处理
- 批处理(批量计算): 有界流(静态数据), 一般为定时任务调度, 每次调度会一次性完成处理, 高延迟

无界流(Unbounded streams)
- 有定义流的开始,但没有定义流的结束。它们会无休止地产生数据。
- 无界流的数据必须持续处理,即数据被摄取后需要立刻处理。不能等到所有数据都到达再处理,因为输入是无限的,在任何时候输入都不会完成。
- 处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果的完整性。
有界流(Bounded streams)
- 有定义流的开始,也有定义流的结束。
- 有界流可以在摄取所有数据后再进行计算。
- 有界流所有数据可以被排序,所以并不需要有序摄取。
- 有界流处理通常被称为批处理。
1.2.2 有状态计算(stateful computations)

有状态的计算
-
每次进行数据计算的时候基于之前数据的计算结果(状态)做计算,并且每次计算结果都会保存到存储介质中,计算关联上下文context
-
如: 计算1天内累计数据, 基于有状态的计算,将当日累计值存储在状态中, 当前数据与状态历史值进行累计, 再更新状态
无状态的计算
- 每次进行数据计算只是考虑当前数据,不会使用之前数据的计算结果
1.3 Flink架构
-
Flink基本架构
-
Flink系统架构中包含了两个角色,分别是JobManager和TaskManager,是一个典型的Master-Slave架构(主从设备模式)。JobManager相当于是Master,TaskManager相当于是Slave,
-
核心思想是基于分而治之的思想,将一个原始任务分解为若干个语义等同的子任务,并由专门的工作者线程来并行执行这些任务,原始任务的结果是通过整合各个子任务的处理结果形成的.
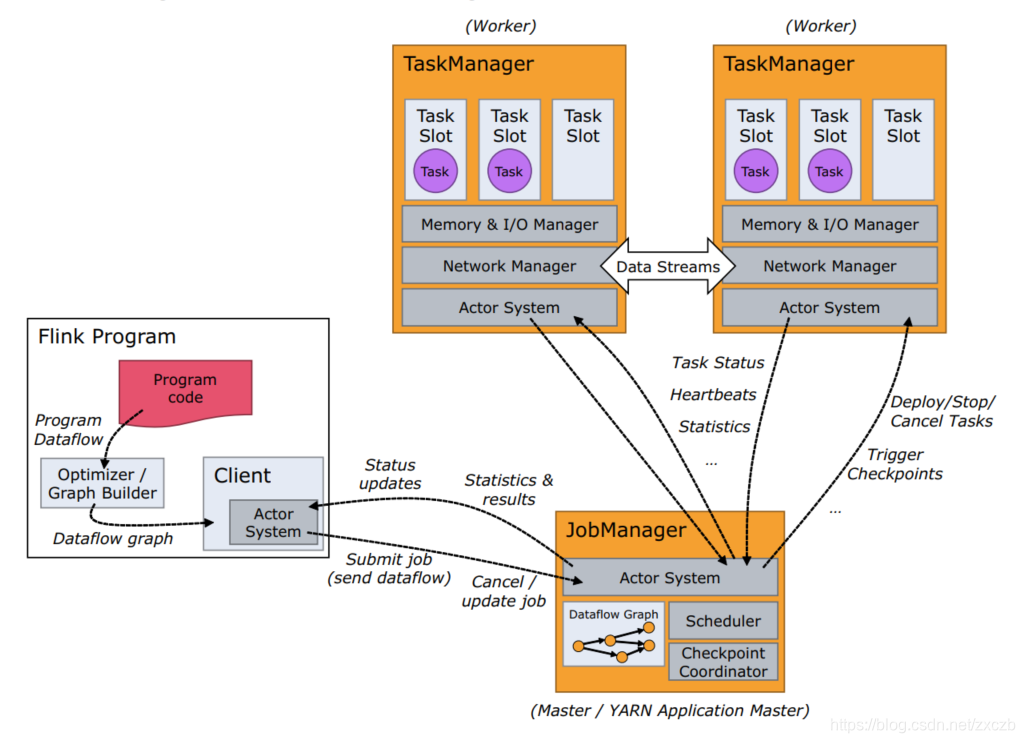
1.3.1 JobManager(JVM进程)作用
- JobManager负责整个集群的资源管理与任务管理,在一个集群中只能由一个正在工作(active)的JobManager,如果HA集群,那么其他JobManager一定是standby状态
- (1)资源调度
- 集群启动,TaskManager会将当前节点的资源信息注册给JobManager,所有TaskManager全部注册完毕,集群启动成功,此时JobManager就掌握整个集群的资源情况
- client提交Application给JobManager,JobManager会根据集群中的资源情况,
为当前的Application分配TaskSlot资源 - (2)任务调度
