







接着caffe2 教程记录三,这个是第四篇
##4.Caffe2的主要概念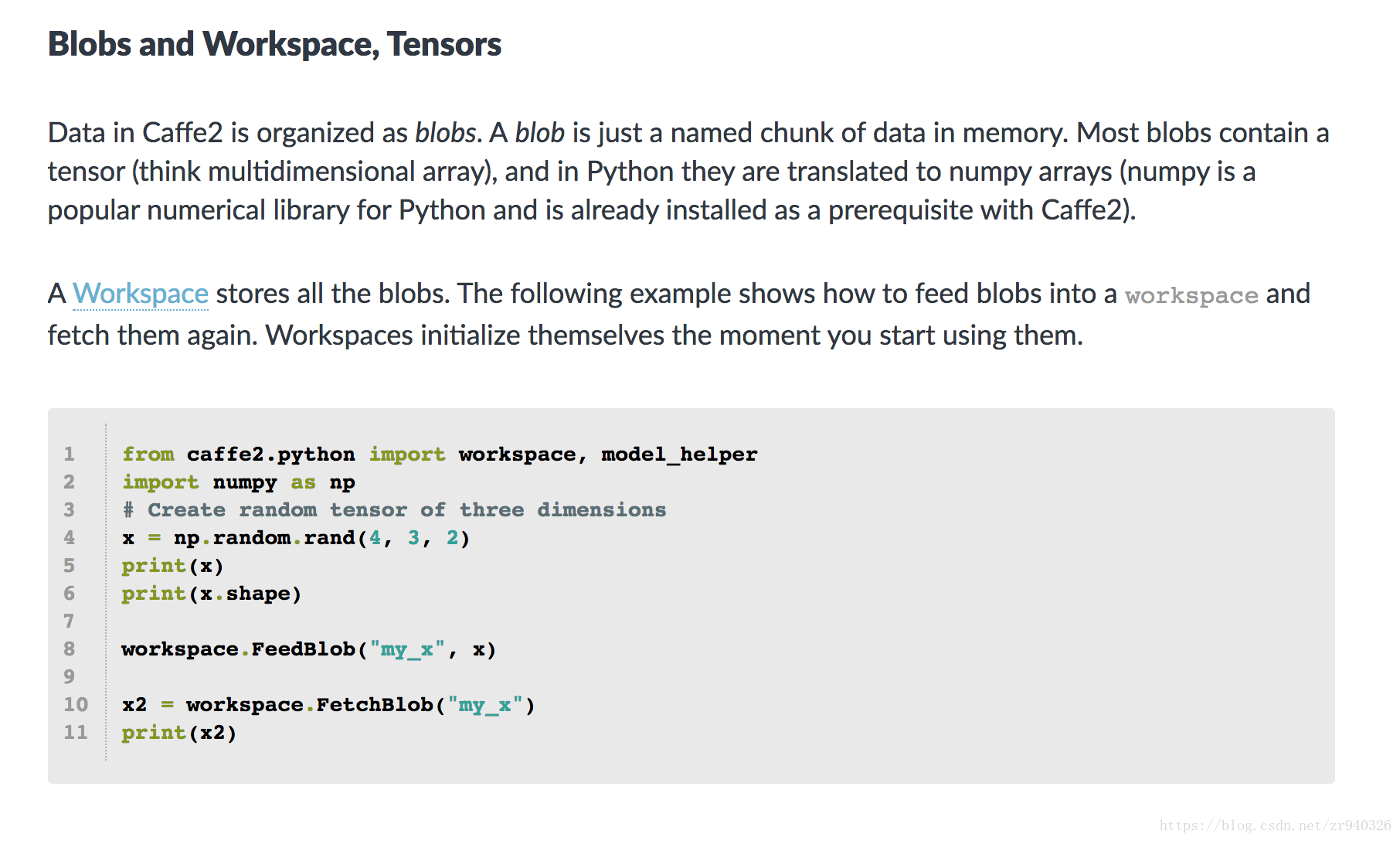 Blobs and Workspace, Tensors
Blobs and Workspace, Tensors
Caffe2中的数据被组织为blob。 blob只是内存中一个命名的数据块。 大多数blob包含一个张量(想想多维数组),在Python中它们被转换为numpy数组(numpy是一个流行的Python数值库,已经作为Caffe2的先决条件安装)。
Workspace(工作区)存储所有blob。 以下示例显示如何将Blob提供到workspace(工作空间)并再次获取它们。 Workspace(工作区)在您开始使用它们的那一刻初始化。
from caffe2.python import workspace, model_helper
import numpy as np
# Create random tensor of three dimensions
x = np.random.rand(4, 3, 2)
print(x)
print(x.shape)
workspace.FeedBlob("my_x", x)
