







注:如有需要开发大模型应用,网站等,后台私信我。
1、简介
平时我们会记录一些技术笔记或者分享一些技术博客,如何在我们积累的记录中快速查找相关解决方法,下面我将利用Langchain搭建一个基于博客文章的问答系统。
使用技术:Python、Langchain、Ollama、HuggingFaceEmbeddings、Chroma 等。
2、创建知识库
本系统是基于网页内容作为知识进行分割的,有以下几个步骤:
1)、首先使用 langchain_community.document_loaders 中的 WebBaseLoader 获取 documents;
2)、然后使用 langchain.text_splitter 中的RecursiveCharacterTextSplitter 对获取的文档进行切割,具体切割方式如下:
# 初始化文本分割器
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=200, # 指定每个文本块切割长度
chunk_overlap=20, # 文本块切割重复长度
separators=["\n\n", "\n", ".", "!", "?", ",", " ", ""]
)3)、将切割的文本块进行 embedding,使用 langchain_huggingface.embeddings 中的 HuggingFaceEmbeddings:
# 使用BAAI/bge-small-zh模型
model_name = "BAAI/bge-small-zh"
snapshot_download(
repo_id=model_name,
cache_dir=cache_dir,
local_files_only=False
)
# 初始化嵌入模型
self.embeddings = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs={
'device': 'cpu',
'trust_remote_code': True
},
cache_folder=cache_dir,
encode_kwargs={'normalize_embeddings': True}
)4)、将 embedding 后的文本块向量存储到向量库 Chroma中:
self.vectorstore = Chroma.from_documents(
documents=all_splits,
embedding=self.embeddings,
