






1 文章信息
文章名为MIPaaL: Mixed Integer Program as a Layer。发表在第34届AAAI Conference on Artificial Intelligence ,作者来自南加州大学。
2 摘要
机器学习模块通常出现在较为重要的决策制定流程中;然而,模型训练过程通常仅关注一个损失函数,该函数测量预测值与真实值之间的准确性。决策导向性学习在训练预测模型时,明确集成下游决策问题,以优化由预测引发的决策质量。该方法已成功应用于一些有限的组合问题类别,如可以表示为线性规划(LP)和次模优化的问题。然而,以往的应用均集中于具有简单约束的特定类别问题。在此,该文为可以编码为混合整数线性规划(MIP)的广泛问题类别启用决策导向学习,从而支持对离散和连续变量的任意线性约束。该文展示了如何通过采用切平面解法对MIP进行微分,该方法是一种精确算法,迭代地向问题的连续松弛中添加约束,直到找到整数解。该文在多个现实世界领域评估了该文新的端到端方法,并证明其优于将预测和处方分开处理的标准两阶段方法,以及将决策导向学习简单应用于MIP的LP松弛的基线方法。
3 简介
该文提出了一种训练预测模型的方法,旨在直接优化基于模型预测所做决策的质量。该文特别关注以混合整数规划(MIP)形式呈现的决策问题,因为它们出现在电网负荷控制、RNA序列预测和许多其他工业应用等多种场景中。MIP之所以在许多场合自然出现,主要是由于其灵活性、计算复杂性(能够捕捉NP难问题)和可解释性。在许多实际情况下,通常需要基于历史数据预测MIP的某个模块(例如目标),如估计需求、价格预测或患者再入院率。然而,这些预测模型往往在训练时并未考虑下游的优化问题。标准的损失函数可能会强调正确预测离群值或小值,因为它们对损失函数有很大影响。然而,实际上决策可能永远不会基于离群值,因此模型的能力可能会集中在为特征空间中容易被忽视的区域提供适当的预测。此外,实践者可能希望确保预测的输出符合语义上有意义的目标,例如确保预测能够在下游做出公平决策。
机器学习模块通常出现在更大的决策制定管道中;然而,模型训练过程通常只关注测量预测值与真实值之间准确性的损失。决策聚焦学习在训练预测模型时明确整合下游决策问题,以优化预测引发的决策质量。在常用的基于梯度的预测模型中,中心挑战在于将梯度传回,以向预测模型指示如何调整权重,以改善生成的最优解的决策质量。使MIP广泛适用的离散和不连续解空间也使该文难以轻松进行微分,正如对嵌入连续优化问题的神经网络所做的那样。该文计算梯度的方法依赖于能够算法性地生成原始离散优化问题的精确连续替代品。该文采用了切平面方法的先前研究,通过迭代解决连续松弛并切除发现的整数不可行解,直到找到整数可行解,从而精确解决MIP。最终的连续且凸的优化问题可以通过微分连续替代品的KKT条件用于反向传播。尽管纯切平面方法在实践中通常比其他分支限界MIP求解器慢,但该文注意到,该文的方法在训练期间仅需要切平面方法用于反向传播。实际上,在测试时,该文可以根据预测结果使用任何先进的MIP求解器进行预测并找到最优决策,确保运行时间与任何其他训练方法相同。由于计算切平面进行反向传播的复杂性,该文还分析了一种混合方法,在生成固定数量切平面后停止生成,权衡可微求解器的精确性与改进的训练运行时间。其极端版本是在训练时完全忽略整数要求,仅使用问题的LP松弛。最后,该文将该文的决策聚焦方法与仅依赖于使用相关分类或回归损失函数进行训练的两阶段基线方法进行了评估。
该文在投资组合优化和具有多样性约束的二分匹配的两个不同真实世界MIP问题领域中展示了该文方法的有效性,显示出与基线相比在解质量上有显著改善。
这篇文章的主要贡献如下:
1.该文提出了MIPaaL,这是一种将混合整数规划作为神经网络中的可微分层纳入的原则性方法。该文通过算法生成等效的连续优化问题来处理这一灵活、离散且可能无法近似的问题,采用切平面方法。
2.该文将所提方法应用于决策聚焦学习,在这种方法中,预测模型使用直接与基于预测所做决策质量相关的损失函数进行训练。
3.该文通过实验证明,MIPaaL能够超越将预测和决策模块解耦的标准方法,以及仅使用原始组合优化问题的连续松弛的办法。为了更好地理解切平面技术的影响,该文探索了提前停止切平面生成的混合策略。
4 问题描述
<1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">该文考虑将学习与可以建模为混合整数规划(MIP)的优化问题相结合的问题。具体来说,每个问题实例是一个三元组1>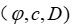 ,其中
,其中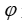 是特征向量,
是特征向量,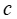 是 MIP 的目标系数向量,而
是 MIP 的目标系数向量,而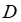 表示在下游优化中起作用的额外已知数据。在 MIP 中,
表示在下游优化中起作用的额外已知数据。在 MIP 中,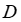 将包括每个训练实例
将包括每个训练实例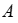 和
和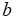 的左侧和右侧约束系数。如果
的左侧和右侧约束系数。如果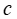 是已知的,该文可以简单地求解 MIP;然而,该文考虑的情境是
是已知的,该文可以简单地求解 MIP;然而,该文考虑的情境是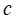 是未知的,必须从
是未知的,必须从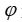 中估计。该文假设观察到的训练实例为
