







ELK作为一套高性能查询、数据收集、分析工具全家桶,在项目和平台中实用性很高,最近在想尝试安装elk工具,并集成spring-boot+log4j2 方便自身排查问题时查询日志以及后续运维时查询日志的便利性,本文为安装ELK工具,集成springboot+log4j2+ELK可以看下面的这篇文章参考
Springboot通过log4j2+logstash整合日志到Elasticsearch中_醉酒横刀的博客-优快云博客
谨以此文记,本人安装使用过程中遇到的一些坑,希望能帮助到大家。
本文参考:Linux虚拟机中ELK的安装配置_turkizat?的博客-优快云博客_虚拟机安装elk
首先介绍下elk各个组成部分:
Elasticsearch:是一个分布式、高扩展、高实时的搜索与数据分析引擎。它能很方便的使大量数据具有搜索、分析和探索的能力。
Logstash:是具有实时流水线能力的开源的数据收集引擎。常用于日志系统中做日志采集设备,最常用于ELK中作为日志收集器使用
Kibana:是一款开源的数据分析和可视化平台,它是 Elastic Stack 成员之一,设计用于和Elasticsearch 协作。
1、环境准备
centos虚拟机3台(1台也可以)
需要配置jdk、关闭防火墙(或者后续设置防火墙对指定端口开放)
下载ELK,我下载的是7.11.0版本的(尽量选一致的版本),下载地址如下:
https://www.elastic.co/cn/downloads/past-releases#
2、文件拷贝解压
在虚拟机中新建文件夹(位置、名称自定义)
/opt/ELK7.11.0
将文件拷贝到文件夹,进行解压
tar -zxvf elasticsearch-7.11.0-linux-x86_64.tar.gz
tar -zxvf logstash-7.11.0-linux-x86_64.tar.gz
tar -zxvf kibana-7.11.0-linux-x86_64.tar.gz
修改解压包名称为(名称自定义):
elasticsearch-7.11.0、logstash-7.11.0、kibana-7.11.0
3、修改配置
1)修改系统配置
# 设置最大内存映射区域数
vi /etc/sysctl.conf, 在底部插入 vm.max_map_count=655360,
# 查看是否配置成功
sysctl -w vm.max_map_count=655360 若出现vm.max_map_count = 655360即配置成功