x2 = workspace.FetchBlob("my_x")
print(x2)
Nets and Operators(网络和运算符):
Caffe2中的基本模型抽象是网络(简称 network)。 网络是运算符的图形,每个运算符采用一组输入blob并生成一个或多个输出blob。
在下面的代码块中,我们将创建一个超级简单的模型。 它将包含以下组件:
一个全连接层(FC)
用Softmax激活Sigmoid
交叉熵损失
直接编写网络非常繁琐,因此最好使用有助于创建网络的Python类 model helpers( 模型助手)。 即使我们调用它并传入单个名称“我的第一个网络”,ModelHelper也会创建两个相互关联的网络:
一个初始化参数(参考init_net)
一个运行实际训练的(参考exec_net)
# Create the input data
data = np.random.rand(16, 100).astype(np.float32)
# Create labels for the data as integers [0, 9].
label = (np.random.rand(16) * 10).astype(np.int32)
workspace.FeedBlob("data", data)
workspace.FeedBlob("label", label)我们创建了一些随机数据和随机标签,然后将它们作为blob提供给工作区
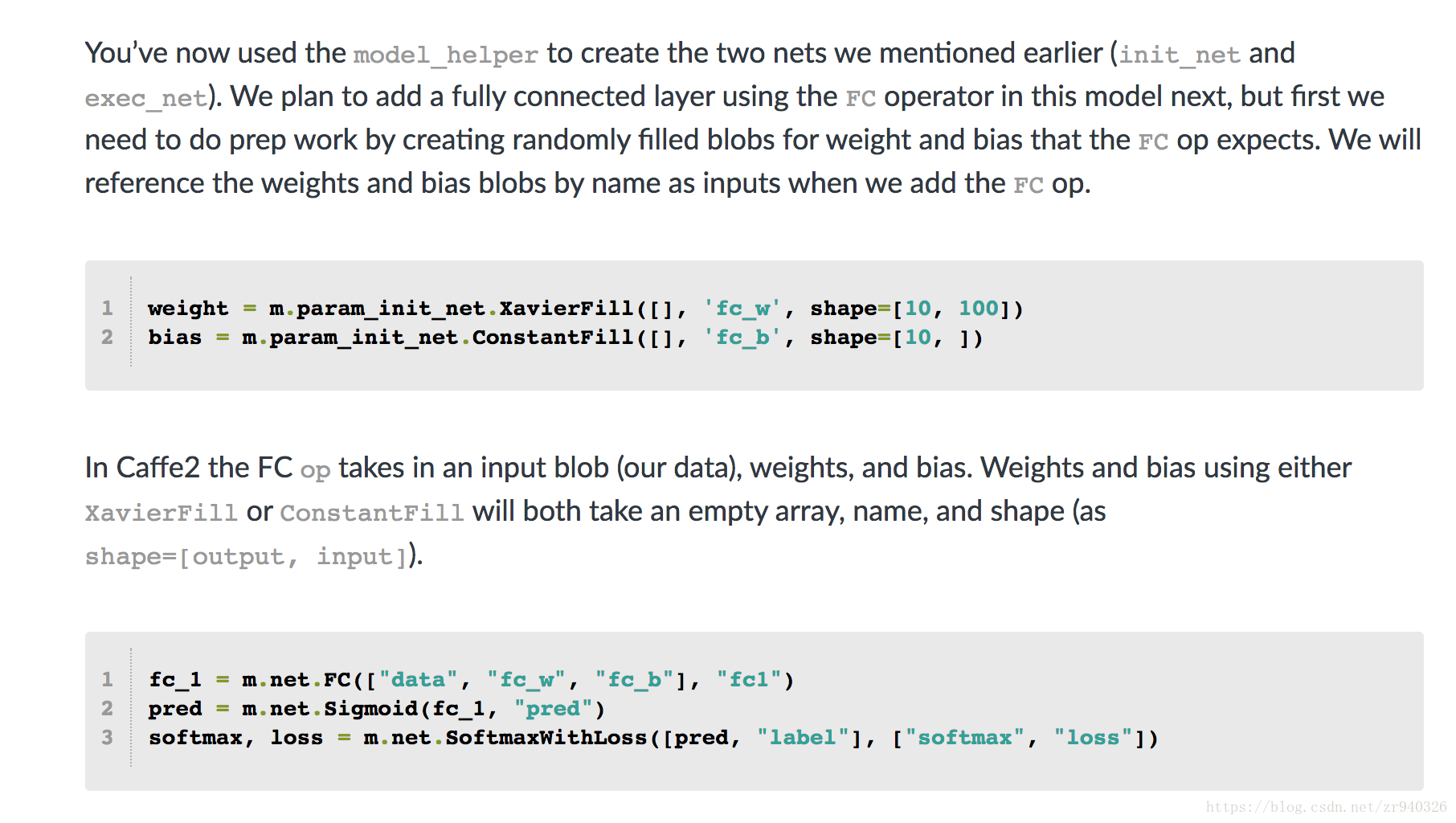
您现在已经使用model_helper创建了我们之前提到的两个网络(init_net和exec_net)。 我们计划在此模型中使用FC运算符添加完全连接的层,但首先我们需要通过创建随机填充的blob来进行准备工作,以获得FC op期望的权重和偏差。 当我们添加FC op时,我们将按名称引用权重和偏差blob作为输入。
weight = m.param_init_net.XavierFill([], 'fc_w', shape=[10, 100])
bias = m.param_init_net.ConstantFill([], 'fc_b', shape=[10, ])
在Caffe2中,FC op接收输入blob(我们的数据),权重和偏差。 使用XavierFill或ConstantFill的权重和偏差都将采用空数组,名称和形状(如shape = [output,input])。
fc_1 = m.net.FC(["data", "fc_w", "fc_b"], "fc1")