中估计。该文假设观察到的训练实例为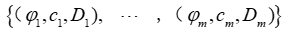 ,这些实例是从某个分布中抽取的。该文将使用这些数据训练一个预测模型
,这些实例是从某个分布中抽取的。该文将使用这些数据训练一个预测模型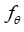 (其中
(其中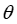 表示模型的内部参数),该模型在测试时实例上输出估计值
表示模型的内部参数),该模型在测试时实例上输出估计值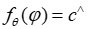 。在这种情况下,标准的两阶段方法是训练机器学习模型
。在这种情况下,标准的两阶段方法是训练机器学习模型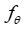 ,以最小化预测值
,以最小化预测值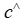 和真实值
和真实值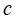 之间的损失。该文的目标是找到模型参数
之间的损失。该文的目标是找到模型参数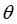 ,直接最大化针对
,直接最大化针对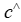 的 MIP 解的预期质量,并根据(未知的)真实目标
的 MIP 解的预期质量,并根据(未知的)真实目标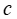 进行评估。该文将在下面对该问题及该文提出的方法进行形式化。
进行评估。该文将在下面对该问题及该文提出的方法进行形式化。
<1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">1><1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">5 问题求解1>
本文所使用的数据来自三个方面,分别是天气温度数据、电力消耗数据、人类移动数据,这三种数据内容丰富,包含负数,数值度量差异较大
该文将MIP表述为神经网络中的一个可微层,该层以目标系数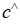 为输入,并输出最优的 MIP 解。该文将 MIP 的最优解
为输入,并输出最优的 MIP 解。该文将 MIP 的最优解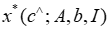 视为输入系数
视为输入系数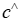 的函数,给定可行区域
的函数,给定可行区域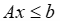 的线性约束和整数变量集合
的线性约束和整数变量集合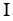 。该文将该层的函数形式写为:
。该文将该层的函数形式写为:
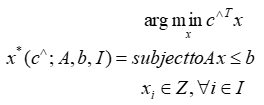
在给定输入目标系数(可能是神经网络的输出)和 MIP 的可行性参数时,该文可以进行前向传播,使用任何求解器。
在这种情况下的标准做法是首先训练一个模型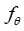 ,以基于不同预测模块的嵌入来预测系数
,以基于不同预测模块的嵌入来预测系数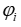 ,使得模型预测
,使得模型预测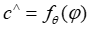 在平均上与真实目标系数的距离不远。然后,在部署时根据预测值做出决策,通过寻找相对于预测值
在平均上与真实目标系数的距离不远。然后,在部署时根据预测值做出决策,通过寻找相对于预测值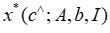 的最优解来实现。
的最优解来实现。
在这种情况下的前向传播是直接的;然而,MIP 的高度非凸和离散结构虽然使其具有灵活性,却妨碍了反向传播时梯度的直接计算。
该文提出了一种计算反向传播的方法,该方法依赖于找到一个连续优化问题,该问题在最优整数解下与原始优化问题等效。具体而言,该文使用纯切平面方法,该方法保证能够提供最优解(代价是可能生成指数级数量的切平面)。切平面方法通过迭代解决当前问题的线性规划松弛。如果找到的解是整数的,则算法终止,因为找到的解对原始 MIP 既可行又是原始问题松弛的最优解。否则,生成一个切平面,该平面去除发现的分数解,并保留所有可行的整数解。由于单个切平面不会去除任何整数解,最终的线性规划保留了所有整数解。
在极端情况下,假设可行区域是有界的,该文可以描述整数解的凸包,从而得出一个等价于原始 MIP 的线性规划,确保所有潜在的最优整数解位于可行区域的极值点上。单纯形算法,这是一种实践中有效的线性规划求解器,能够找到最优的极值点。在实践中,找到凸包是不可行的,但该文可以通过 Gomory 切割或其他全局有效切割获得生成精确整数解的切平面。
接下来,该文可以考虑生成切平面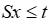 ,并写出以下等价的线性规划:
,并写出以下等价的线性规划:
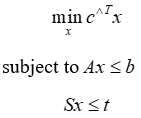
有了这个连续优化问题,现在可以通过对 KKT 条件进行微分,找到最优解相对于输入参数的梯度,这些 KKT 条件对于(2)的最优解是必要且充分的(因此对于原始 MIP 也是如此)。这一过程采用了 [Melding the data-decisions pipeline: Decision focused learning for combinatorial optimization] 中提出的二次平滑方法,基于对二次规划 KKT 条件的微分,如 [Optnet: Differentiable optimization as a layer in neural networks] 所示。
