







文章信息

论文题目为《ENTROFORMER:A TRANSFORMER-BASED ENTROPY MODEL FOR LEARNED IMAGE COMPRESSION》,文章来自ICLR 2022,是一篇图像压缩领域论文,提出了一种名为 Entroformer 的全新的基于 Transformer 的熵模型用于学习图像压缩 。该模型的主要创新包括:1) 使用多头注意力机制结合 top-k 选择来捕捉精确的依赖关系以估计概率分布 ; 2) 设计了一种菱形相对位置编码 (diamond RPE) 以提供更好的空间表示 ; 3) 引入了并行双向上下文模型来加速解码过程,而不会降低性能 。实验结果表明,Entroformer 在低比特率下优于目前最先进的基于 CNN 的方法以及标准的 BPG 编解码器,分别提高了 5.2% 和 20.5% 。这是首次成功将基于 Transformer 的方法应用于图像压缩领域,开创了新的研究方向。论文还提出了其他一些创新点,如使用 top-k 注意力机制和并行双向上下文模型,为未来的图像压缩研究提供了有价值的参考。总的来说,这篇论文在图像压缩领域取得了重要突破,为进一步提高压缩性能提供了新的思路和方法。

摘要

有损深度图像压缩的一个关键组成部分是熵模型,它预测了编码和解码模块中量化潜在表示的概率分布。先前的工作在卷积神经网络上建立熵模型,在捕获全局依赖性方面效率较低。在这项工作中,我们提出了一个新的基于transformer的熵模型,有效地捕获概率分布估计中的长期依赖性。与transformer不同,该entroformer具有较高的图像分类性能优化的图像压缩,包括一个top-k自注意和一个菱形相对位置编码。同时,我们利用一个并行的双向上下文模型进一步扩展了该体系结构以加快解码过程。实验结果表明,该算法在时间效率高的同时,取得了最先进的图像压缩性能。

贡献

(1)本文提出了一种改进学习图像的压缩方法。据我们所知,这是第一次成功地尝试将基于transformer的方法引入图像压缩任务。结果表明,我们的方法比最先进的CNNs方法好5.2%,比标准编解码器BPG好20.5%。
(2)为了进一步优化图像压缩的entroformer,提出了具有top-k选择的多头方案来捕获概率分布估计的精确依赖性和菱形,为了实现更好的位置编码,提出了相对位置编码(菱形RPE)。实验表明,这些方法支持图像压缩任务,保持训练稳定,获得更好的恢复精度。
(3)在双向上下文和双通译码框架的帮助下,我们的并行入口器比在现代GPU设备上的序列化入口更节能,且性能没有下降。

问题定义

在图像压缩的变换编码方法中,编码器使用参数分析变换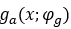 转化为潜在表示y,然后量化形成y ̂。因为y ̂是离散值,它可以使用熵编码技术,如算术编码进行无损压缩,并作为比特序列传输。另一方面,解码器从压缩信号中恢复y ̂,并对其进行参数合成变换
转化为潜在表示y,然后量化形成y ̂。因为y ̂是离散值,它可以使用熵编码技术,如算术编码进行无损压缩,并作为比特序列传输。另一方面,解码器从压缩信号中恢复y ̂,并对其进行参数合成变换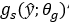 恢复重构图像x ̂。在本文中认为变换g_a和g_s是一般的参数化函数,如人工神经网络(ann),而不是传统压缩方法中的线性变换。然后,参数θ_g和φ_g封装了神经元的权重等。因此问题定义如下:
恢复重构图像x ̂。在本文中认为变换g_a和g_s是一般的参数化函数,如人工神经网络(ann),而不是传统压缩方法中的线性变换。然后,参数θ_g和φ_g封装了神经元的权重等。因此问题定义如下:
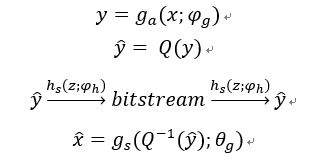