# 设置句柄数等参数
vi /etc/security/limits.conf,底部插入如下配置(如果不生效则重启电脑)
* soft nofile 65536
* hard nofile 65536
* soft nproc 4096
* hard nproc 4096# 添加普通用户es,为后续启动es、kibna等做准备
useradd es
# head插件
google浏览器添加head插件用来访问es
2)修改elasticsearch配置
# 进入es的配置文件夹
cd elasticsearch-7.11.0/config/
# 修改elasticsearch.yml配置,在最底部插入如下配置
vi elasticsearch.yml
# 集群名称
cluster.name: bigdata
# 节点名称
node.name: bigdata01
# 是否主节点
node.master: true
# ip地址
network.host: 192.168.36.129
#集群地址 我这是三节点的所以三个ip,根据实际节点数调整
discovery.zen.ping.unicast.hosts: ["192.168.36.129","192.168.36.130","192.168.36.131"]
# 是否允许跨域访问
http.cors.enabled: true
# 跨域访问配置,*为所有访问
http.cors.allow-origin: "*"
# 主节点名称
cluster.initial_master_nodes: ["bigdata01"] 3)修改logstash配置
# 进入logstash的配置文件
cd logstash-7.11.0/config/
# 编辑logstash配置
logstash配置是在使用时配置的,下篇文章《集成springboot+log4j2+ELK》时会配置 l,启用时 选择配置即可,此处由于未使用到,暂时不做处理
4)修改kibana配置
# 进入kibana的配置文件
cd kibana-7.11.0/config/
# 进入logstash的配置文件,在最底部插入
vi kibana.yml
# 服务地址
server.host: "192.168.36.129"
# 连接es地址,此处可以连接集群
elasticsearch.hosts: ["http://192.168.36.129:9200"]4、启动