pred = m.net.Sigmoid(fc_1, "pred")
softmax, loss = m.net.SoftmaxWithLoss([pred, "label"], ["softmax", "loss"])
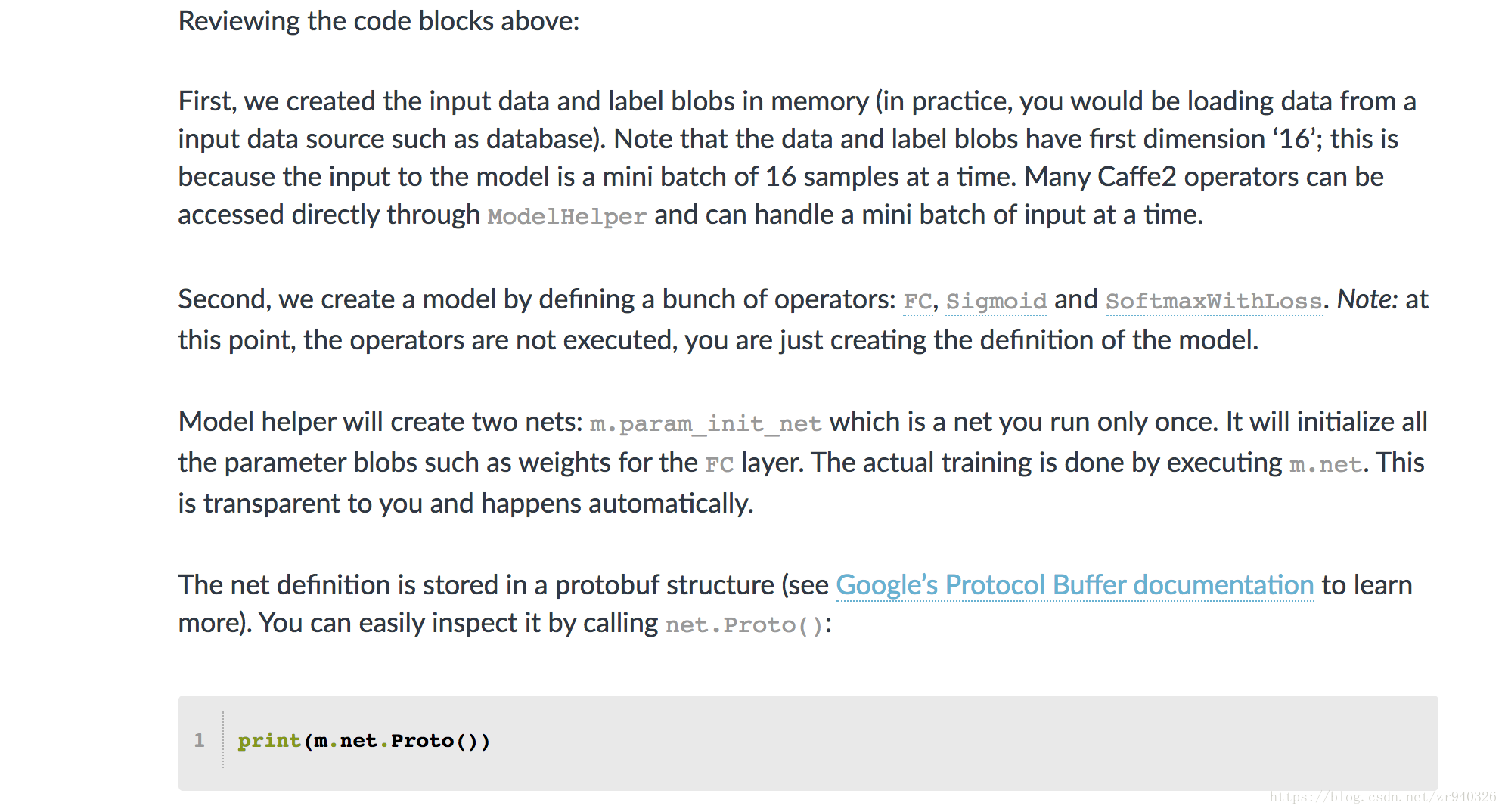
查看上面的代码块:
首先,我们在内存中创建了输入数据和标签blob(实际上,您将从输入数据源(如数据库)加载数据)。请注意,数据和标签blob的第一个维度为“16”;这是因为模型的输入是一次只有16个样本的小批量。许多Caffe2操作员可以通过ModelHelper直接访问,并且可以一次处理一小批输入。
其次,我们通过定义一组运算符来创建模型:FC,Sigmoid和SoftmaxWithLoss。注意:此时,运算符没有被执行,您只是创建模型的定义。
模型助手将创建两个网:m.param_init_net,这是一个只运行一次的网。它将初始化所有参数blob,例如FC层的权重。实际培训是通过执行m.net完成的。这对您来说是透明的,并且会自动发生。
网络定义存储在protobuf结构中(有关详细信息,请参阅Google的协议缓冲区文档 https://developers.google.com/protocol-buffers/)。您可以通过调用net.Proto()轻松检查它:
