



 本文详细描述了MapReduce处理流程中的map、shuffle和reduce阶段,包括数据读取、分区策略(如HashPartitioner)、以及三次主要的I/O操作,重点讲解了如何在内存溢出时优化磁盘存储和数据传输过程。
本文详细描述了MapReduce处理流程中的map、shuffle和reduce阶段,包括数据读取、分区策略(如HashPartitioner)、以及三次主要的I/O操作,重点讲解了如何在内存溢出时优化磁盘存储和数据传输过程。
MR处理流程:
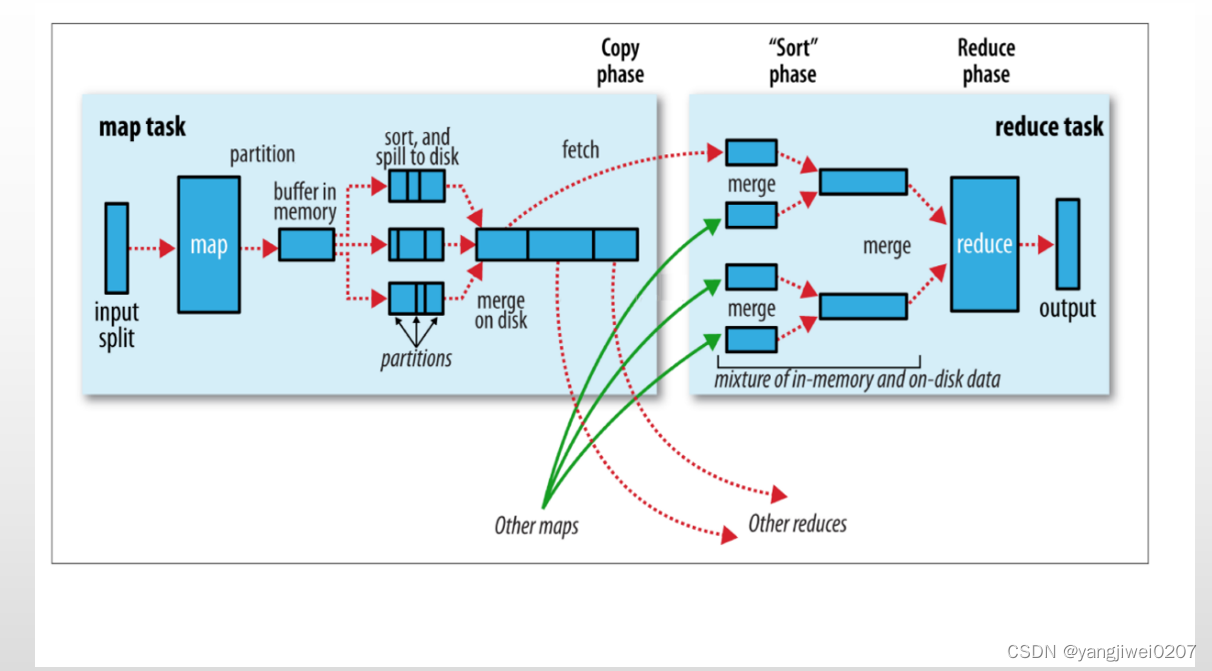
map阶段:
按行读取文件,将读取的文件缓存到缓冲区内,当文件大小达到了80%的溢出比,则将缓冲的文件写入磁盘。当磁盘内数据多了的时候,将文件合并成一整个块,完成读数据。
※map阶段※默认是不需要分区的,需不需要分区要看后续有几个reducetask,当reducetask>=2的时候,map阶段就需要针对自己的输出数据进行分区。
所谓分区就是根据什么规则将数据提交给哪一个maptask及逆行处理
<默认的分区规则:HashPartitioner> key.hashcode % reducetask个数=余数(分区编号)
shuffle阶段:
map阶段的缓冲区到reduce阶段的数据merge都属于shuffle阶段,shuffle阶段会将map阶段存到磁盘的数据抽取出来并进行分区处理
reduce阶段:
reduce阶段会将shuffle阶段拉到分区的数据进行merge
过程I/O:
mapreduce阶段总共涉及三次I/O:
第一次:map阶段,将数据切分通过缓冲区缓存到磁盘
第二次:shuffle阶段(处理map与reduce中间流程的数据),将map阶段缓存到磁盘内的数据抽取到reduce阶段的分区内
第三次:reduce阶段将shuffle阶段抽取并处理好的数据merge,并写入磁盘


















 1566
1566

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