- 根据各个TaskManager节点上的资源分发task到TaskSlot中运行Job执行过程中,JobManager会根据设置的触发策略触发checkpoint,通知TaskManager开始checkpoint
- 任务执行完毕,JobManager会将Job执行的信息反馈给client,并且释放TaskManager资源
- 1.3.2 TaskManager(JVM进程)作用
- 负责当前节点上的任务运行及当前节点上的资源管理,TaskManager资源通过TaskSlot进行了划分,每个TaskSlot代表的是一份固定资源。例如,具有三个 slots 的 TaskManager 会将其管理的内存资源分成三等份给每个 slot。
- 划分资源意味着 subtask 之间不会竞争内存资源,但是也意味着它们只拥有固定的资源。
- 注意这里并没有 CPU 隔离,当前 slots 之间只是划分任务的内存资源
- 负责TaskManager之间的数据交换
1.3.3 client客户端
- 负责将当前的任务提交给JobManager,提交任务的常用方式:命令提交、web页面提交。获取任务的执行信息
1.4 Flink生命周期
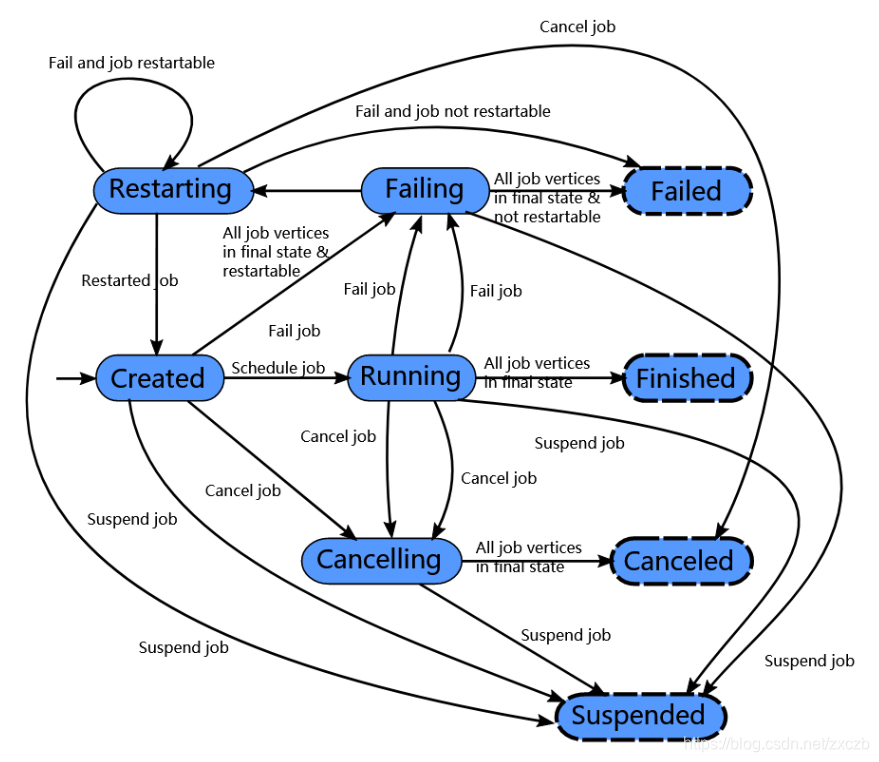
- Flink 作业刚开始会处于 created 状态,然后切换到 running 状态。
- 当所有任务都执行完之后会切换到 finished 状态。
- 如果遇到失败的话,作业首先切换到 failing 状态以便取消所有正在运行的 task。如果所有 job 节点都到达最终状态并且 job 无法重启, 那么 job 进入 failed 状态。如果作业可以重启,那么就会进入到 restarting 状态,当作业彻底重启之后会进入到 created 状态。
- 如果用户取消了 job 话,它会进入到 cancelling 状态,并取消所有正在运行的 task。当所有正在运行的 task 进入到最终状态的时候,job 进入 cancelled 状态。
- Finished、canceled 和 failed 会导致全局的终结状态,并且触发作业的清理。
- suspended(暂停)状态只是一个局部的终结。局部的终结意味着作业的执行已经被对应的 JobManager 终结,但是集群中另外的 JobManager 依然可以从高可用存储里获取作业信息并重启。因此一个处于 suspended 状态的作业不会被彻底清理掉。
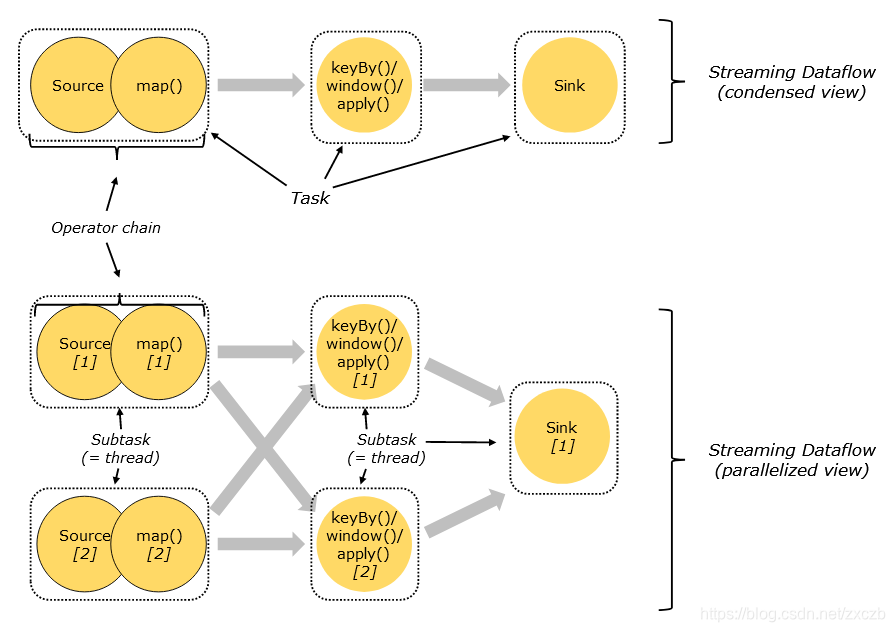
1.5 Flink算子链(operator chain)
1.5.1 算子链简介