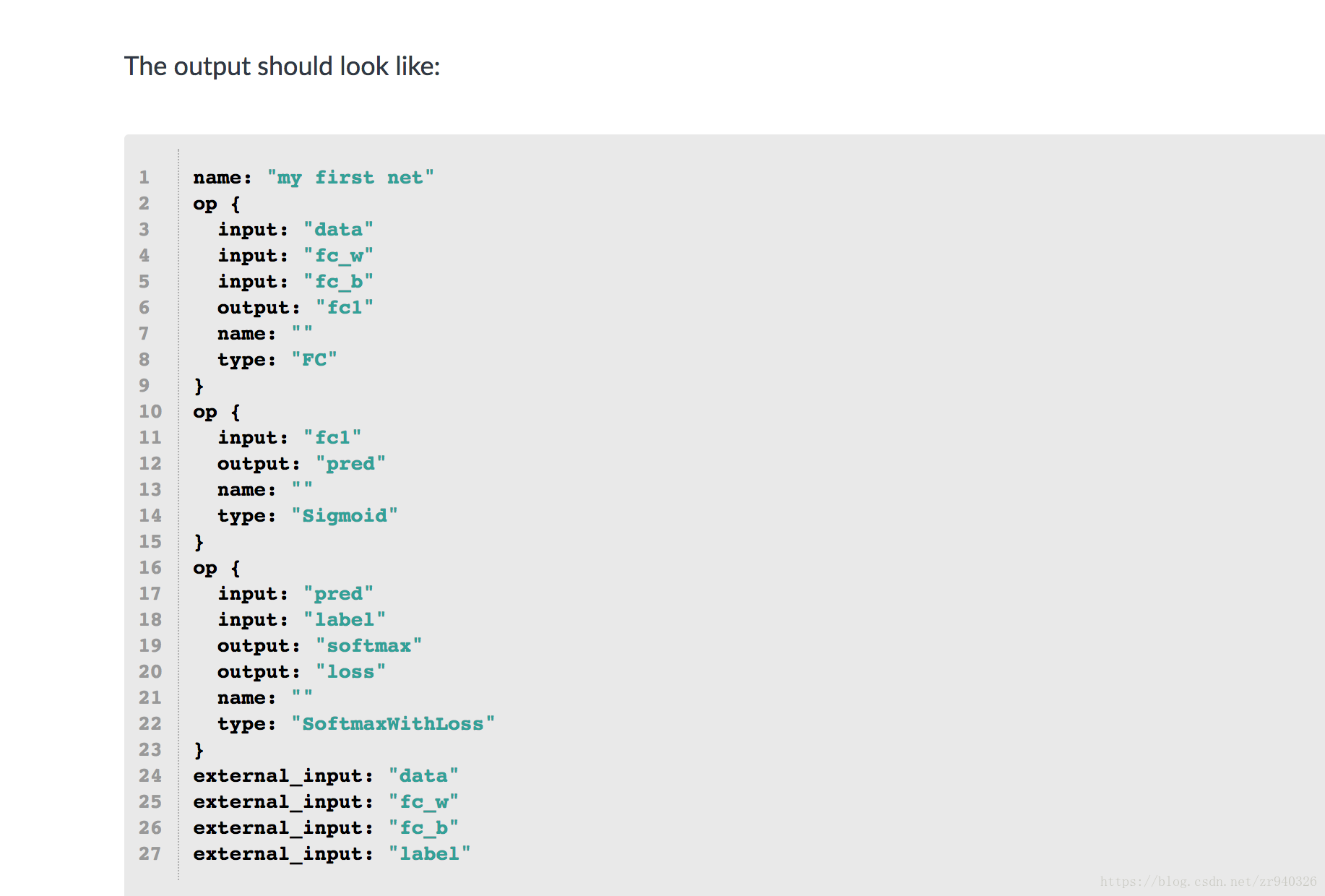
输出应如下所示:

你还应该看一下param初始化net
print(m.param_init_net.Proto())
您可以看到有两个运算符如何为FC运算符的权重和偏差blob创建随机填充。
这是Caffe2 API的主要思想:使用Python方便地组合网络来训练你的模型,将这些网络传递给C ++代码作为序列化的protobuffers,然后让C ++代码以完全的性能运行网络。
Executing
现在,当我们定义模型训练操作符时,我们可以开始运行它来训练我们的模型。
首先,我们只运行一次param初始化:
workspace.RunNetOnce(m.param_init_net)
请注意,像往常一样,这实际上会将param_init_net的protobuffer传递给C ++运行时以便执行。
然后我们创建实际的training Net:
workspace.CreateNet(m.net)

我们创建它一次,然后我们可以多次有效地运行它:
# Run 100 x 10 iterations
for _ in range(100):