训练以最小化预测值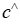 和真实值
和真实值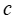 之间的误差可能在实践中导致决策效果不佳,因为标准误差指标,如均方误差或交叉熵,可能与所获得解决方案的决策质量不直接对齐。为了解决这个问题,该文可以通过将损失定义为给定预测系数的解决方案质量来训练预测模块以表现良好。换句话说,该文可以使用 MIPaaL 公式来训练模型,直接最小化部署目标。
之间的误差可能在实践中导致决策效果不佳,因为标准误差指标,如均方误差或交叉熵,可能与所获得解决方案的决策质量不直接对齐。为了解决这个问题,该文可以通过将损失定义为给定预测系数的解决方案质量来训练预测模块以表现良好。换句话说,该文可以使用 MIPaaL 公式来训练模型,直接最小化部署目标。
使用参数为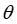 的神经网络
的神经网络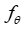 根据决策变量的嵌入
根据决策变量的嵌入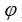 预测目标系数,该文计算一次前向传播,如下所示,通过切平面求解器生成与原始 MIP 对应的线性规划:
预测目标系数,该文计算一次前向传播,如下所示,通过切平面求解器生成与原始 MIP 对应的线性规划:
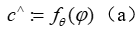
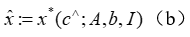
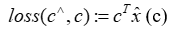
由于 (c) 中的点积和 (a) 中神经网络的预测是其输入的可微分函数,因此神经网络预测器的参数 θ 可以通过反向传播进行训练,使用在上述等价的线性规划中计算的代理线性规划的 KKT 条件,并依赖于 [Melding the data-decisions pipeline: Decision focused learning for combinatorial optimization] 中提出的小的二次正则化项来强制实现强凸性,从而通过 (b) 进行反向传播。
<1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">6实验验证1>
6.1基准模型
两阶段方法: 我们将其与标准的预测-优化方法进行比较,该方法将预测和优化组件分开处理。预测组件的训练目标是最小化预测的目标系数与真实值之间的标准损失(例如,均方误差或交叉熵)。随后,我们使用预测的系数求解混合整数规划(MIP)以达到最优解。
RootLP:接下来,该文与[Melding the data-decisions pipeline: Decision focused learning for combinatorial optimization]中的一种替代决策聚焦学习方法进行比较,该方法仅使用MIP的简单LP松弛(不考虑整性约束)。预测模型使用LP松弛进行训练,在测试时,该文使用预测的目标系数解决真实的MIP,以获得整数决策。这测试了该文的切割平面方法的影响,该方法使该文能够在MIPaaL的梯度中充分考虑组合约束。
MIPaaL - k切割:考虑到切割生成过程耗时且必须在每次前向传播中完成,该文检查在将生成的切割限制为固定数量k,并在生成前k个切割后停止切割生成时决策质量的权衡。这本质上试图在多项式时间内解决原始的NP难问题,因为每个LP可以在多项式时间内解决,并且该文生成了一个固定数量的切割。该文在两个设置下进行实验(k = 100和k = 1000),以确定切割生成过程的准确性如何影响测试时的决策质量。请注意,在k = 0时生成切割的情况下,该方法等同于RootLP方法,其中不生成任何切割。
6.2实验结果
<1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;"><1 style="text-wrap-style: initial;"> 该文通过以决策质量与预测精度为评价指标分别在投资组合优化与二分匹配中对模型进行了测试,1>1><1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;"><1 style="text-wrap-style: initial;"><1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;"><1 style="text-wrap-style: initial;">其中SP500(标准普尔500指数)是衡量美国股票市场表现的一个主要指数,包含500家大型公司的股票。DAX是一个由来自不同国家的30家公司组成的独立指数。1>1>1>1><1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;"><1 style="text-wrap-style: initial;">1>1>
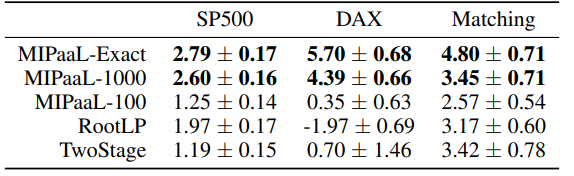