persist_directory=self.persist_directory # 向量持久化路径,如果设定了,后面加载就可以从这个路径中获取
)
3、使用Ollama平台运行大模型
Ollama是通过docker搭建的,可以参考 五分钟使用ollama部署本地大模型_ollama 运行本地模型-优快云博客 文章进行搭建。搭建完成之后,需要在Ollama中拉取使用的大模型,本文使用llama3.2为例:
# 1、启动 Ollama 容器,进入
docker exec -it ollama bash
# 2、拉取大模型
ollama pull llama3.24、指定使用 Ollama 平台和大模型
from langchain_ollama.llms import OllamaLLM
# 初始化OllamaLLM模型
llm = OllamaLLM(
model="llama3.2", # Ollama中的大模型
base_url="http://192.168.0.66:11434", # Ollama服务地址
temperature=0.7, # 控制输出的随机性
num_ctx=4096, # 上下文窗口大小
num_thread=4, # 使用的线程数
timeout=120, # 请求超时时间(秒)
streaming=True # 启用流式输出
)5、运行效果
1)、构建知识库
支持两种方式构建:1)、使用输入url链接进行构建;2)、使用txt/md文件进行构建(文件中每行一个url,批量构建)
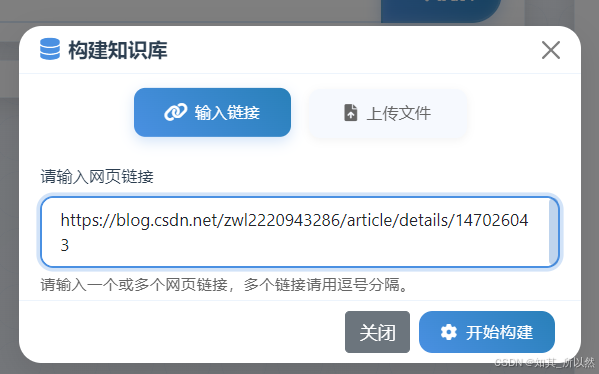
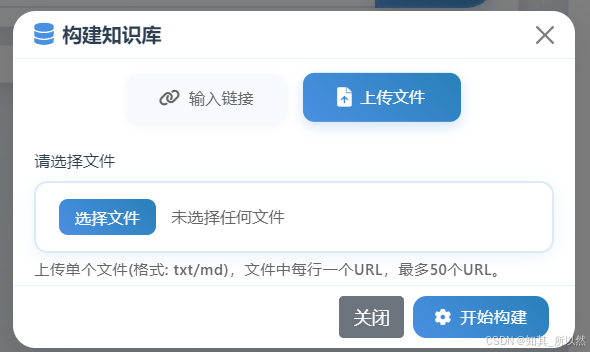
构建结果:
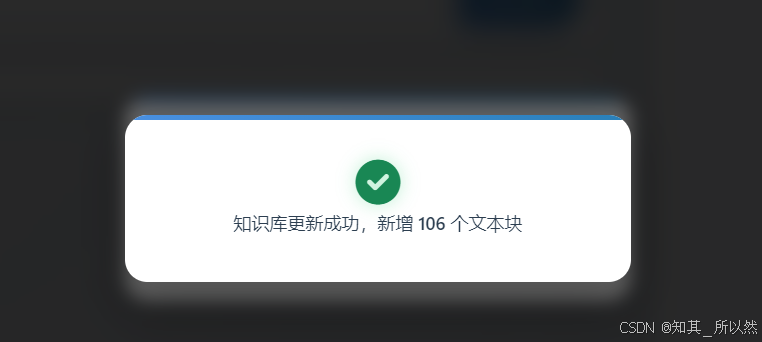
2)、检索结果
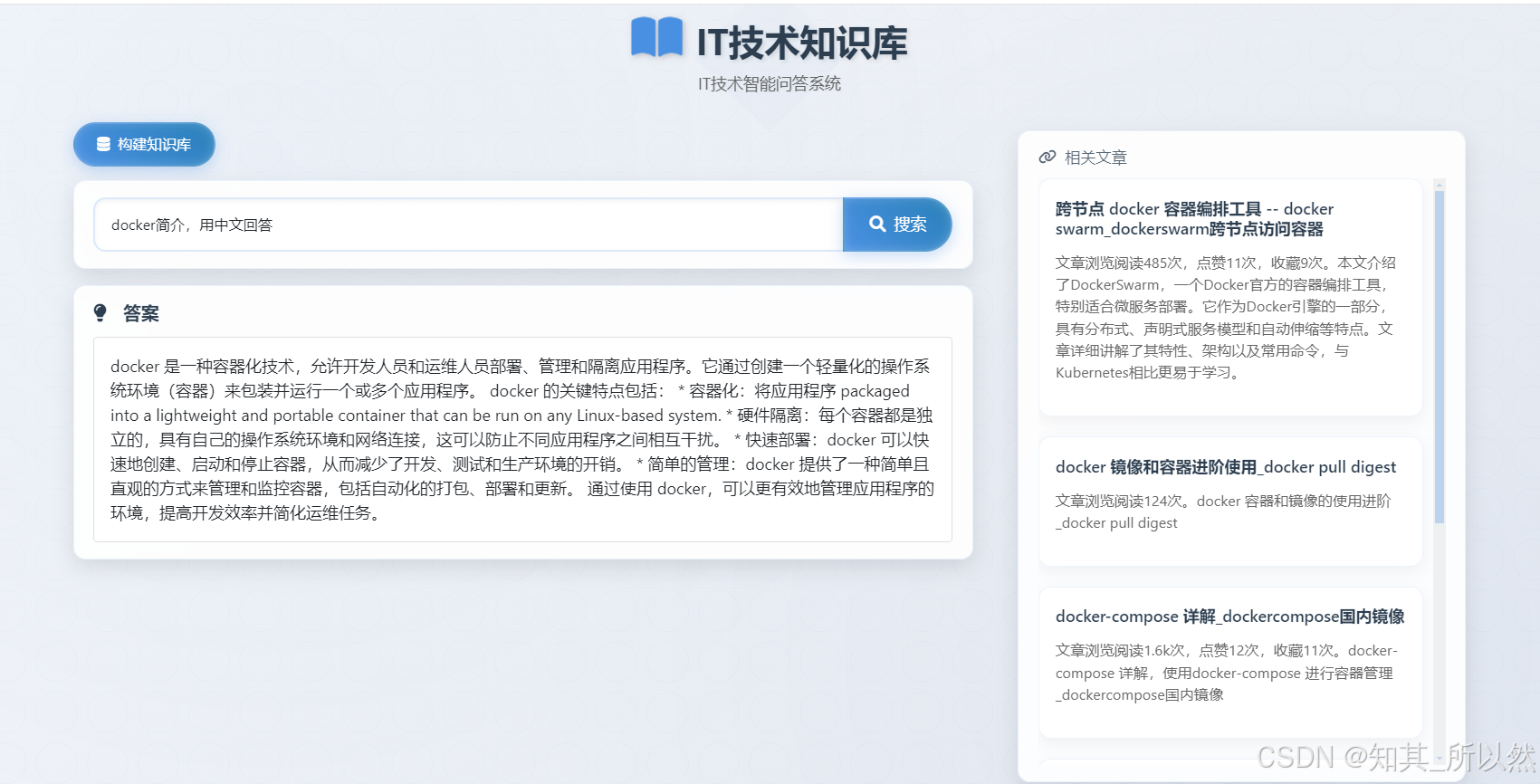
检索结果中会找出相关联的文章,并且支持链接跳转到指定的文章,这样就可以快速实现个人知识检索。
6、总结
本文使用Langchain搭建一个简易的问答系统,后续会逐渐完善,添加记忆、提示词等,逐渐优化系统,让系统提供更加精确的回答。
有感兴趣的朋友,可以关注 it自学社团 后台可以私信获取相关学习资料,一起交流学习;也希望和大家一起合作。



















 7614
7614

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