- 为了更高效地分布式执行,Flink会尽可能地将operator的subtask链接(chain)在一起形成task。每个task在一个线程中执行。
- 将operators链接成task是非常有效的优化:它能减少线程之间的切换,减少消息的序列化/反序列化,减少数据在缓冲区的交换,减少延迟的同时提高整体的吞吐量
- 下图中样例数据流用 5 个 subtask 执行,因此有 5 个并行线程(Thread, 2SourceMap + 2KeyBy + Sink), 分布在2个Slot(Parallelism)中。
1.5.2 算子链分割依据
-
Flink算子链合并分割依据: Shuffle(分区), 当前分区的元素是否能 一对一分发至下一个任意分区
-
可以合并的分区策略:
-
分区策略为 forward , 一对一的数据分发,map、flatMap、process、filter 等都是这种分区策略
-
导致分割的分区策略:
-
shuffle 分区元素随机均匀分发到下游分区,网络开销比较大
-
rebalance 轮询分区元素,均匀的将元素分发到下游分区,下游每个分区的数据比较均匀,在发生数据倾斜时非常有用,网络开销比较大
-
rescale 减少分区 防止发生大量的网络传输 不会发生全量的重分区
-
broadcast 上游中每一个元素内容广播到下游每一个分区中(需要使用映射表、并且映射表会经常发生变动的场景)
-
global 上游分区的数据只分发给下游的第一个分区(并行度降为1)
-
keyBy 根据上游分区元素的Hash值与下游分区数取模计算出,将当前元素分发到下游哪一个分区
-
PartitionCustom 自定义的分区器,来决定元素是如何从上游分区分发到下游分区
1.5.3 算子链样例
1.5.3.1 仅包含forward 分区策略
env.addSource(…)
.process(…)
.addSink(…);
1.5.3.2 包含2次 keyBy (orderId: 防重, userId: KeyState)
env.addSource(…)
.filter(…)
.keyBy(orderId…)
.process(…, …)
.keyBy(userId…)
.map(…)
.addSink(…);
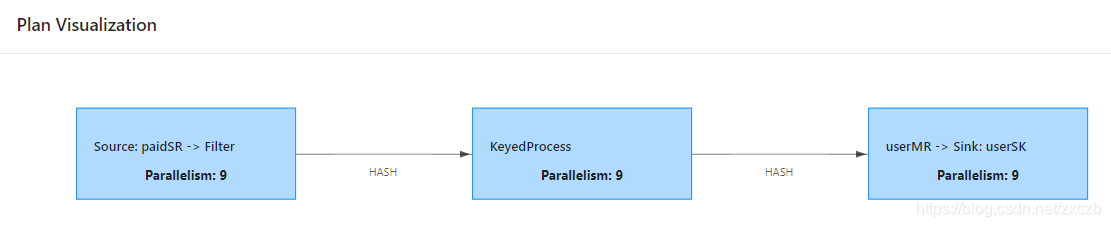
1.5.3.3 注释掉一次 KeyBy
env.addSource(…)
.filter(…)
//.keyBy(orderId…)
//.process(…, …)
.keyBy(userId…)
.map(…)
.addSink(…);
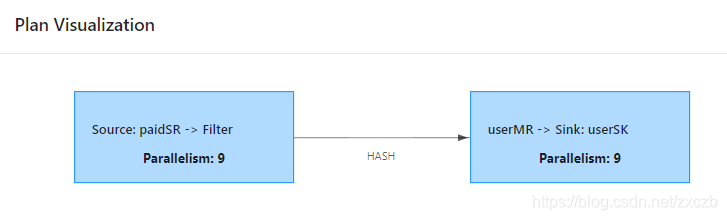
