






1 文章信息
文章题为“UniST: A Prompt-Empowered Universal Model for Urban Spatio-Temporal Prediction”,该文于2024年发表至“30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining”。文章的核心是提出了一种通用城市时空预测模型,使一个模型能够处理多种任务。
2 摘要
城市时空预测对于交通管理、资源优化和应急响应等决策至关重要。尽管在预训练自然语言模型方面取得了显著的突破,使一个模型能够处理多种任务,但一个用于时空预测的通用解决方案仍然具有挑战性。现有的预测方法通常是针对特定的时空场景量身定制的,需要特定任务的模型设计和广泛的特定领域的训练数据。在这项研究中,引入了UniST模型,这是一个通用的模型,用于广泛场景下的一般城市时空预测。受大型语言模型的启发,UniST通过:(i)利用来自不同场景的多种时空数据,(ii)有效的预训练来捕获复杂的时空动态,(iii)知识引导的提示来增强泛化能力。
3 引言
预训练模型在自然语言处理(NLP)中取得了显著的成功,特别是在少样本和零样本场景中表现出色。然而,在城市时空预测领域尚未取得类似的突破。在本文中,目标是建立一个通用的城市时空预测的基础模型,具体来说,是开发一个在不同时空场景下具有优越性能和强大泛化能力的通用模型。这需要训练一个能够有效处理各种城市环境的单一模型,包括不同城市的人类流动性、交通和通信网络等各个领域。
这种通用模型的意义在于它能够解决城市地区普遍存在的数据短缺问题。不同领域和城市的数字化水平不同,往往导致数据集不平衡和不完整。尽管现有的时空建模方法取得了显著进步,但它们的有效性通常局限于单个城市的特定领域。对大量训练数据的依赖进一步阻碍了模型的泛化潜力。因此,目前的解决办法不具有“普遍性”。
一个通用的时空模型必须具备两个基本能力。首先,它必须能够利用来自不同城市场景的丰富数据进行训练。基础模型的训练应保证获取足够丰富的信息。其次,它应该在不同的时空情景中表现出强大的泛化能力。特别是在训练数据有限或没有训练数据的情况下,该模型仍然可以很好地工作,而不会出现明显的性能下降。
然而,构建一个时空数据的通用模型存在一定的挑战,同时难以直接利用NLP和CV的基础模型。(1)时空数据集具有不同的格式。不同于语言具有自然统一的顺序结构,不同于图像和视频具有标准化的维度,不同来源的时空数据呈现出高度变化的特征。其中包括不同的尺寸、时间持续时间和空间覆盖范围,这些差异很大,给标准化其结构带来了困难。(2)来自多个场景中数据分布具有高度差异。面对高度不同的时空模式,模型可能难以适应这些差异。
虽然时空数据所呈现的时空模式差异很大,但它们之间应该有某些共同的基本规律。这一原则源于一种直觉,即人类活动影响城市环境中产生的各种时空数据,从而导致普遍模式的存在。例如,交通速度和通信网络表现出不同的时空模式,但两者都受到人类流动性的影响,因此遵循类似的基本原则。此外,虽然时间周期模式在不同领域有所不同,但它们共享重复的基本概念。此外,不同城市区域之间的城市布局差异较大,但城市内部各功能区之间的关系可能表现出共同的特征。因此,构建“one-for-all”模型的关键是有效地捕获、对齐和利用这些共享的底层特征
