







1. 概述
用来将虚拟地址空间映射到物理地址空间的数据结构称为页表。
实现两个地址空间的关联最容易的方法是使用数组,对虚拟地址空间中的每一页,都分配一个数组项。该数组项指向与之关联的页帧,但有一个问题。例如,IA-32体系结构使用4KB页,在虚拟地址空间为4GB的前提下,则需要包含100万项的数组。在64位体系结构上,情况会更糟糕。每个进程都需要自身的页表,因此系统的所有空间都用来保存页表,也就是说这个方法是不切实际的。
1.1 多级分页
因为虚拟地址空间的大部分区域都没有使用,因而也没有关联到页帧,那么就可以使用功能相同但内存用量少得多的模型:多级分页。
为了减少页表的大小并允许忽略未使用的区域,计算机体系结构的设计会将虚拟地址划分为多个部分,如图所示。
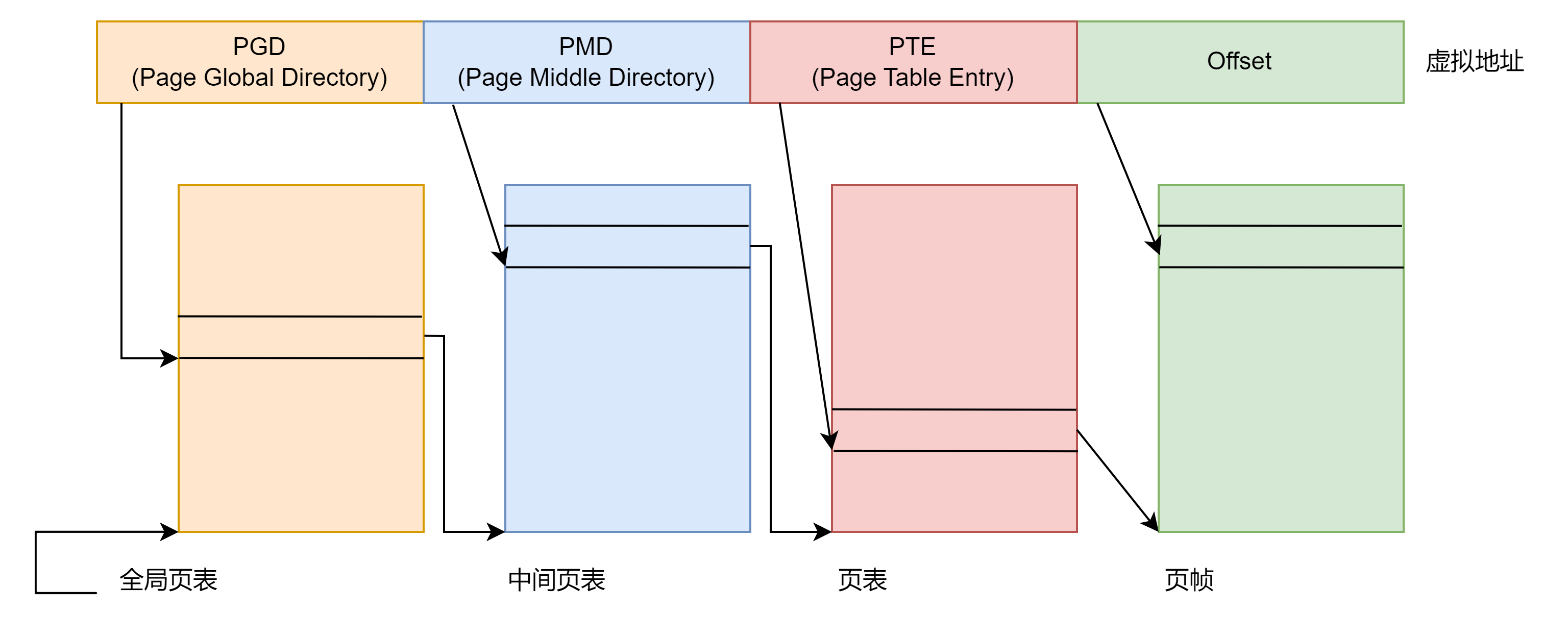
上图为一个简化的3级页表示例(Linux采用4级页表)。虚拟地址的第一部分称为全局页表目录,用于索引本进程的全局页表数组,PGD数组每个进程有且只有一个。PGD数组项指向另一些数组的起始地址,这些数组称为中间页目录。
PGD:指向本进程全局页表数组偏移地址,数组内容指向中间页表目录,目录包含一系列页表数组。
PMD:指向某中间页表的数组偏移地址,数组内容指向某页表目录。
PTE(页表项):指向某页表数组偏移地址,数组内容指向某页帧。
Offset:指向页内部的一个字节位置。
归根结底,每个虚拟地址都指向地址空间中唯一的定义的某个字节。
1.1.1 优势与改进
页表的一个特色在于,对虚拟地址空间中不需要的区域,不必创建中间页目录或页表。使用多级页表时,内存只需保存各进程的PGD,中间目录和PTE可放到磁盘。当进程切换时再通过PGD索引,将当前进程PTE加载到内存。而单级页表只能把所有进程使用到的PTE都存放到内存。由此多级页表节省了大量内存。
多级页表不要求PTE连续,提升了内存利用率。
当然,该方法也有一个缺点,每次访问内存时,必须逐级访问多个数组才能将虚拟地址转换为物理地址。CPU是同用下面两种方法加速该过程。
- CPU中有一个专门的模块称为MMU(Memory Management Unit),该单元优化了内存访问操作。
- 地址转换中出现最频繁的那些地址,保存到称为地址转换后备缓冲器(Translation Lookaside Buffer,TLB)的CPU高速缓存中。无需访问内存中的页表即可从高速缓存直接获取地址数据,因而大大加速了地址转换。
在许多体系结构中,高速缓存的运转是透明的,但某些体系结构则需要内核专门处理。这意味着每当页表的内容变化时必须使TLB高速缓存无效。内核中凡涉及操作页表之处都必须调用相应的指令。如果针对不需要此类操作的体系结构编译内核,则相应调用变为空操作。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1117
1117

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









