import torch
from d2l import torch as d2l
'''
#Relu函数实现
x = torch.arange(-8.0,8.0,0.1,requires_grad=True)
y = torch.relu(x)
d2l.plot(x.detach(),y.detach(),'x','relu(x)',figsize=(5,2.5))
d2l.plt.show()
#绘制ReLU函数的导数
y.backward(torch.ones_like(x),retain_graph=True)
d2l.plot(x.detach(),x.grad,'x','grad of relu',figsize=(5,2.5))
d2l.plt.show()
'''
'''
#sigmoid函数
x = torch.arange(-8.0,8.0,0.1,requires_grad=True)
y = torch.sigmoid(x)
d2l.plot(x.detach(),y.detach(),'x','sigmoid(x)',figsize=(5,2.5))
d2l.plt.show()
'''
''''''
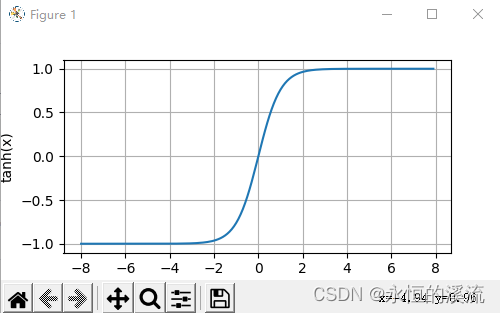
#tanh(双曲正切)函数
x = torch.arange(-8.0,8.0,0.1,requires_grad=True)
y = torch.tanh(x)
d2l.plot(x.detach(),y.detach(),'x','tanh(x)',figsize=(5,2.5))
d2l.plt.show()
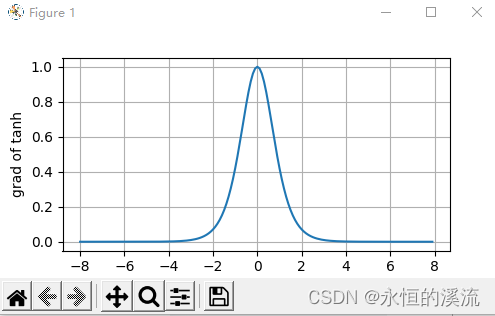
#清除以前的梯度
#x.grad.data.zero_()
y.backward(torch.ones_like(x),retain_graph=True)
d2l.plot(x.detach(),x.grad,'x','grad of tanh',figsize=(5,2.5))
d2l.plt.show()






















 1200
1200

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