为此,我们介绍了UniST,一个通过先进的预训练和快速学习的城市时空预测的通用解决方案。值得注意的是,UniST实现了三个基本功能:(1)具有不同时空数据的场景可扩展性;(2)有效的预训练,捕捉复杂的时空关系;(3)利用时空提示对不同场景的底层共享模式进行对齐。
UniST通过其由四个关键组成部分驱动的整体设计来实现上述能力:数据、架构、预训练和快速学习。首先,我们利用来自不同领域和城市的大量数据,利用时空场景固有的丰富多样性。其次,我们设计时空通过patching将不同的数据统一为顺序格式,从而促进对强大的Transformer架构的利用。第三,从大型语言和视觉模型中汲取灵感,UniST采用了广泛使用的生成式预训练策略——掩码令牌建模(mask Token Modeling, MTM)。进一步增强了模型捕捉复杂时空关系的能力,采用了多种掩码策略,全面解决了多视角相关性。此外,根据时空建模中已有的领域知识,设计了一种创新的提示学习方法。精心设计的提示网络识别潜在的和共享的时空模式,动态适应以生成有用的提示。通过这种方式,UniST统一了不同数据集的不同数据分布,并朝着开发一个通用模型的方向发展。
4 方法论
(1)问题描述
时空数据:使用网格进行空间划分,将城市划分为在𝐻×𝑊地图上由经度和纬度定义的相等、不重叠的区域。将一个时空数据𝑋定义为一个四维张量,维度为𝑇×𝐻×𝐻,其中𝑇表示时间步长,𝐻表示变量个数,𝐻和𝑊表示空间网格。𝑇、𝑇、𝐻和𝑊在不同的时空情景下可能会有所不同。
时空预测:对于一个特定的数据集,给定𝑙ℎ个时间步<1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">历史观测值,我们的目标是预测未来的𝑘个时间步。1>
<1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">少样本预测和零样本预测:该模型在多个源数据集上进行训练,然后适应目标数据集。在少样本学习中,它使用少量的目标样本进行微调;在零样本学习中,它在没有任何微调的情况下做出预测。1>
<1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">1><1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">1><1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">(2)训练步骤1><1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">1><1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">1>