1) 启动elasticsearch
# 切换用户
su es
# 给用户赋予elasticsearch文件夹的权限
sudo chown -R es:es elasticsearch7.11
# 进入bin目录
cd elasticsearch-7.11.0/bin/
# 后台启动es
./elasticsearch -d
# 关闭es,先查找进程,再kill掉
ps -ef|grep elasticsearc
2)启动logstash
# 进入logstash的bin目录
cd logstash-7.11.0/bin/
# 启动logstash
./logstash -f /opt/ELK7.11.0/logstash-7.11.0/config/logstash.yml
# 关闭logstash,先查找进程,再kill掉
ps -ef|grep logstash
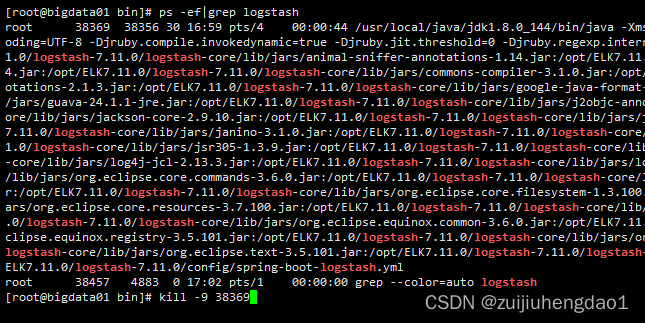
3)启动kibana
# 切换用户
su es
# 进入kibana目录
cd kibana-7.11.0/bin/
# 启动kibana
./kibana
# 后台启动kibana
nohup ./kibana &
