






一、match_phrase_prefix
match_phrase_prefix和match_phrase原理很相似,不同点是,检索的最后一个term需要扫面整个倒排索引前缀匹配。
GET /forum/_search
{
"query": {
"match_phrase_prefix": {
"content": "java is"
}
}
}
java:会使用match搜索对于的doc,
is:会作为前缀,去扫描整个倒排索引,找到所有is开头的doc
match_phrase_prefix还支持:slop和max_expansions
GET /forum/_search
{
"query": {
"match_phrase_prefix": {
"content": {
"query": "java is",
"slop":1,
"max_expansions": 10
}
}
}
}
注意:
(1)slop不在此赘述,可参考https://blog.youkuaiyun.com/zuodaoyong/article/details/106586023
(2)max_expansions:指定prefix最多匹配多少个term,超过这个数量就不继续匹配了,提升性能
二、ngram
ngram将每个单词都进行进一步的分词切分,用切分后的term来实现前缀搜索推荐功能
PUT /my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"type": "ngram",
"min_gram": 2,
"max_gram": 3,
"token_chars": [
"letter",
"digit"
]
}
}
}
}
}
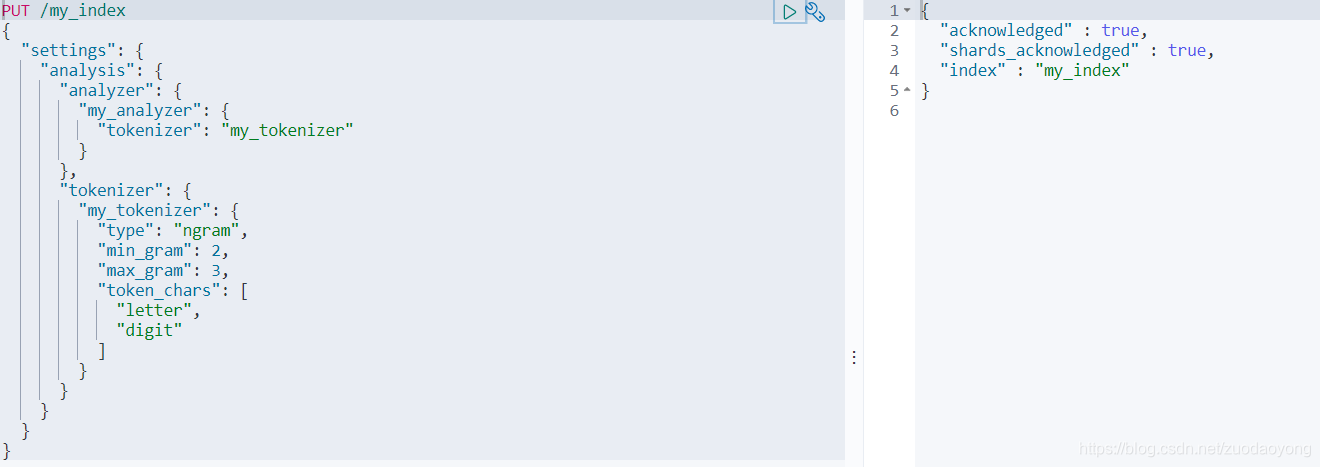
在my_index索引里创建一个my_analyzer分词器,分词器使用ngram,同时指定min_gram=2,max_gram=3
min_gram和max_gram的意思,我们使用一个例子来说明
比如用 my_analyzer 来对“world”分词,因为配置了min_gram和max_gram,分词的结果是:
wo,wor,or,orl,rl,rld,ld
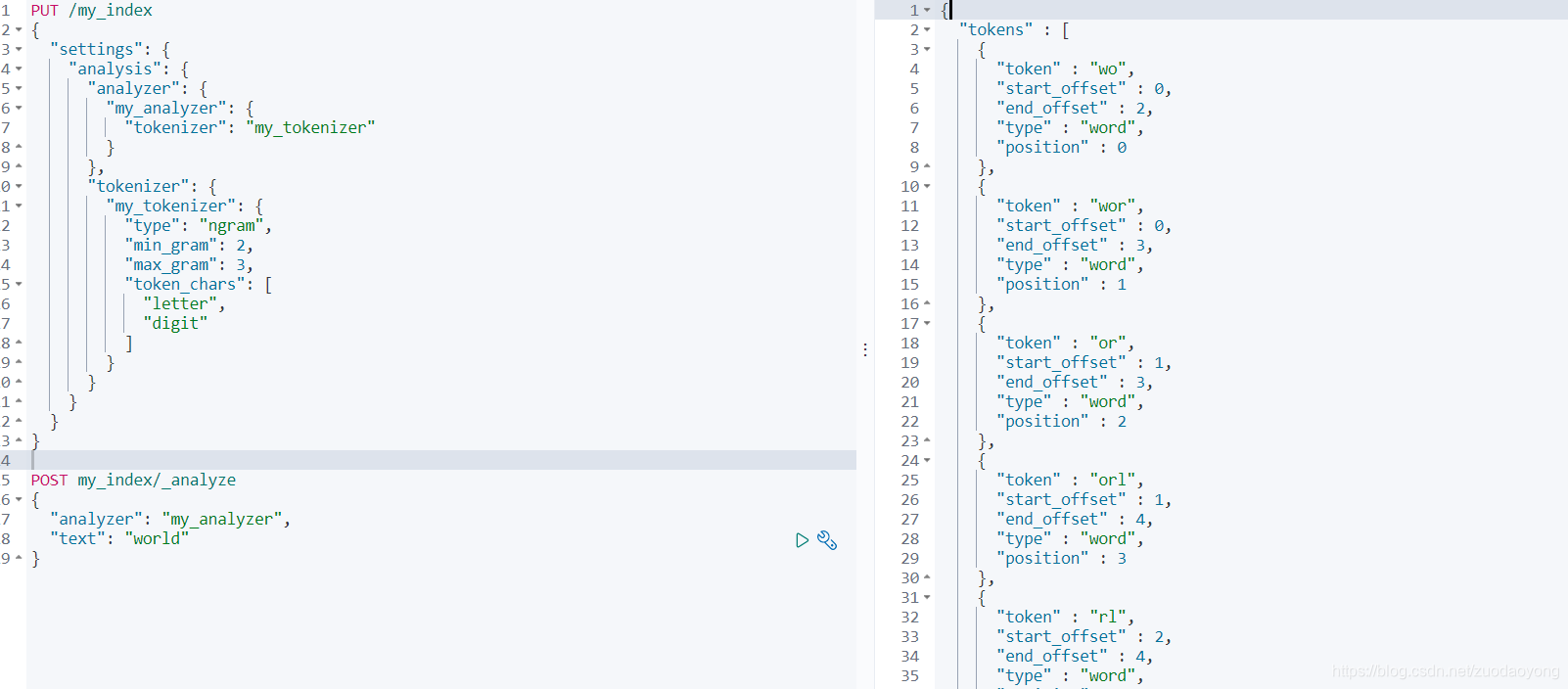
搜索的时候,不用再根据一个前缀,然后扫描整个倒排索引了,此时直接使用分好词的倒排索引中匹配即可

















 184
184

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