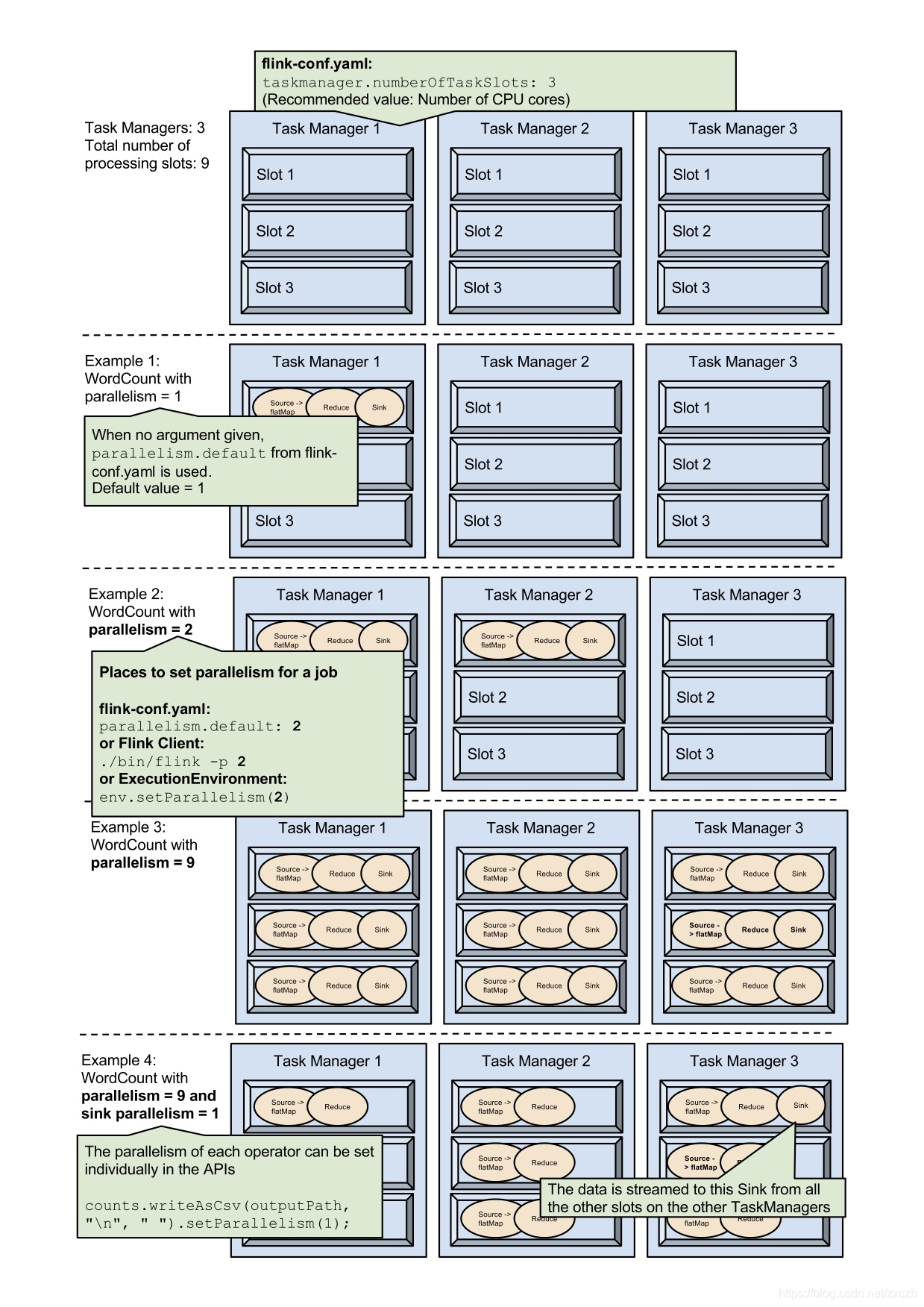
1.5.4 Flink任务调度规则
- 调度原则:
- 相同Task下不同的subtask分到同一个TaskSlot,提高数据传输效率
- 不同Task下相同的subtask不会分到同一个TaskSlot,充分利用集群资
1.6 Flink State Backends(状态后端)
1.6.1 状态简介
- Flink是一个有状态的流式计算引擎,所以会将中间计算结果(状态)进行保存,默认保存到TaskManager的堆内存中,但是当task挂掉,那么这个task所对应的状态都会被清空,造成了数据丢失,无法保证结果的正确性,哪怕想要得到正确结果,所有数据都要重新计算一遍,效率很低。
- 想要保证At -leastonce和Exactly-once,需要把数据状态持久化到更安全的存储介质中,Flink提供了堆内内存、堆外内存、HDFS、RocksDB等存储介质
1.6.2 可用的 State Backends
Flink 内置了以下这些开箱即用的 state backends :
- MemoryStateBackend
- FsStateBackend
- RocksDBStateBackend
- 如果不设置,默认使用 MemoryStateBackend。
1.6.2.1 MemoryStateBackend
在 MemoryStateBackend 内部,数据以 Java 对象的形式存储在堆中。 Key/value 形式的状态和窗口算子持有存储着状态值、触发器的 hash table。
MemoryStateBackend 适用场景:
- 本地开发和调试。
- 状态很小的 Job,例如:由每次只处理一条记录的函数(Map、FlatMap、Filter 等)构成的 Job。Kafka Consumer 仅仅需要非常小的状态。
1.6.2.2 FsStateBackend
FsStateBackend 需要配置一个文件系统的 URL(类型、地址、路径),例如:”hdfs://namenode:40010/flink/checkpoints” 或 “file:///data/flink/checkpoints”。
FsStateBackend 将正在运行中的状态数据保存在 TaskManager 的内存中。CheckPoint 时,将状态快照写入到配置的文件系统目录中。少量的元数据信息存储到 JobManager 的内存中(高可用模式下,将其写入到 CheckPoint 的元数据文件中)。
FsStateBackend 适用场景:
- 状态比较大、窗口比较长、key/value 状态比较大的 Job。
- 所有高可用的场景。