data = np.random.rand(16, 100).astype(np.float32)
label = (np.random.rand(16) * 10).astype(np.int32)
workspace.FeedBlob("data", data)
workspace.FeedBlob("label", label)
workspace.RunNet(m.name, 10) # run for 10 times
注意我们如何将m.name而不是net定义本身传递给RunNet()。 由于网络是在工作空间内创建的,因此我们不需要再次传递定义。
执行后,您可以检查存储在输出blob(包含张量,即numpy数组)中的结果:
print(workspace.FetchBlob("softmax"))
print(workspace.FetchBlob("loss")) 
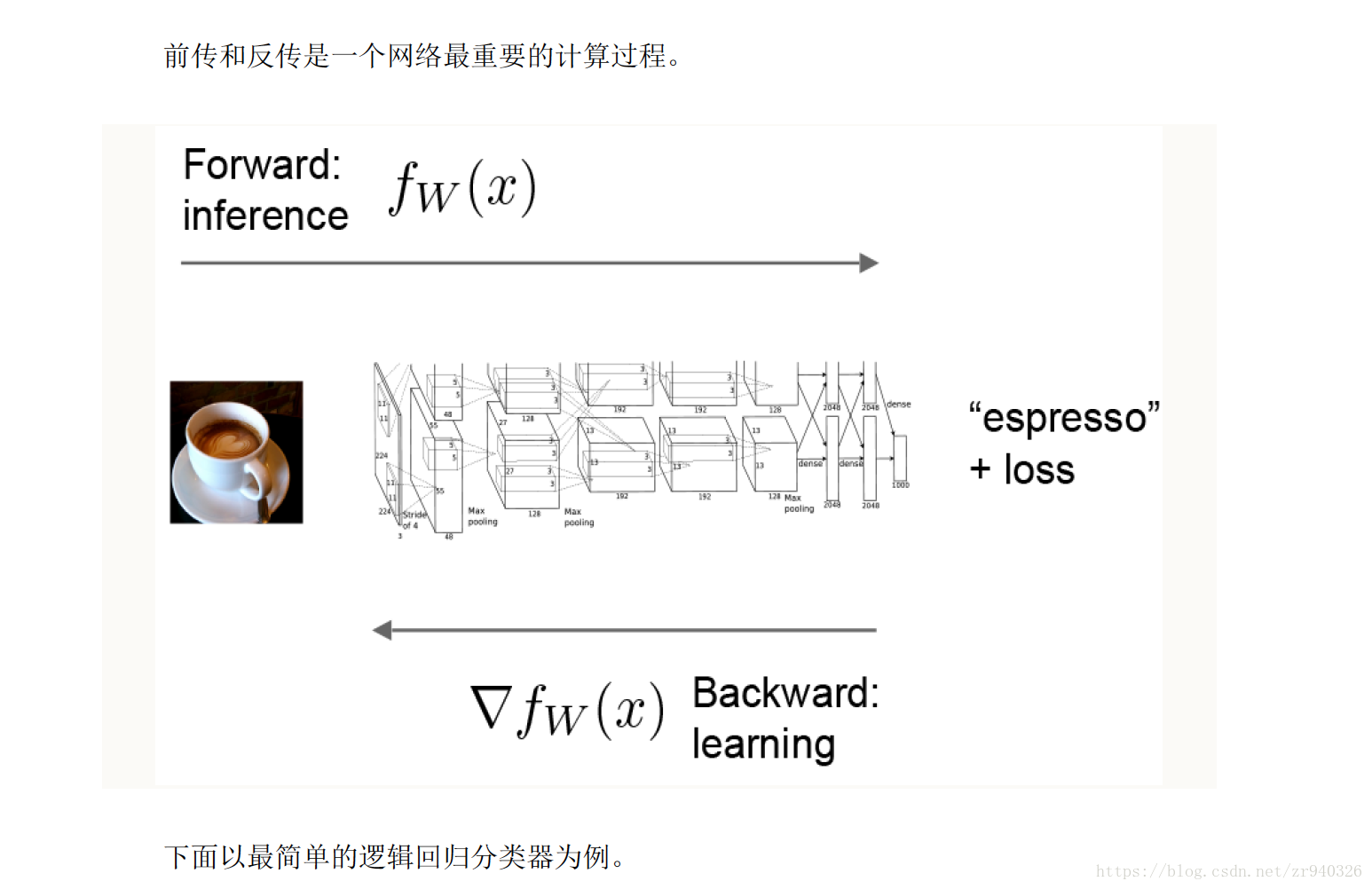
Backward pass:
这个网络只包含forward pass(前向传播),因此它不会学习任何东西。 通过在forward pass(前向传播)中为每个运算符添加梯度运算符来创建backward pass(反向传播)。
如果您想尝试此操作,请添加以下步骤并检查结果!