<1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">1><1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">通用时空预测旨在使单一模型能够有效地处理不同的时空情景,这需要在一个内聚模型中统一不同的时空数据。这就需要处理不同场景的数据集之间的显著分布变化。为了实现这一目标,提出了一个预训练和快速学习的框架,从而形成了一个通用的预测模型UniST。图1显示了总体架构,详细介绍了UniST的两个阶段:1>
第一阶段:大尺度时空预训练。与局限于单<1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;">1>一数据集的现有方法不同,利用来自不同领域和城市的大量时空数据进行预训练。
第二阶段:以时空知识引导的提示学习。引入了一个上下文学习的提示网络,其中提示的生成由时空领域知识(如空间层次和时间周期性)自适应地生成。
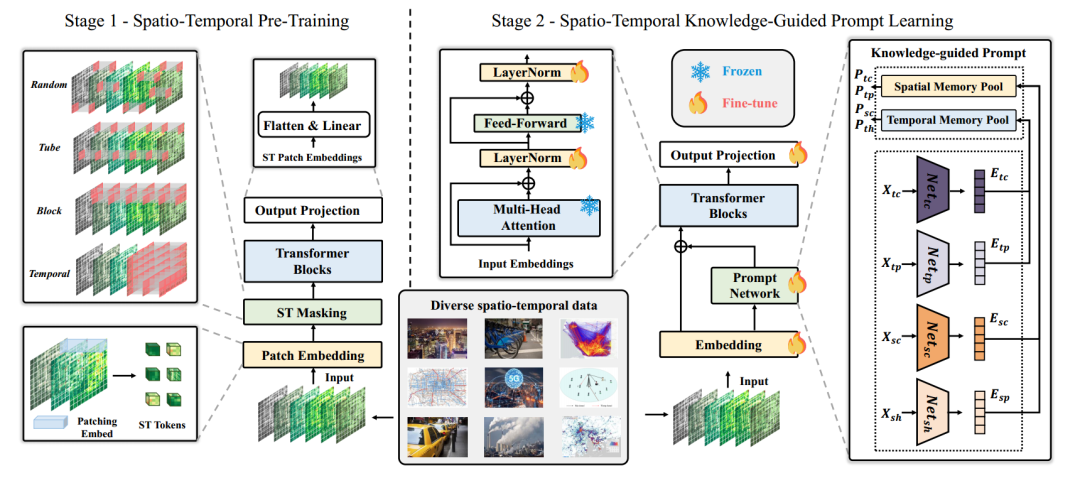
<1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">图1 框架图1>
<1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">(3)基本模型1>
<1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">1><1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">基本模型是一个基于transformer的编码器-解码器架构。通过时空拼接,可以以统一的顺序格式处理不同的时空数据。1><1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">1>
<1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">1><1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;"><1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">时空patching:1>1>传统的transformer结构是为处理一维顺序数据而设计的。然而,时空数据具有四维结构。为了适应这一点,首先将数据拆分为与通道无关的实例,即3D张量。然后,我们利用时空patching将三维张量(表示为𝑋∈R𝐿×𝐻×𝑊)转换成多个更小的三维张量。如果原始形状𝐿×𝐻×𝑊,和补丁的大小(ℎ𝑙,𝑤)。
位置编码:为了增强泛化,选择正弦和余弦函数而不是可学习的参数来进行位置编码,这种编码分别应用于空间和时间维度。
Encoder-Decoder结构:基本模型采用了掩码自动编码器(mask Autoencoder, MAE)启发的Encoder-Decoder框架。
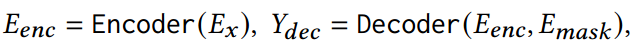
<1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">(4)时空自监督预训练1>