1.6.2.3 RocksDBStateBackend
RocksDBStateBackend 需要配置一个文件系统的 URL (类型、地址、路径),例如:”hdfs://namenode:40010/flink/checkpoints” 或 “file:///data/flink/checkpoints”。
RocksDBStateBackend仅会存储正在进行计算的热数据(读缓存), 其他的状态数据将保存在 RocksDB 数据库中,RocksDB 数据库默认将数据存储在 TaskManager 的数据目录。
CheckPoint 时,整个 RocksDB 数据库被 checkpoint 到配置的文件系统目录中。少量的元数据信息存储到 JobManager 的内存中(高可用模式下,将其存储到 CheckPoint 的元数据文件中)。
RocksDBStateBackend 的适用场景:
- 状态非常大、窗口非常长、key/value 状态非常大的 Job(最大支持K/V 2^31 字节)。
- 所有高可用的场景。
- 支持增量快照。
- 支持状态的TTL。
1.6.2.4 设置StateBackend内存
可以通过以下两种范式指定托管内存的大小:
- 通过 taskmanager.memory.managed.size 明确指定其大小。
- 通过 taskmanager.memory.managed.fraction 指定在Flink 总内存中的占比。
1.6.2.5 取舍
- RocksDBStateBackend和MemoryStateBackend相比性能就会较弱一些。
- RocksDB克服了State受内存限制的缺点,同时又能够持久化到远端文件系统中,推荐在生产中使用
- 阿里云产品采用GeminiStateBackend, 性能测试情况优于RocksDB
- Memory RocksDB Gemini性能测试
1.6.3 状态类型
Flink中状态分为两种类型:
1.6.3.1 Keyed State
- 基于KeyedStream上的状态,这个状态是跟特定的Key绑定,KeyedStream流上的每一个Key都对应一个State,每一个Operator可以启动多个Thread处理,但是相同Key的数据只能由同一个Thread处理
- 因此一个Keyed状态只能存在于某一个Thread中,一个Thread会有多个Keyedstate
1.6.3.2 Non-Keyed State(Operator State)
- Operator State与Key无关,而是与Operator绑定,整个Operator只对应一个State。