在调用RunNetOnce()之前插入:
m.AddGradientOperators([loss])
检查protobuf输出:
print(m.net.Proto())
概述总结结束了,但在教程中还有很多内容,请在tutorials 中进行查看。
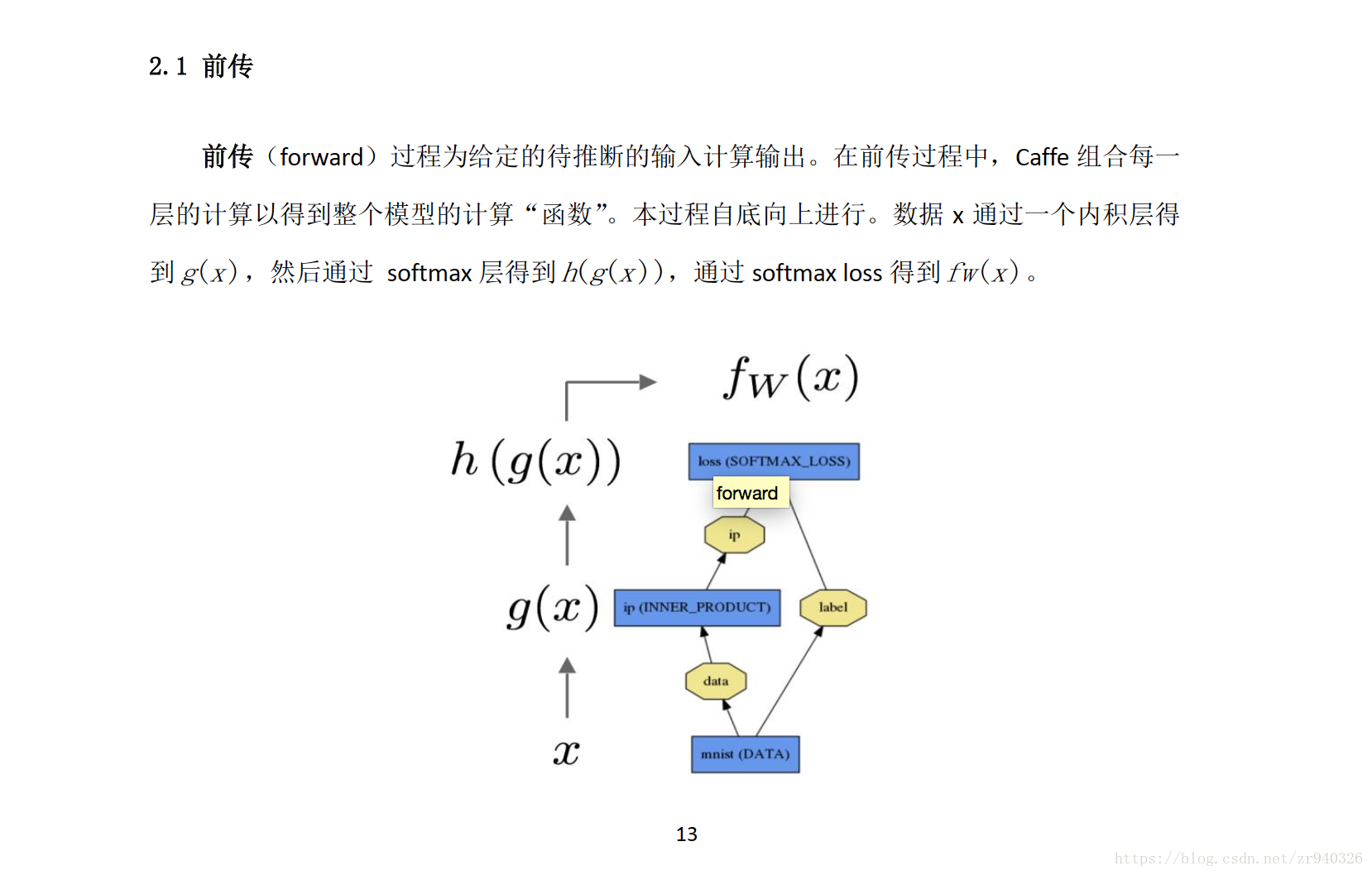