<1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;"><1 style="text-wrap-style: initial;">1>1><1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;"><1 style="text-wrap-style: initial;"><1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;"><1 style="text-wrap-style: initial;">决策质量评价如下图,精确的MIPaaL在决策质量上均优于基线方法,对于投资组合优化,其平均回报超过双阶段或RootLP方法的2倍,而在二分匹配中成功匹配的数量增加了40.3%。1>1>1>1>
<1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;"><1 style="text-wrap-style: initial;">预测精度如下图,我们注意到决策导向方法的最终机器学习性能差异很大。特别是,投资组合优化问题的测试均方误差(MSE)相比于双阶段方法相当高。1>1>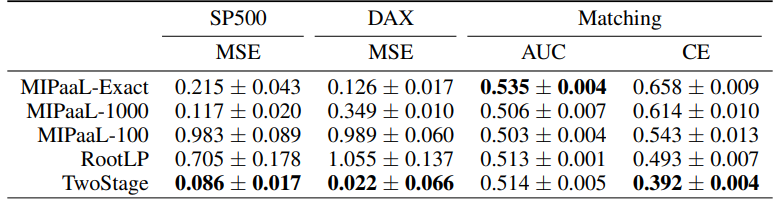
<1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;"><1 style="text-wrap-style: initial;"><1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;"><1 style="text-wrap-style: initial;">这种MSE与决策质量之间的差距突显了以任务为导向进行训练的必要性。尽管MIPaaL模型在两个投资组合优化设置中的MSE均低于双阶段方法,但它所产生的决策回报却高得多。1>1>1>1>
6.3迁移学习
<1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;"><1 style="text-wrap-style: initial;"><1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;"><1 style="text-wrap-style: initial;">该文在两个投资组合优化的转移学习任务上评估了MIPaaL、RootLP和双阶段方法,模型在从SP500中随机抽取的30个资产(SP-30a)的数据上进行训练,时间范围为2005年1月至2010年12月。随后,该文根据以下SP-30b(一组从SP500中随机抽取的30个资产)与DAX评估每个模型在2013年12月至2016年11月的数据上的表现,结果如下。1>1>1>1>
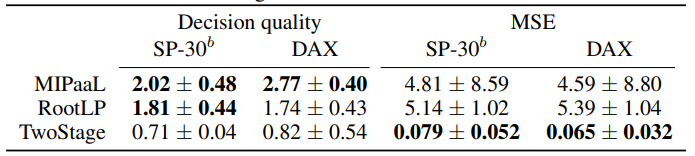
<1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;"><1 style="text-wrap-style: initial;"><1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;"><1 style="text-wrap-style: initial;">迁移学习结果显示,MIPaaL不仅在不同时间段表现良好,还能对未见过的资产和未见过的国家进行有效泛化。1>1>1>1>
<1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;"><1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;"><1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">1>1>1><1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;"><1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;"><1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;"><1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">7 1>1>1>1><1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;"><1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;"><1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">总结1>1>1>
<1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;"><1 style="text-wrap-style: initial;"><1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;"><1 style="text-wrap-style: initial;">该文提出了MIPaaL,这是一种将混合整数规划(MIP)作为神经网络中的可微分层的方法。该文通过算法生成一个等效的连续优化问题,来处理这一灵活、离散且可能不可近似的问题。该文将所提方法应用于决策聚焦学习,其中预测模型的训练损失函数直接与基于预测所做决策的质量相关。MIPaaL在两个组合优化设置和一个具有额外多样性约束的二分匹配设置中进行了评估,这些设置包含了许多在组合优化中广泛使用的建模技术,使得问题更复杂但也更现实。该文通过实证研究表明,MIPaaL能够超越标准的预测与决策模块分离的方法,以及仅使用原始组合优化问题的连续松弛方法。为了更好地理解切割平面技术的影响,该文探索了提前停止切割平面生成的混合策略。最终,该文的实证研究发现,在所调查的设置中,该文的方法能够提供高质量的解决方案。1>1>1>1>



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











