 无监督单目深度估计的挑战与突破:静态场景与光度一致性探讨
无监督单目深度估计的挑战与突破:静态场景与光度一致性探讨





浅谈无监督单目深度估计框架的局限性
个人拙见,欢迎交流
本文主要介绍基于单目视频序列的无监督单目深度估计框架,分析该框架所依赖的基本假设及其所导致的框架局限性,为该领域的后续发展提供一些个人建议和看法。
文章参考:**单目深度估计综述, 夜间无监督单目深度估计**等
一、无监督框架
1.基本网络框架
单目深度估计,顾名思义,从单张视图中估计像素点的深度信息;
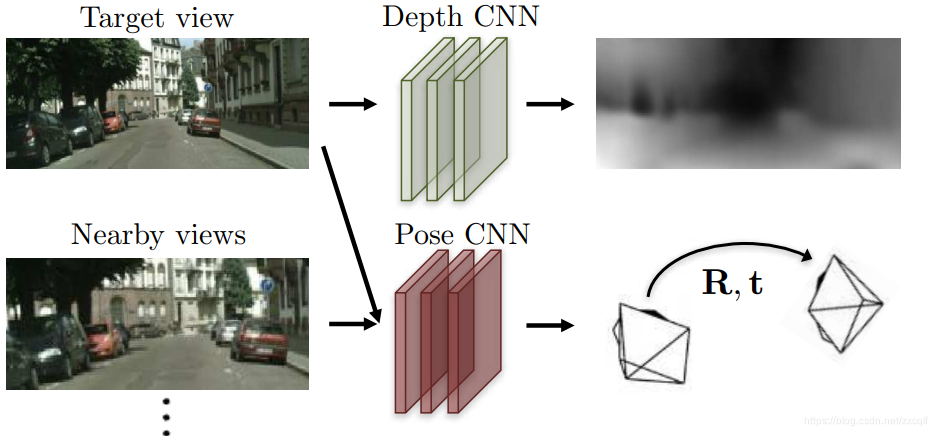
区别于基于Ground Truth的有监督单目深度估计方法和基于稀疏点云或双目视图的半监督单目深度估计方法,基于单目图像序列的无监督框架充分利用相邻前后帧间的几何信息作为整个框架训练的监督信号。如何构建图像间的几何信息?学过SLAM/VO的都知道,那就是投影。投影三要素:内参 K、深度 D 和 位姿 T。内参已知,深度由深度网络输出,因此无监督网络框架还需要设计一个位姿网络输出两张视图间的6D 位姿变换。因此,无监督单目深度估计的基本网络框架组成如下,包含一个深度估计网络Depth CNN和一个位姿估计网络Pose CNN:
From
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1536
1536

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