- 比如:Flink中的Kafka Connector就使用了Operator State,它会在每个Connector实例中,保存该实例消费Topic的所有(partition, offset)映射
1.6.4 常用的Keyed State
Flink针对Keyed State提供了以下可以保存State的数据结构
-
ValueState:
-
类型为T的单值状态,这个状态与对应的Key绑定,最简单的状态,通过update更新值,通过value获取状态值
-
ListState:
-
Key上的状态值为一个列表,这个列表可以通过add方法往列表中添加值,也可以通过get()方法返回一个Iterable来遍历状态值
-
ReducingState:
-
每次调用add()方法添加值的时候,会调用用户传入的reduceFunction,最后合并到一个单一的状态值
-
MapState<UK, UV>:
-
状态值为一个Map,用户通过put或putAll方法添加元素,get(key)通过指定的key获取value,使用entries()、keys()、values()检索
-
AggregatingState <IN, OUT> :
-
保留一个单值,表示添加到状态的所有值的聚合。和ReducingState 相反的是, 聚合类型可能与添加到状态的元素的类型不同。使用 add(IN) 添加的元素会调用用户指定的 AggregateFunction 进行聚合
1.7 Checkpoint(快照)
1.7.1 定义
-
快照 – 是 Flink 作业状态全局一致镜像的通用术语。快照包括指向每个数据源的指针(例如,到文件或 Kafka 分区的偏移量)以及每个作业的有状态运算符的状态副本,该状态副本是处理了 sources 偏移位置之前所有的事件后而生成的状态。
-
Checkpoint – 一种由 Flink 自动执行的快照,其目的是能够从故障中恢复。Checkpoints 可以是增量的,并为快速恢复进行了优化。
-
外部化的 Checkpoint – 通常 checkpoints 不会被用户操纵。Flink 只保留作业运行时的最近的 n 个 checkpoints(n 可配置),并在作业取消时删除它们。但你可以将它们配置为保留,在这种情况下,你可以手动从中恢复。
-
Savepoint – 用户出于某种操作目的(例如有状态的重新部署/升级/缩放操作)手动(或 API 调用)触发的快照。Savepoints 始终是完整的,并且已针对操作灵活性进行了优化。
1.7.2 原理
-
Flink 使用 Chandy-Lamport algorithm 算法的一种变体,称为异步 barrier 快照(asynchronous barrier snapshotting)。