方法

5.1 基于transformer的熵模型
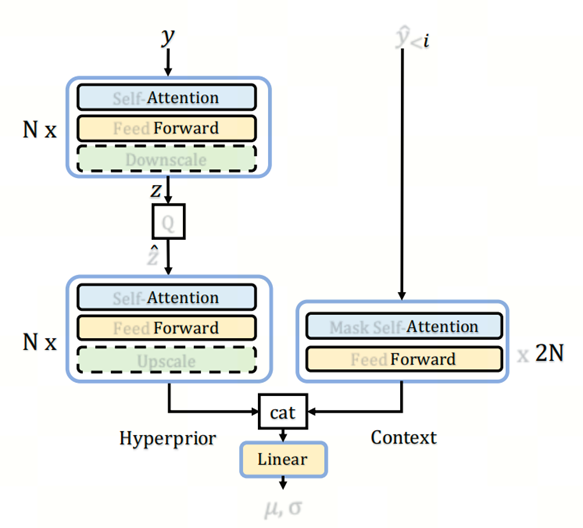
本文提出的基于transformer的熵模型如图所示,图中对于超先验,我们堆叠N个变压器编码器层以产生超潜势z,该z被量化并提供给N个变压器编码器层以生成超先验。生成层次代表离子时,通过降采样和高档模块,改变了特征的分辨率。对于自回归先验,我们堆叠2N个变压器解码器层来生成自回归特征。生成高斯一个参数,一个线性层被附加到超先验特征和上下文特征的组合上。
5.1 位置编码
为了探索位置在图像压缩中的影响,我们首先设计了一个基于变换器的熵模型,没有任何位置编码。在训练过程中,我们随机戴上一个面具来集中注意力。在测试过程中,我们评估了每个位置i都采用相应的掩码,除位置i外,掩码设置为1。下图绘制了将每个位置的比特率与所有位置的上下文结果进行比较。这一结果突显了利率的影响根据上下文的位置。这一观察结果提供了全面的理解,并提供了经验指导用于新的位置编码设计。
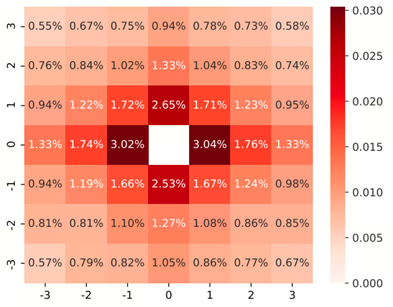
为了获取潜在因素的空间信息,一种常见的方法是使用基于相对关系的偏置注意权重。基于上图中的结果,我们提出了一个扩展到这种关系感知的自注意,以考虑元素位置对图像压缩性能的影响。具体如下式所示:
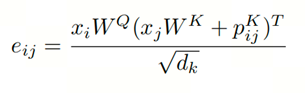
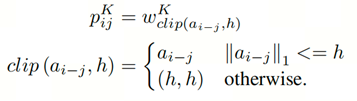
5.1 自注意力顶k机制
transformer中常见的关注是对比例点积的关注。它计算具有所有键的查询的点积,将每个键除以√dk,并应用一个softmax函数得到值的权重。因此本文提出了基于 Top-k 的自注意力机制,具体如下面公式所示:
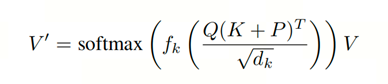

将查询、键和值打包成矩阵 Q、K 和 V。然后计算注意力矩阵 eij = (QK^T + P)/√dk,其中 P 是相对位置编码。接着使用Top-k 选择操作 fk(·)从每一行中选择 k 个最大的元素,最后通过 softmax 得到加权的值 V'。
这种 Top-k 自注意力机制有两个好处:1) 缓解了序列长度不匹配的问题;2)有助于去除无关的上下文信息,提高了模型的收敛速度。