<1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">在预训练语言模型中,自监督学习任务要么是掩码重建,要么是自回归预测。1>同样,在视觉模型中,视觉块被随机掩盖,预训练目标是重建被掩盖的像素。为了进一步增强模型捕捉复杂时空关系和交织动态的能力,在预训练阶段引入了四种不同的掩码策略,如图2阶段1的左框所示。假设屏蔽百分比为𝑟,我们将这些策略解释如下:
随机掩码:这种策略与MAE中使用的策略类似,其中时空patching被随机屏蔽。其目的是捕获细粒度的时空关系。
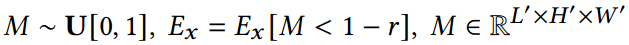
管掩码(Tube masking):该策略模拟了某些空间单元的数据在所有实例中完全丢失的场景,反映了现实世界中某些传感器可能无法工作的情况(这是常见的情况)。目标是提高空间外推能力。
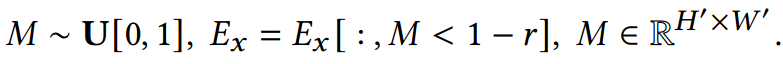
<1 style="letter-spacing: 1px;text-wrap: wrap;color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;">块掩码:块掩蔽涉及在所有实例中完全没有整个空间单元块。由于环境信息的限制,重建任务变得更加复杂,目的是增强空间可转移性。1>
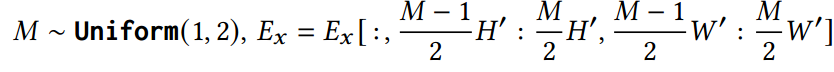
<1 style="letter-spacing: 1px;text-wrap: wrap;color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;">时间掩码:在这种方法中,未来的数据被掩盖,迫使模型仅根据历史信息重建未来。其目的是改进模型捕捉从过去到1>未来的时间依赖性的能力。<1 style="letter-spacing: 1px;text-wrap: wrap;color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;">1>
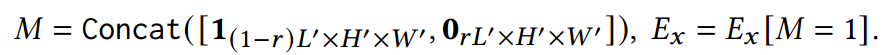
通过采用这些不同的掩蔽策略,该模型可以从综合的角度系统地增强其建模能力,同时处理时空、空间和时间关系。
(5)时空知识引导提示
时空领域知识:利用在时空建模中建立的领域知识的见解,包括与空间和时间相关的属性。在检查这些属性时,有四个方面需要考虑:
•空间亲密性sc:附近的单位可能会相互影响。
•空间层次性sh:空间层次性组织影响着时空动态,需要对城市结构进行多层次的感知。
•时间密切性tc:最近的动态影响未来的结果,表明密切依赖。
•时间周期tp:每日或每周的模式表现出相似性,显示出一定的周期性
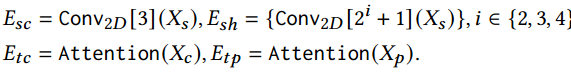
时空提示学习:从记忆网络中汲取灵感,提出了一种学习空间记忆池和时间记忆池的新方法。在快速学习过程中,这些记忆池被优化以存储有关时空领域知识的有价值信息。如图2所示,空间池和内存池的定义如下:
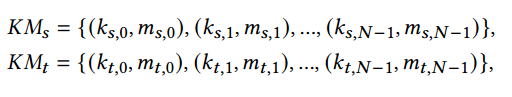