-
checkpoint coordinator(job manager 的一部分)指示 task manager 开始 checkpoint 。它会让所有 sources 记录它们的偏移量,并将编号的 checkpoint barriers 插入到它们的流中。这些 barriers 流经 job graph,标注每个 checkpoint 前后的流部分。
-
Checkpointn 将包含每个 operator 的 state,这些 state 是对应的 operator 消费了严格在 checkpoint barrier n 之前的所有事件,并且不包含在此(checkpoint barrier n)后的任何事件后而生成的状态。
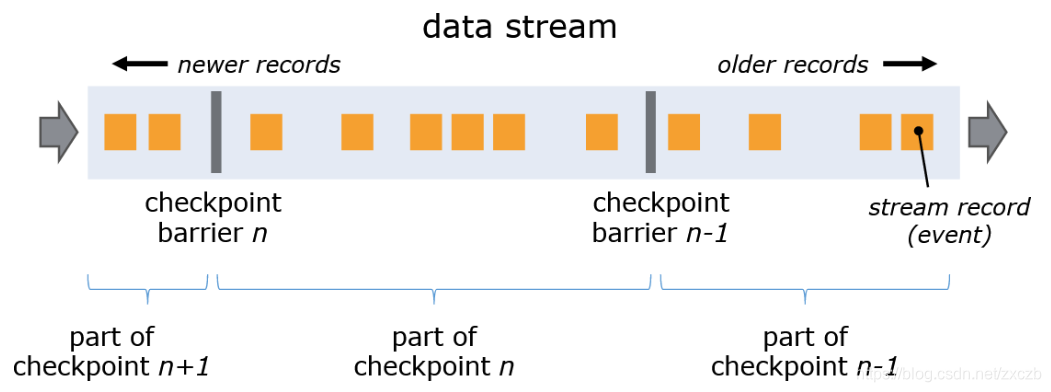
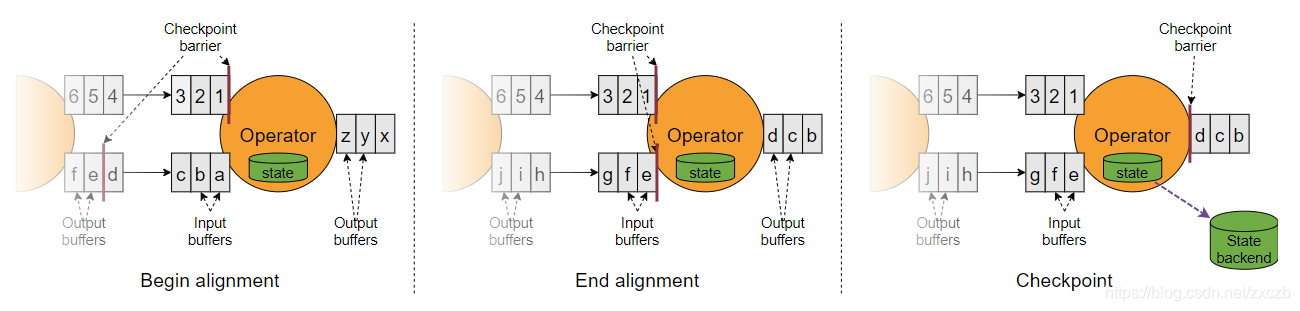
多输入数据流要想保证精确一次, 需要Stream Aligning
- 当 job graph 中的每个 operator 接收到 barriers 时,它就会记录下其状态。拥有两个输入流的 Operators(例如 CoProcessFunction)会执行 barrier 对齐(barrier alignment) 以便当前快照能够包含消费两个输入流 barrier 之前(但不超过)的所有 events 而产生的状态。
-
- Checkpoint Barrier n 标记为1和e的offset
-
- 开始对齐, offset=1的stream开始等待标记为offset=e的stream读取元素至标记处
-
- 当所有stream均到达标记处后, 完成 barrier 对齐, 开始 checkpoint
-
- 源码查看 CheckpointBarrierHandler , CheckpointBarrierTracker实现非阻塞至少一次, CheckpointBarrierAligner(被删?) 阻塞精确一次
- 源码查看 CheckpointBarrierHandler , CheckpointBarrierTracker实现非阻塞至少一次, CheckpointBarrierAligner(被删?) 阻塞精确一次
Flink 的 state backends 利用写时复制(copy-on-write)机制允许当异步生成旧版本的状态快照时,能够不受影响地继续流处理。只有当快照被持久保存后,这些旧版本的状态才会被当做垃圾回收
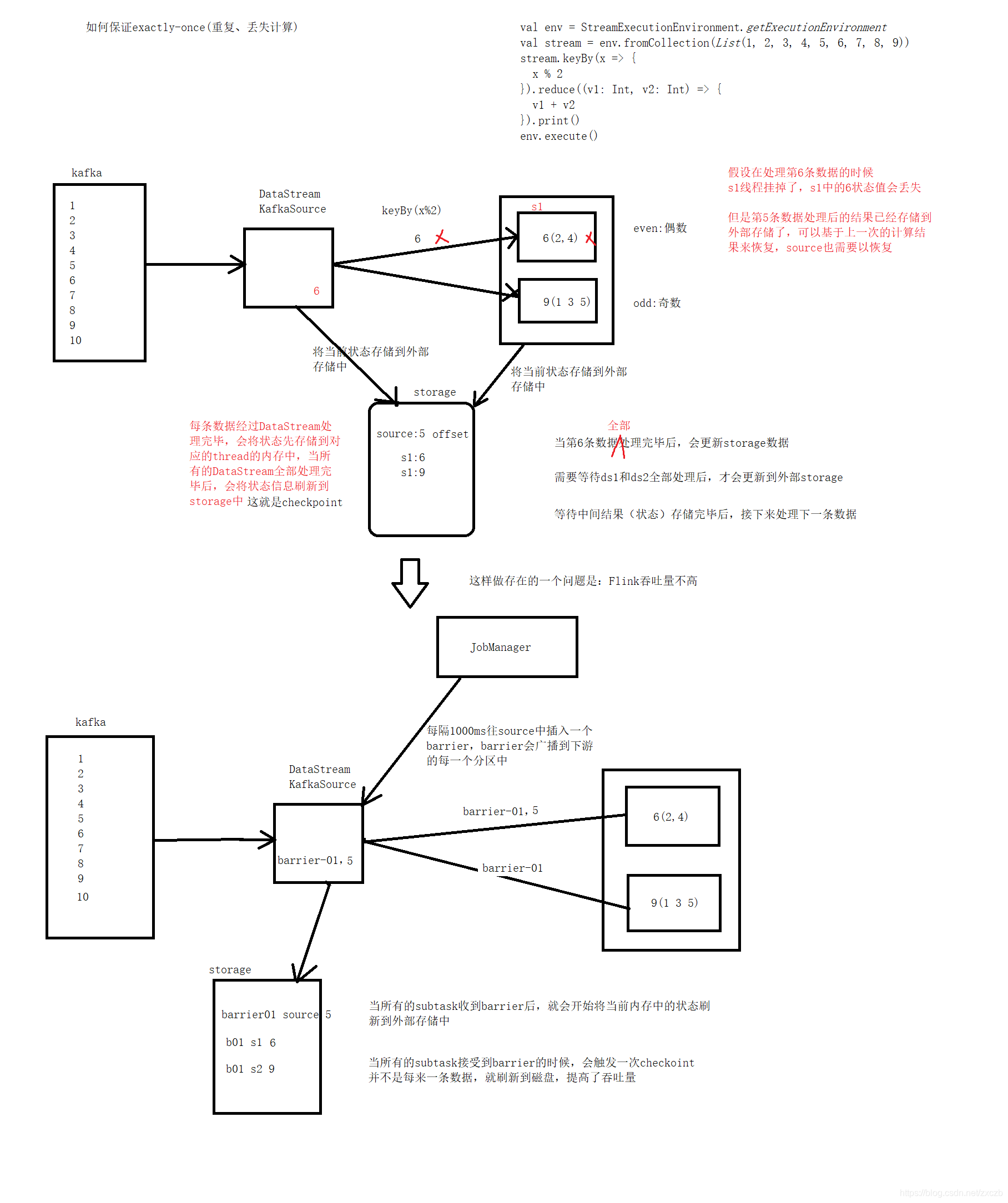
1.7.2.1 确保精确一次(exactly once)
