






 数据仓库是一个支持管理决策的面向主题、集成、随时间变化且数据稳定的集合。其特点包括面向主题的数据存储,通过ETL过程集成来自多个源的数据。数据仓库框架包含数据采集层、数据存储与分析层、数据共享层和数据应用层,涉及HDFS、Hive、MapReduce、Spark等工具用于数据处理和分析。
数据仓库是一个支持管理决策的面向主题、集成、随时间变化且数据稳定的集合。其特点包括面向主题的数据存储,通过ETL过程集成来自多个源的数据。数据仓库框架包含数据采集层、数据存储与分析层、数据共享层和数据应用层,涉及HDFS、Hive、MapReduce、Spark等工具用于数据处理和分析。
1.1数据仓库概念
学习Hive之前,我们需要理解一个概念——数据仓库
数据仓库(Data Warehouse)可以简称为DW或者DWH,它是一个支持管理决策的数据集合。数据是面向主题的,集成的,不易丢失的并且是时变的。
1.2数据仓库的特点
面向主题:数据仓库都是基于某个明确的主题,比如关于订单的,关于商品的等,它里面只存储与该主题相关的数据,其他与该主题无关的数据都不会进行存储.
集成:从多个其他的数据源(如MySQL,Oracle等数据库)到一个数据源,该过程会伴随ETL操作,ETL(extract-transform-load)用来对源端的数据进行抽取,转换,加载到目的端。
随时间变化:数据显示或隐式的随着时间变化
数据信息本身稳定:当数据存储到仓库中,就会比较稳定,一般只进行查询操作,没有像传统数据库的改操作;
1.3数据仓库的框架
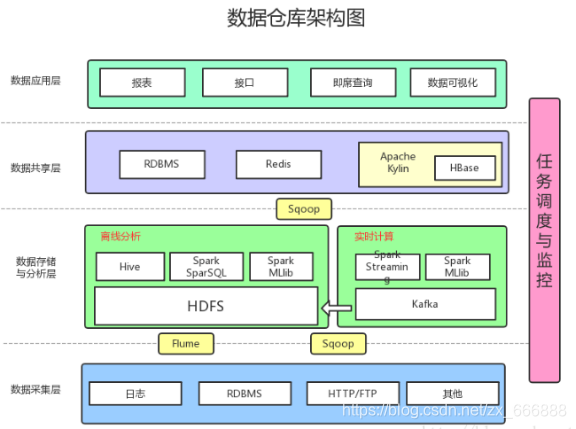
数据仓库框架主要分为:数据采集层、数据存储与分析层、数据共享层和数据应用层
数据采集层:主要的任务就是从各种数据源中采集的数据存储到数据库中,其中可能伴随着ETL操作。
数据源有很多种,主要包括以下几种:
日志:所占的份额最大,主要存储在备份服务器上,会进行日志清洗操作
业务数据库RDBMS:Relational Database Management System即关系数据库管理系统,例如MySQL,Oracle
HTTP/FTP:合作伙伴给提供的接口
其他:导入外部的Excel表等
数据存储与分析层:
HDFS是大数据环境下的数据仓库,能够很好的解决数据存储的问题
对于离线数据的分析计算,也就是对实时性要求不高的,Hive是很不错的选择。Hadoop框架也提供了MapReduce接口,也可以通过MapReduce进行离线数据分析计算。也可以通过使用Spark的生态体系完成离线的数据分析计算和实时的数据分析计算。
数据共享层:
上面通过Hive、MR、Spark分析计算获得的结果数据还是存储在HDFS上,大多数的业务和应用都不能够直接从HDFS上获取数据,所以我们需要设置一个文件共享的位置,方便其他业务和应用获取数据,这里的数据共享就是将之前分析计算的结果数据存储的位置,其实就是关系型数据库和NOSQL非关系型数据库。
数据应用层:
报表:根据分析计算的结果生成报表,存放在上一步的数据共享的位置
接口:生产Java接口供其他业务和应用使用
即席查询:可以理解为SQL语句查询(Ad Hoc)是用户根据自己的需求,灵活的选择查询条件,系统能够根据用户的选择生成相应的统计报表。即席查询与普通应用查询最大的不同是普通的应用查询是定制开发的,而即席查询是由用户自定义查询条件的。
数据可视化

















 4422
4422

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