<1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">随后,基于这些优化的记忆生成有用的提示。这涉及到使用时空属性的表示作为查询来提取有价值的记忆知识,即从内存池中提取相关的嵌入。流程如图3所示,具体表述如下:1>
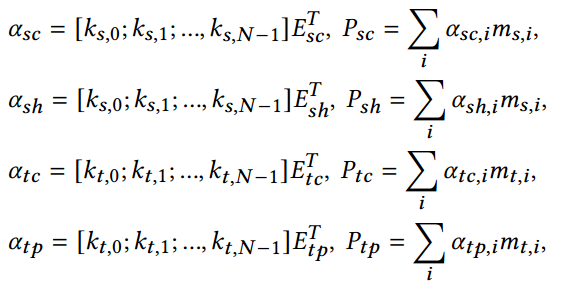
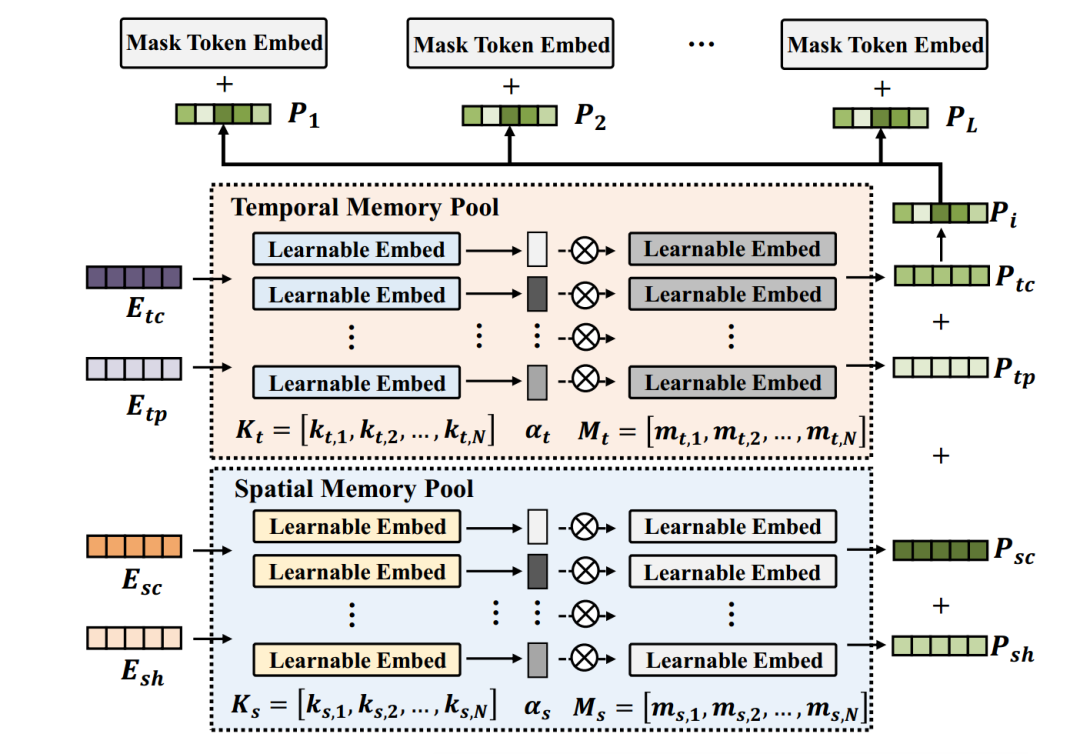
<1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">图2 时空知识引导1>
5 实验
<1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">短时预测:输入步长和预测步长均设为6,即6→6。对于基线,为每个数据集训练一个专用模型,而UniST在所有数据集上进行训练。
1>
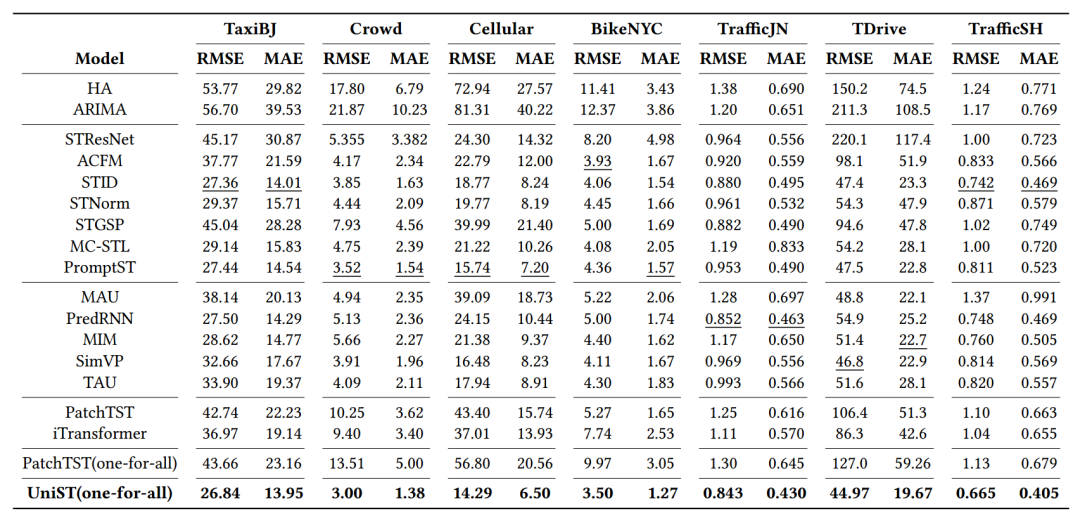
<1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">表1 短时预测
1>
<1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">表1给出了短期预测结果,由于空间限制,选择了数据集。正如我们从表1中观察到的,UniST在所有数据集上的性能始终优于所有基线。与每个数据集的最佳基线相比,它显示出显着的平均改进。值得注意的是,与时空方法相比,时间序列方法如PatchTST和iTransformer表现出较差的性能。这强调了将空间依赖性作为时空预测任务的先验知识的重要性。另一个观察结果是,PatchTST(one-for-all)比每个数据集专用的PatchTST表现更差,这表明模型很难直接适应这些不同的数据分布。此外,基线方法在不同的数据集上表现出不一致的性能,表明它们在不同场景下的不稳定性。UniST在所有场景中始终如一的优越性能强调了“一刀切”模式的巨大潜力和优势。此外,它还展示了UniST编排不同数据的能力,其中不同的数据集可以相互受益。1>
<1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">长时预测:这里将输入步长和预测范围扩展到64步。这个配置适应了长时间的依赖关系,允许我们衡量模型在捕获长时间模式方面的熟练程度。与短期预测类似,UniST直接在所有数据集上进行评估,而特定模型则在各自的数据集上针对每个基线进行单独训练。
1>
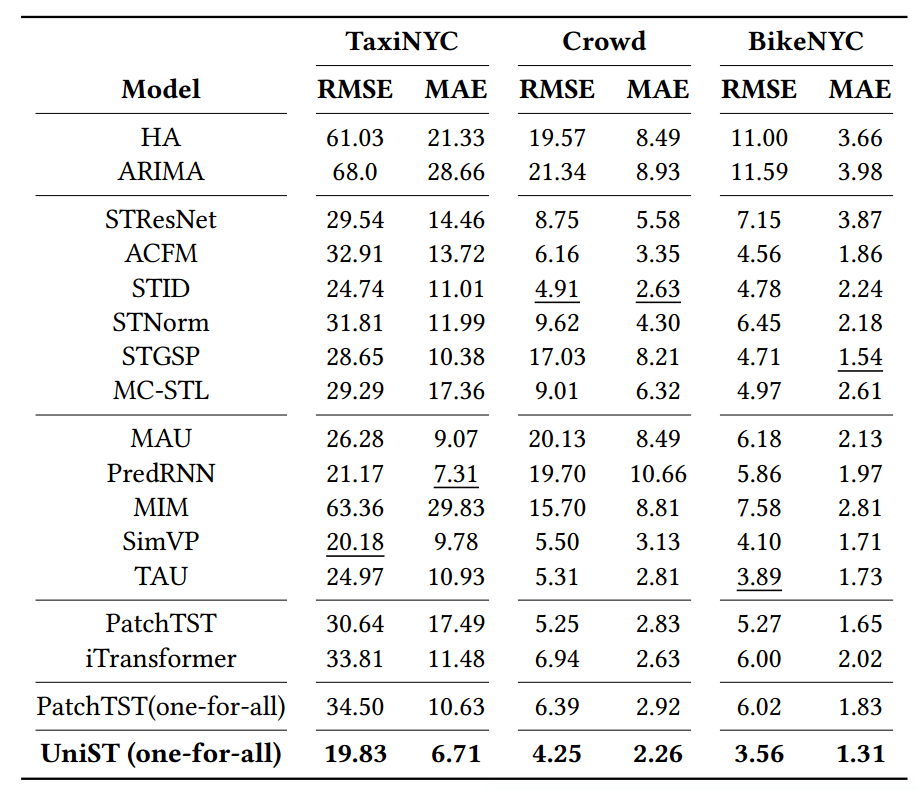
<1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">表2 长时预测1>
<1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">表2显示了长期预测结果。即使具有更广泛的预测范围,UniST仍然在所有数据集上始终优于所有基线方法。与每个数据集的最佳基线相比,它产生了10.1%的平均改进。这突出了UniST有效理解时间模式的能力,以及它在扩展持续时间的泛化方面的鲁棒性。1>