当流处理应用程序发生错误的时候,结果可能会产生丢失或者重复。Flink 根据你为应用程序和集群的配置,可以产生以下结果:
- Flink 不会从快照中进行恢复(at most once)
- 没有任何丢失,但是你可能会得到重复冗余的结果(at least once)
- 没有丢失或冗余重复(exactly once)
Flink 通过回退和重新发送 source 数据流从故障中恢复,当理想情况被描述为精确一次时,这并不意味着每个事件都将被精确一次处理。相反,这意味着每一个事件都会影响 Flink 管理的状态精确一次。
Barrier 只有在需要提供精确一次的语义保证时需要进行barrier 对齐(Barrier alignment)。如果不需要这种语义,可以通过配置 CheckpointingMode.AT_LEAST_ONCE 关闭 Barrier 对齐来提高性能。
1.7.2.2 端到端精确一次
为了实现端到端的精确一次,以便 sources 中的每个事件都仅精确一次对 sinks 生效,必须满足以下条件:
- 你的 sources 必须是可重放的
- 你的 sinks 必须是事务性的(或幂等的)
1.7.2.3 exactly-ance和at-least-once语义选择
-
选择exactly-once语义保证整个应用内端到端的数据一致性,这种情况比较适合于数据要求比较高,不允许出现丢数据或者数据重复,与此同时,Flink的性能也相对较弱
-
at-least-once语义更适合于时廷和吞吐量要求非常高但对数据的一致性要求不高的场景。
-
如下通过setCheckpointingMode()方法来设定语义模式,默认情况下使用的是exactly-once模式
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
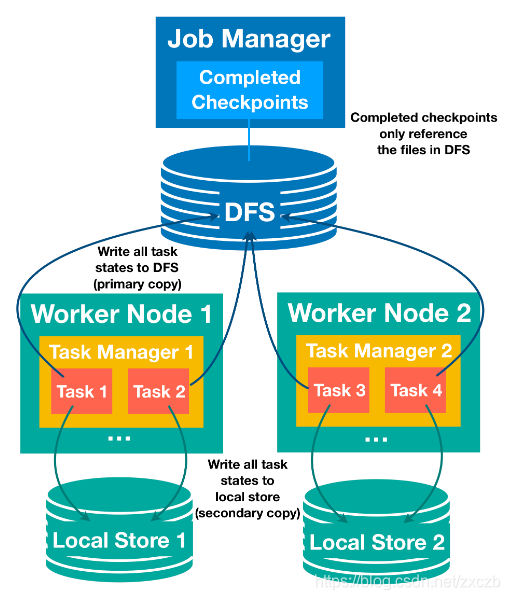
1.7.3 本地恢复策略
-
任务本地状态恢复正是针对这个恢复时间长的问题,对于每个检查点,每个任务不仅要将任务状态写入分布式存储(主存储),还要将状态快照的辅助副本保存在任务本地的存储中(例如,在本地磁盘或内存中)。
-
因为本地存储不能确保节点故障下的持久性,也不能为其他节点提供重新分发状态的访问,所以此功能仍然需要主副本。
-
但是,对于每个可以重新安排到上一个位置进行恢复的任务,我们可以从辅助本地副本恢复状态,并避免远程读取状态的开销。有效地缩短恢复时间。

















 1419
1419

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