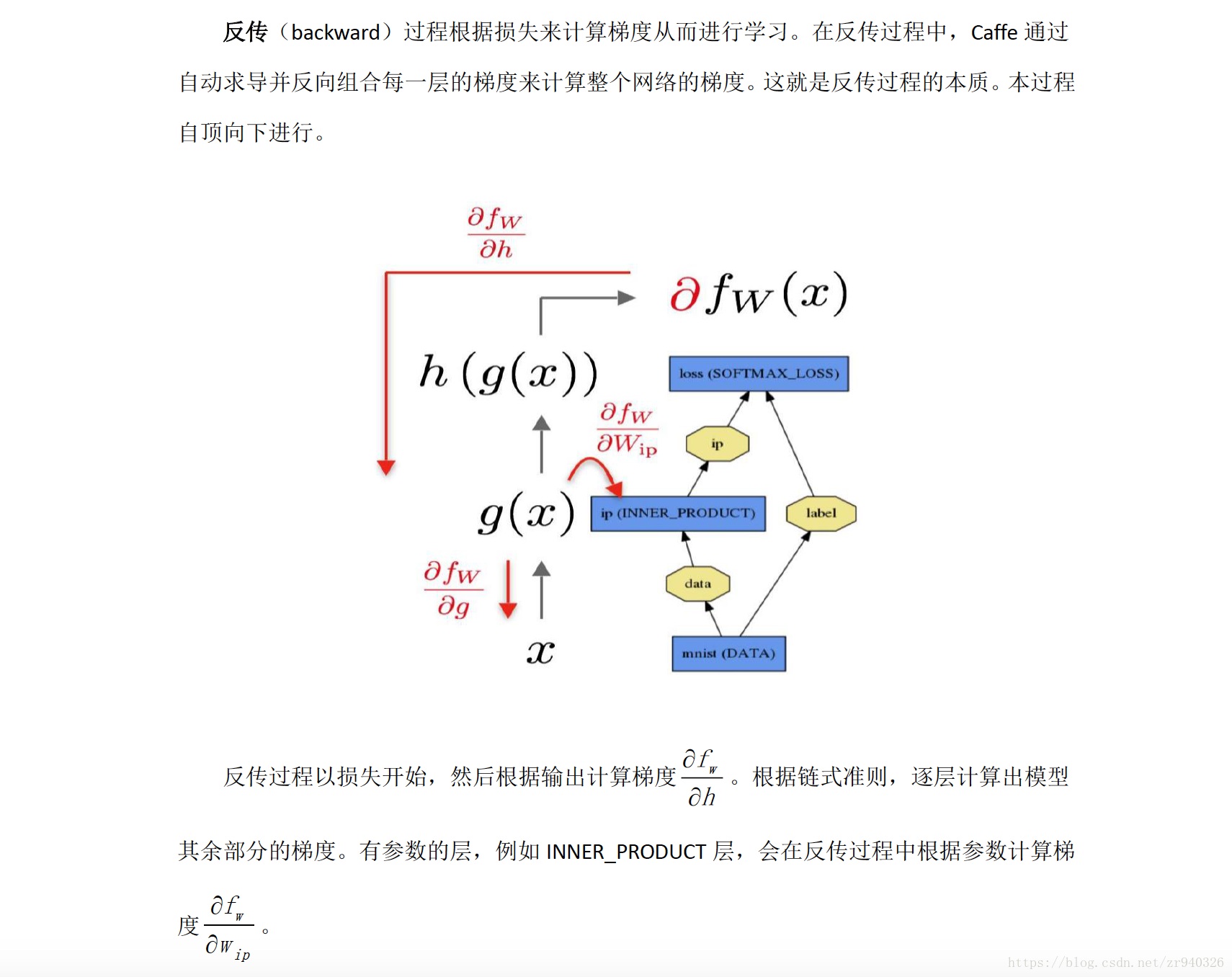
有关 Forward and Backward(前传/反传) 补充
(该内容 来自caffeCn深度学习社区,主要用于记录 )



















 2922
2922

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