<1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">少样本预测:1>大型基础模型的特点在于其卓越的泛化能力。对于通用时间序列预测,通常采用少样本和零样本评估来描述最终任务。同样,少样本和零样本预测能力对于通用时空模型至关重要。在本节中,评估了UniST的少样本学习性能。每个数据集被分为三个部分:训练数据、验证数据和测试数据。在少量的学习场景中,当在训练过程中面对一个看不见的数据集时,使用了有限数量的训练数据,具体来说,训练数据的1%,5%,10%。选择了一些性能相对较好的基线进行少样本设置评估,还比较了元学习基线,即MAML和MetaST,以及基于预训练和微调的时间序列方法,即PatchTST。
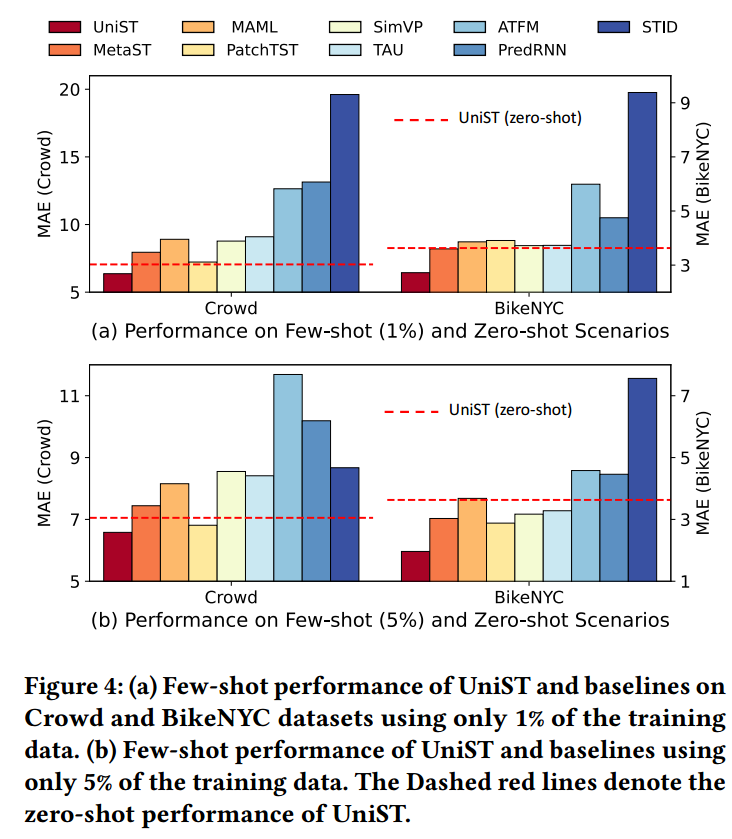
图3 少样本学习和零样本学习
<1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">在这些情况下,UniST仍然优于所有基线,与长期和短期预测相比,它在基线上实现了更大的相对改进。这种可转移性可以归因于我们的时空提示中成功的知识转移。1>
<1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">零样本预测:零样本推理是评估模型自适应能力的终极任务。在这种情况下,在对不同的数据集进行训练后,在一个全新的数据集上评估UniST。没有任何事先的训练数据。此场景中使用的测试数据与正常预测和少量预测的数据一致。1>
<1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">图3还比较了UniST(零样本)和基线(少样本)的性能。正如所观察到的,UniST实现了显著的零样本性能,甚至超过了许多用红色虚线突出显示的训练数据训练的基线。将这些惊人的结果归因于强大的时空转移能力。这表明,对于一个全新的场景,即使显示的整体模式与训练过程中遇到的数据不同,UniST也可以从定义的空间和时间属性中提取细粒度的相似模式。少样本和零样本的结果证明了UniST强大的泛化能力。1>
6 结论
<1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">这项工作中,解决了一个重要的问题,即建立一个用于城市时空预测的通用模型UniST。通过利用来自多个来源的时空数据的多样性,并在多个场景中识别和对齐潜在的共享时空模式,UniST展示了在所有场景中进行预测的强大能力,特别是在少样本和零样本学习中。1>
<1 style="color: rgb(0, 0, 0);font-family: 微软雅黑;font-size: 15.04px;letter-spacing: 1px;text-wrap: wrap;">1>


















 835
835

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