# 关闭kibana,先查看端口号,再kill掉
netstat -tunlp|grep 5601

5、验证
1)登录kibana
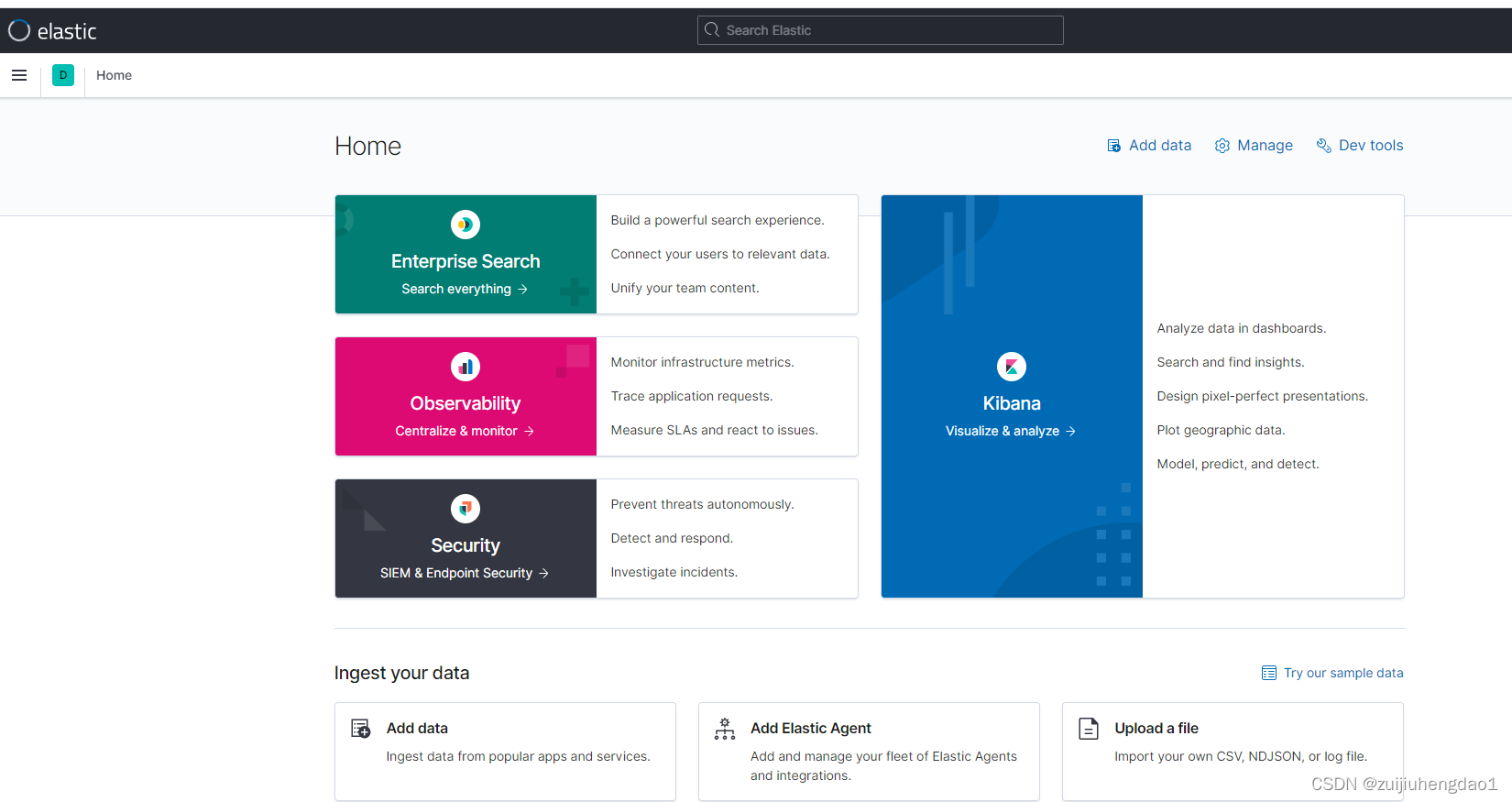
2)使用kibana管理、查询elasticsearch数据
# 新建索引
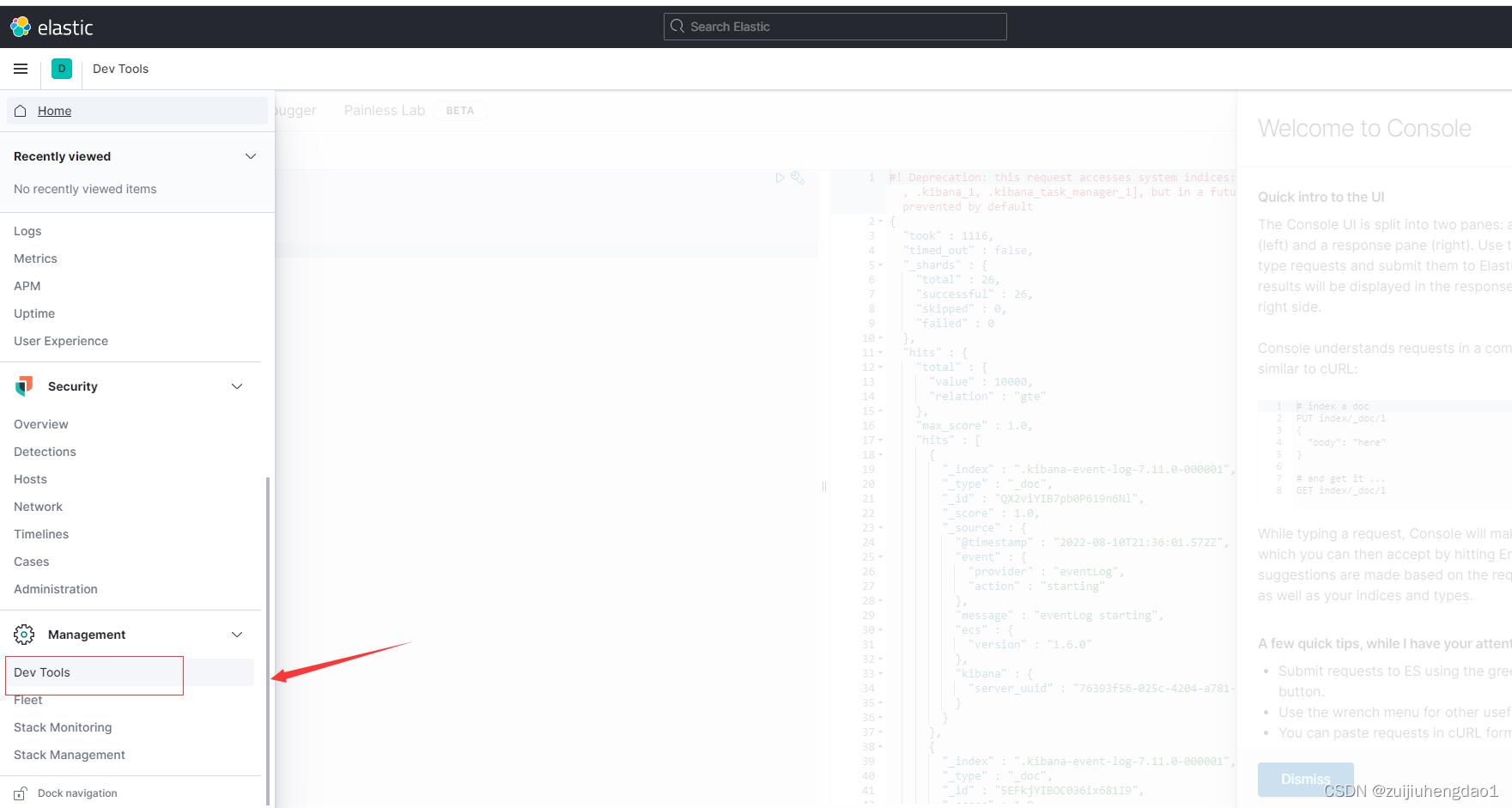
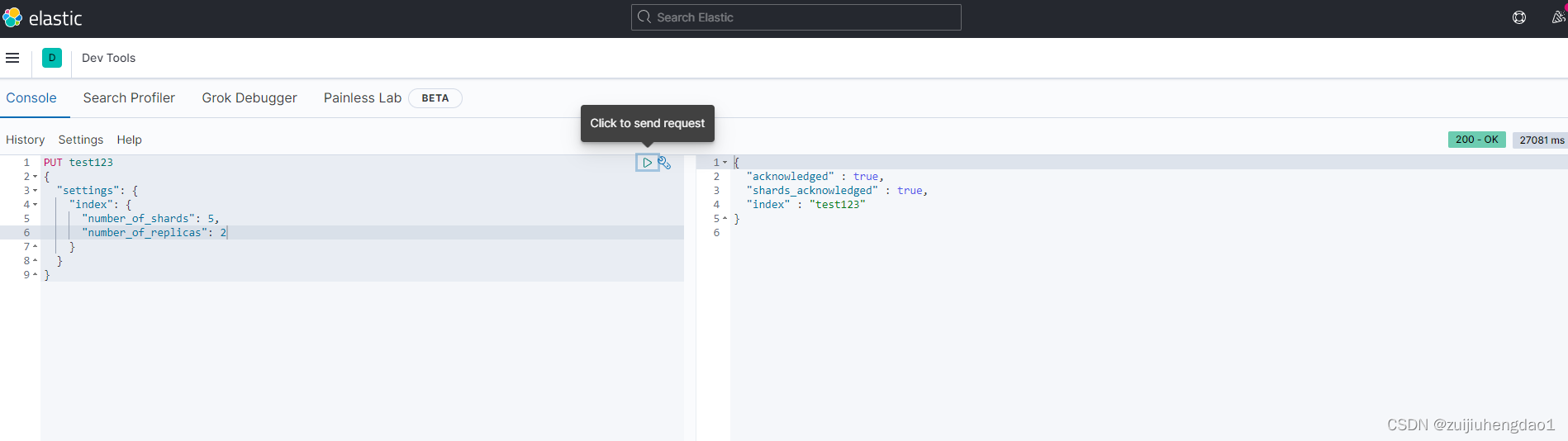
### 5分片2副本(根据自己情况自定义)
### 新建mapping
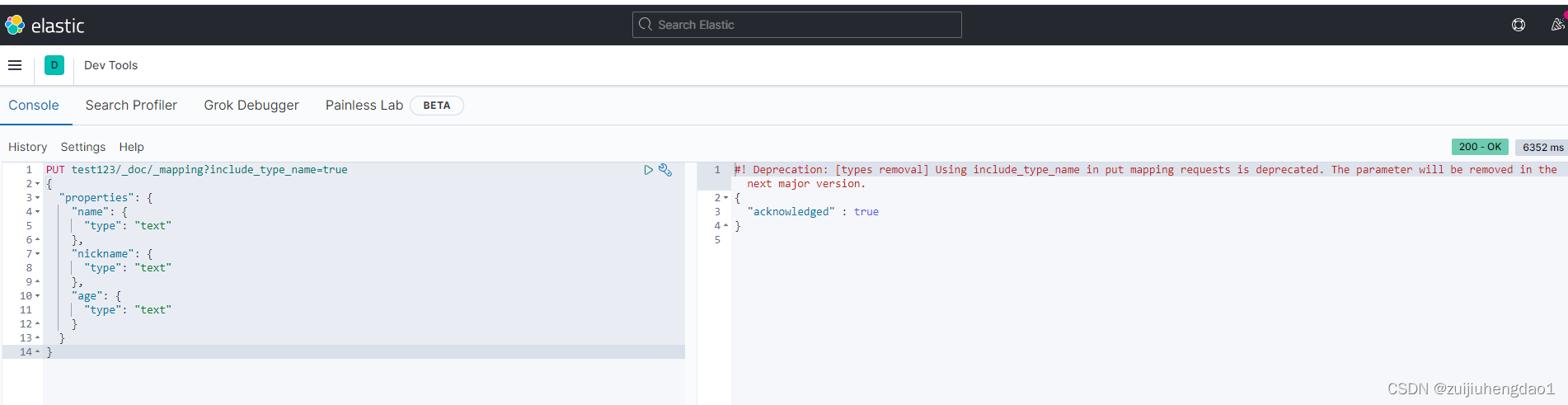
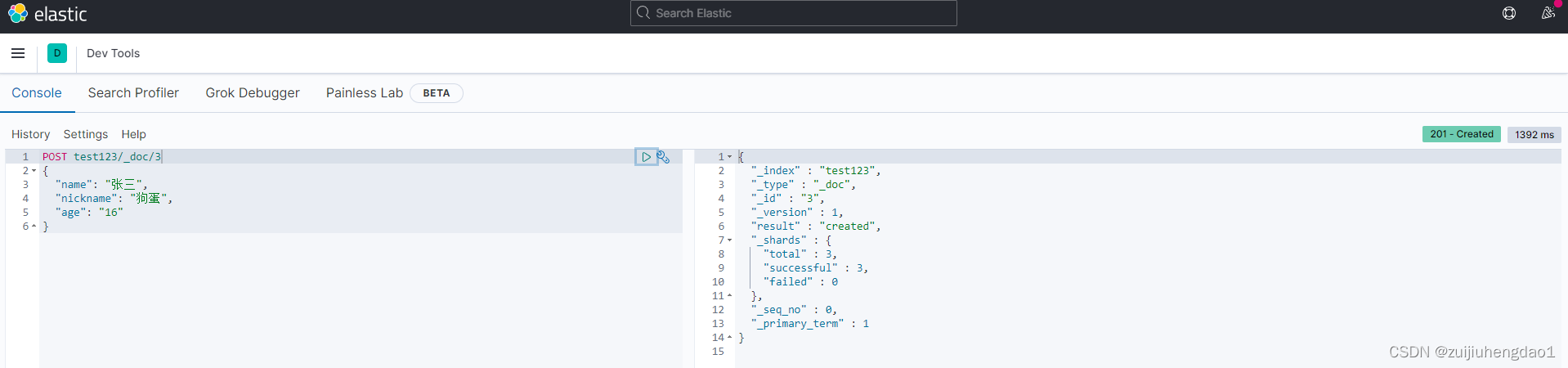
### 新增一条数据
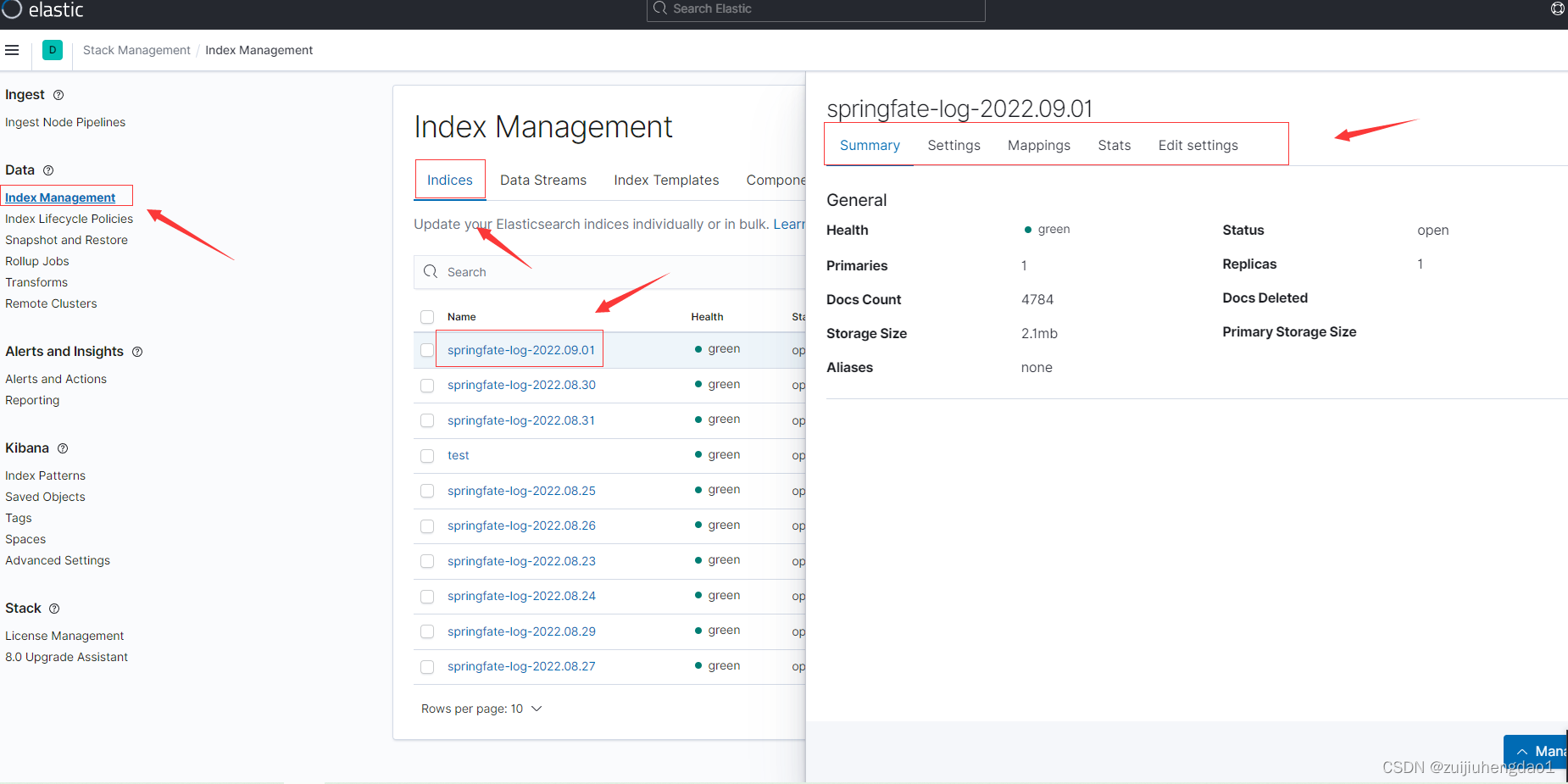
# 管理索引
# 新建查询规则
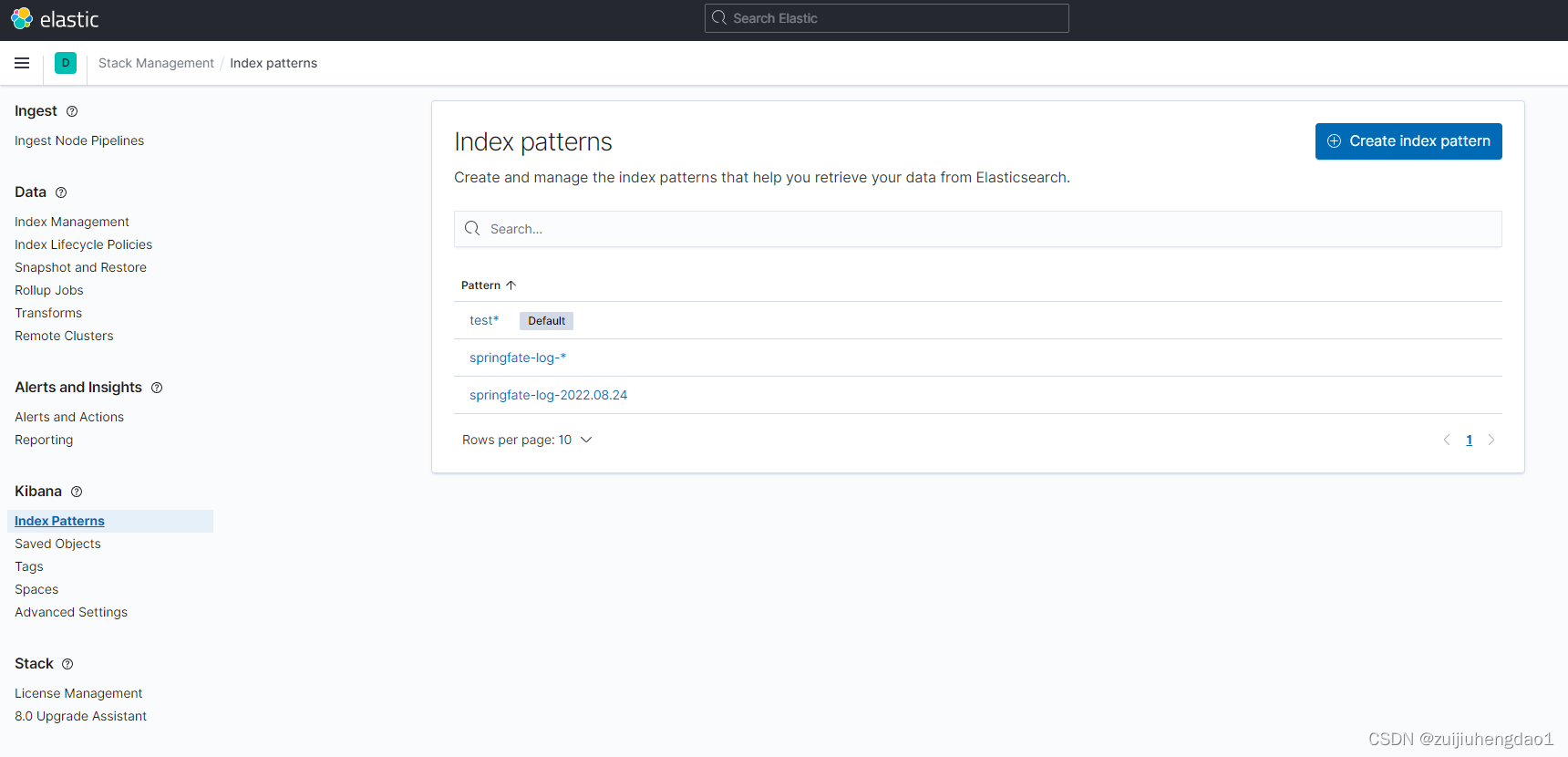
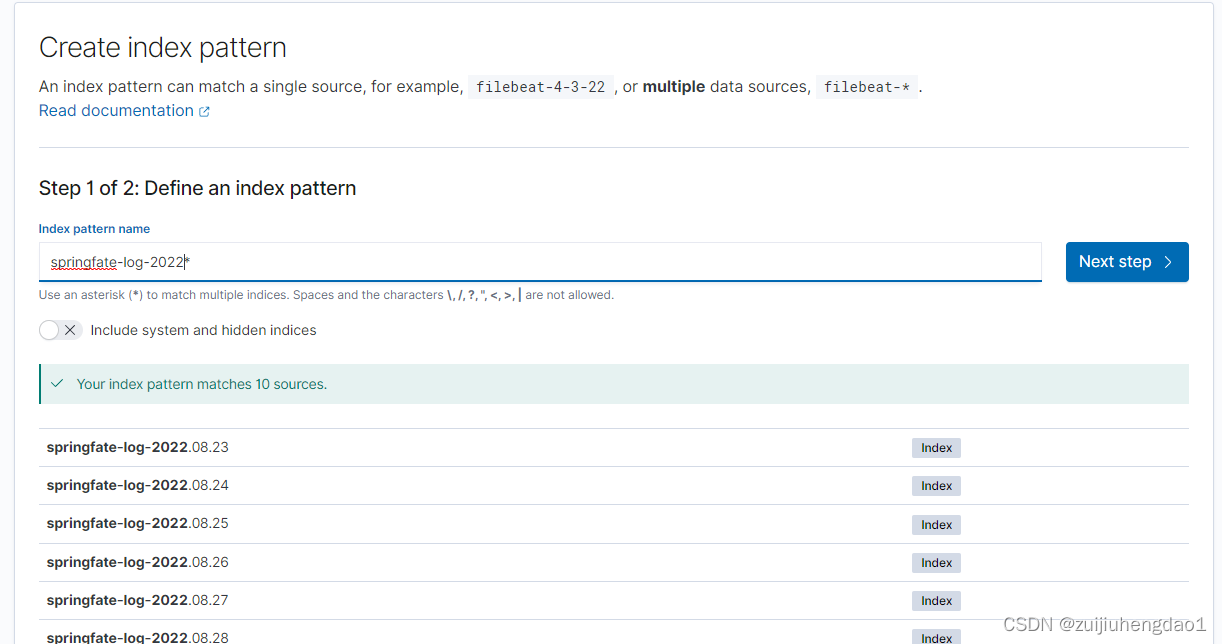
### 这里根据自己情况来,如果不想用默认的规则可以不选
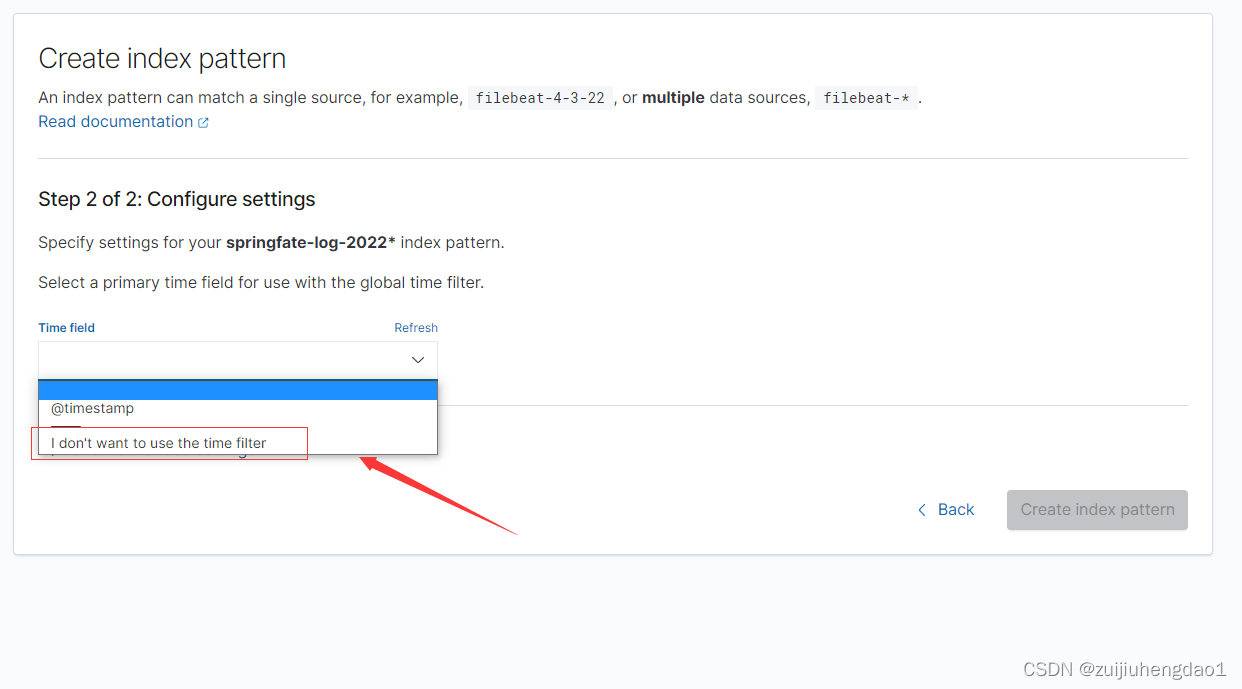