实验

6.1 整体效果
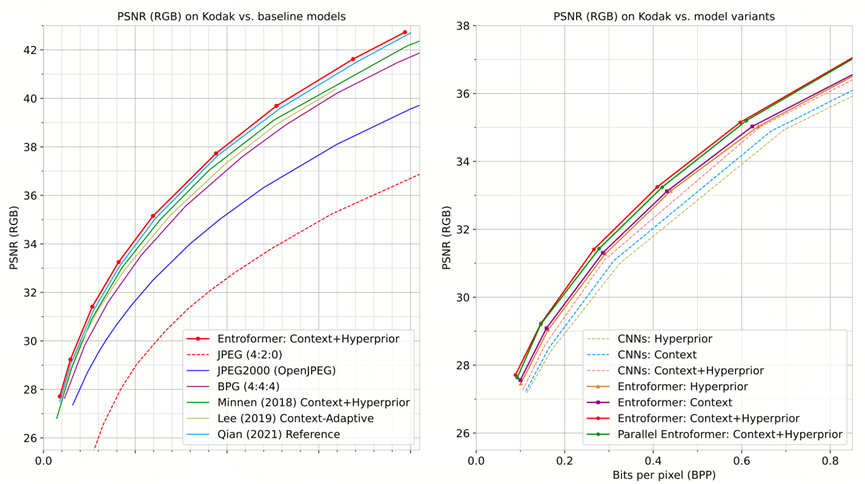
本文通过计算速率失真(RD)性能来评估transformer熵模型的影响。下图显示了公开可获得的柯达数据集的RD曲线,采用峰值信噪比(PSNR)作为图像质量度量。如左侧所示,我们结合超先验模块和上下文模块的性能优于CNNs方法,提高了5.2%,比BPG提高了20.5%。如右图所示,评估了两个变熵模型,即仅超优先级模型和仅上下文模以隔离Entroformer架构的影响。此外,具有双向上下文的并行Entroformer是也很有竞争力,比之前的基线更好。
6.2 位置编码影响
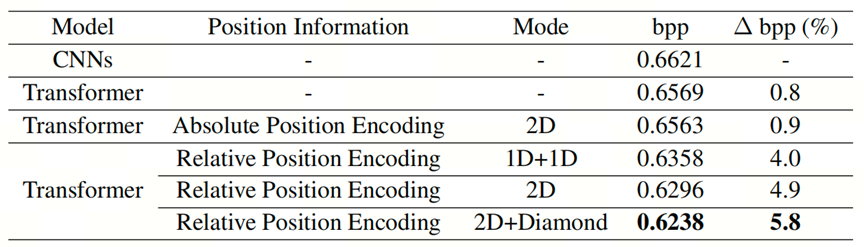
本文进行了组件分析,以研究不同位置的影响本文的Entroformer中的编码。本文构建了具有不同位置编码的基于变换器的上下文模型。A.基于CNN的上下文模型被实现用于比较。如表所示,应用绝对位置时在Entroformer中编码或非位置编码,本文可以实现比基线有限的bpp节省。如果本文使用相对位置编码,其性能优于绝对位置编码(节省4.0%bpp,节省0.9%bpp节省)。此外,将位置编码从1D扩展到2D至关重要(节省4.9%bpp,而节省4.0%bpp节省)。最后,结合菱形边界,本文可以比其他方法节省更多的比特率,特别是,与CNN相比,节省了5.8%的bpp。
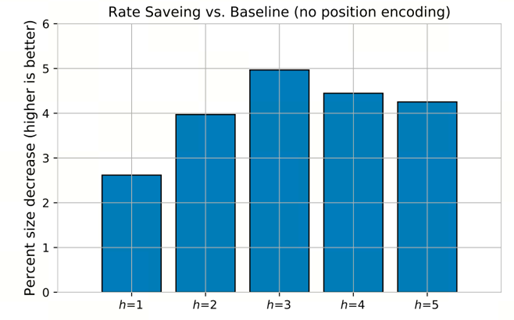
本文评估了改变裁剪距离h的影响。下图通过显示在单个速率点上的比特率的相对减少来比较h的数量。基线为由一个基于转换器的上下文模型实现,而不需要进行位置编码。当h = 3时,它达到了最好的结果。
6.3 top-k中k的影响
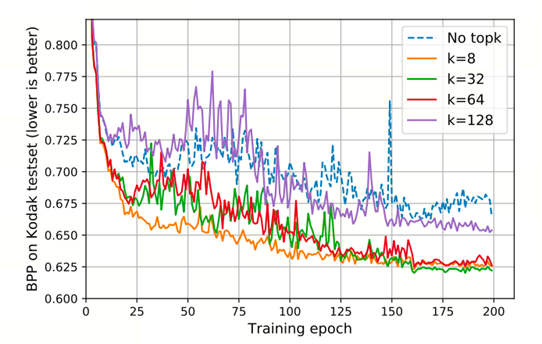
top-k方案的影响如图所示。参数k指定了自我关注所涉及的注意力数量。本文绘制了柯达测试集上不同k的完整学习bpp曲线,而不仅仅是单个RD点。给出了原始自我注意机制的附加曲线(虚线)以供比较。
值得注意的是,当k≤64时,压缩性能有所提高,这远小于训练和测试的序列长度576和1536。此外top-k方案也会影响Entroformer的收敛速度。有趣的是,当k大于64时,本文看到结果完全不同,top-k方案与原始自我注意没有区别。一个假设是存在在密集的自我关注中压缩大量无关信息用于图像压缩。这些观察结果反映了去除不相关的标记有利于Entroformer训练的收敛。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