# 查询数据
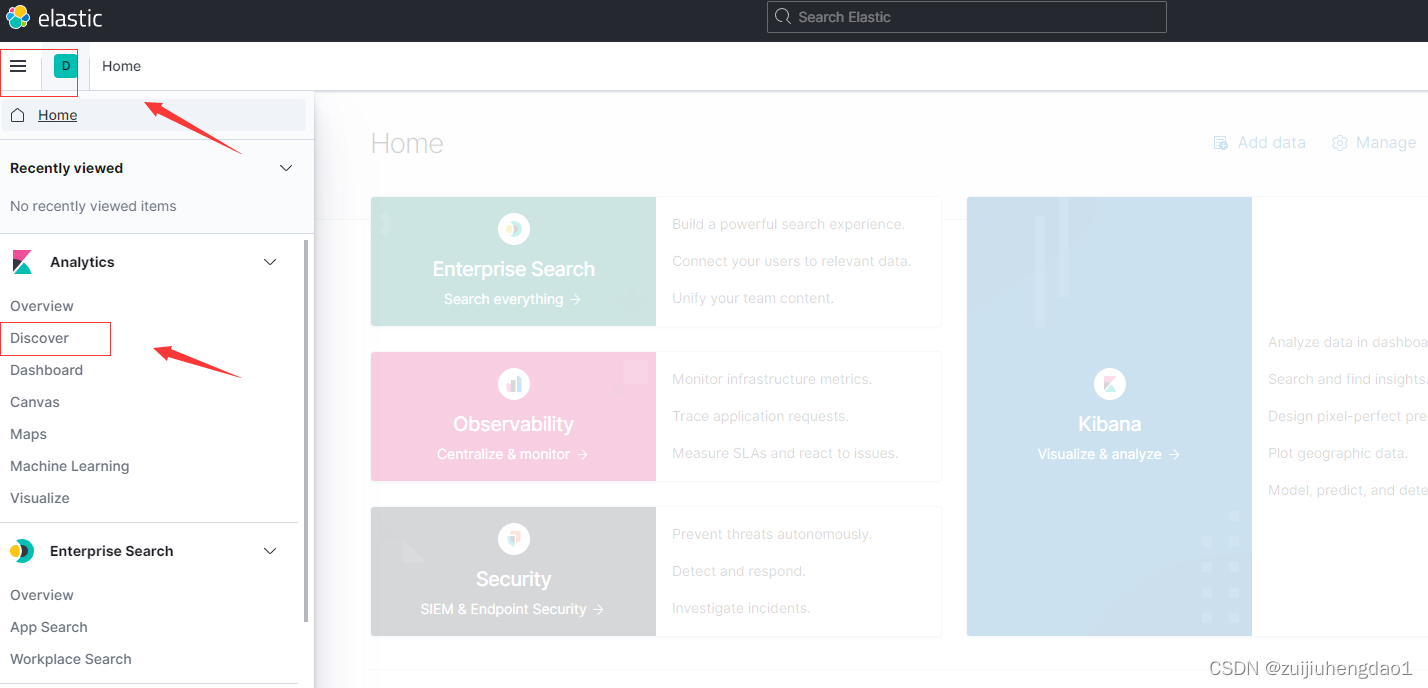
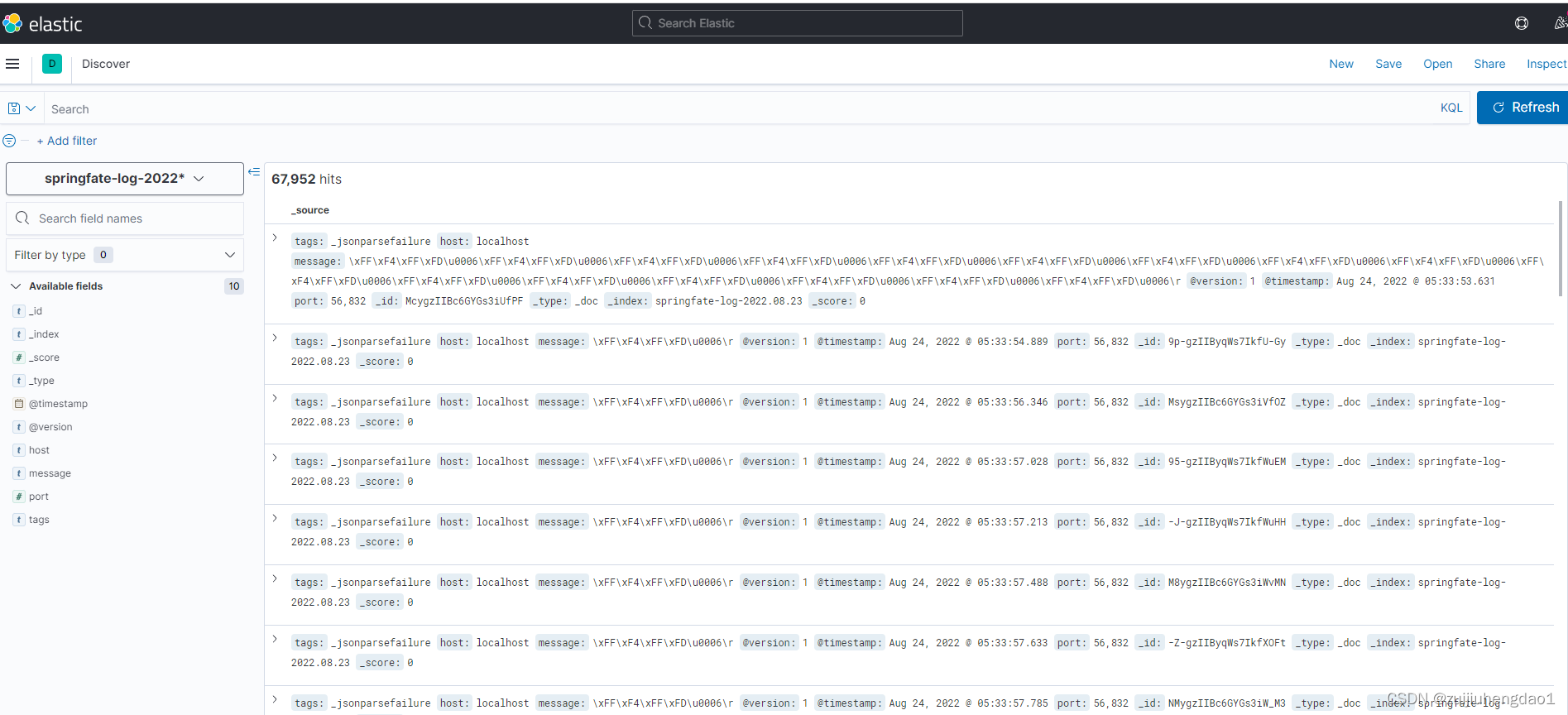
### 根据需要建立查询条件
# 其他使用
其他功能可以百度查询或者自己探索
3)使用head插件
# 谷歌浏览器集成head插件
# 使用head插件新建索引、增删改查数据
由于head插件使用内容比较多所以另写一篇专门介绍,感兴趣的同学可以查看一下链接:
Elasticsearch head插件安装及数据的基本操作_醉酒横刀的博客-优快云博客
6、遇到的问题及解决
问题(1): max file descriptors [4096] for elasticsearch process is too low, increase to at least [65535]
解决方案:参考3-1部分的设置
问题(2): with lock id [0]; maybe these locations are not writable or multiple nodes were started without increasing with lock id [1]?
解决方案:ps -ef|grep elasticsearch ,看是否有有运行的es 杀掉重启
问题(3):failed to join {bigdata01}{BTZDQpfGTcK0c-Dk0bQXWg}{OC39JXh_SKiUjN1BCsVXGg}{192.168.36.129}{192.168.36.129:9300} No route to host: 192.168.36.130/192.168.36.130:9300
解决方案:
防火墙没关掉,一般第一种就关掉了,如果不行再使用第二种
1、systemctl stop firewalld 先关闭本次的防火墙
systemctl disable firewalld 再设置每次启动时自动关闭防火墙
2、systemctl status iptables =查看防火墙状态
systemctl stop iptables = 关闭防火墙
systemctl status iptables = 查看防火墙状态是否关闭

















 1423
1423

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









